
kube-prometheus-stack
Presentación
kube-prometheus-stack utiliza Prometheus-operator y Prometheus para proporcionar capacidades de monitoreo de clúster de Kubernetes de extremo a extremo fáciles de usar.
Con este complemento, puede conectarse a Container Intelligent Analysis (CIA) para ver los datos de monitoreo y configurar alarmas.
Comunidad de código abierto: https://github.com/prometheus/prometheus
Restricciones
De forma predeterminada, el componente kube-state-metrics del complemento no recopila etiquetas ni anotaciones de recursos de Kubernetes. Para recopilar estas etiquetas y anotaciones, debe habilitar manualmente la función de recopilación en los parámetros de inicio y comprobar si las métricas correspondientes se agregan a la lista blanca de recopilación de ServiceMonitor denominada kube-state-metrics. Para obtener más información, véase Recopilación de todas las etiquetas y anotaciones de un pod.
Instalación del complemento
- Inicie sesión en la consola de CCE y acceda a la consola del clúster. Elija Add-ons en el panel de navegación, localice kube-prometheus-stack a la derecha y haga clic en Install.
- En la página Install Add-on, configure las especificaciones.
- Containers: instancia de componente creada por el complemento. Para obtener más información, véase Componentes. Puede seleccionar o personalizar una especificación según sea necesario.
- Configuración de los parámetros relacionados.
- Connect to Third Party: Para informar los datos de Prometheus a un sistema de monitoreo de terceros, debe introducir la dirección y el token del sistema de monitoreo de terceros y determinar si se omite la autenticación de certificado.
- Prometheus HA: Los componentes de Prometheus-server, Prometheus-operator, thanos-query, custom-metrics-apiserver y alertmanager se despliegan en modo de varias instancias en el clúster.
- Install Grafana: Use Grafana para visualizar los datos de monitoreo. Grafana crea un volumen de almacenamiento de 5 GiB por defecto. Desinstalar el complemento no eliminará este volumen. El nombre de usuario y la contraseña predeterminados para el primer inicio de sesión es admin. Se le pedirá que cambie la contraseña inmediatamente después de iniciar sesión.
- Collection Period: período de recogida de datos de seguimiento.
- Data Retention: período de conservación de los datos de seguimiento.
- Storage: seleccione el tipo y el tamaño del disco para almacenar los datos de supervisión. La desinstalación del complemento no eliminará este volumen.
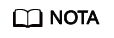
Existe un PVC disponible llamado pvc-prometheus-server en el espacio de nombres monitoring y se utilizará como fuente de almacenamiento.
- Haga clic en Install.
Adición de reglas de métrica personalizadas
El complemento kube-prometheus-stack de la nueva versión no proporciona métricas personalizadas. Es decir, las reglas de recopilación de métricas ya no se configuran en el ConfigMap de configuración de adaptador de usuario (adapter-config en versiones anteriores). Necesita agregar reglas de recopilación de métricas. Para obtener más información sobre cómo agregar reglas, consulte Descubrimiento de métricas y configuración de presentación. Si actualiza el complemento de una versión anterior a la nueva, las configuraciones originales se heredan y utilizan.

Para usar prometheus para monitorear las métricas personalizadas, la aplicación debe proporcionar una API de monitorización de métricas. Para obtener más información, véase Recopilación de datos de monitorización de Prometheus.
- Inicie sesión en la consola de CCE y acceda a la consola del clúster. En el panel de navegación, elija ConfigMaps and Secrets.
- Cambie al espacio de nombres monitoring, busque el ConfigMap user-adapter-config (adapter-config en las versiones anteriores) en la página de fichas ConfigMaps y haga clic en Update.

- En Data, haga clic en Edit para el archivo config.yaml para agregar una regla de recopilación de métricas personalizada bajo el campo rules. Haga clic en OK.
Puede agregar varias reglas de recopilación agregando varias configuraciones en el campo rules. Para obtener más información, consulte Descubrimiento de métricas y configuración de presentación.
Ejemplo de regla de métrica personalizada:rules: # The rule matches the accumulated cAdvisor metric in seconds. - seriesQuery: '{__name__=~"^container_.*",container!="POD",namespace!="",pod!=""}' resources: # Specify pod and namespace resources. overrides: namespace: resource: namespace pod: resource: pod name: # Delete the container_ prefix and _seconds_total suffix, and use the content captured in .* as the metric name. matches: "^container_(.*)_seconds_total$" # Query metrics. .Series and .LabelMatchers are available in the Go language. Use separators << and >> to avoid conflicts with the Prometheus query language. metricsQuery: 'sum(rate(<<.Series>>{<<.LabelMatchers>>,container!="POD"}[2m])) by (<<.GroupBy>>)' En el ejemplo anterior, solo se recopilan métricas básicas de pod. Para recopilar métricas personalizadas, consulta la guía oficial para agregar o modificar reglas.
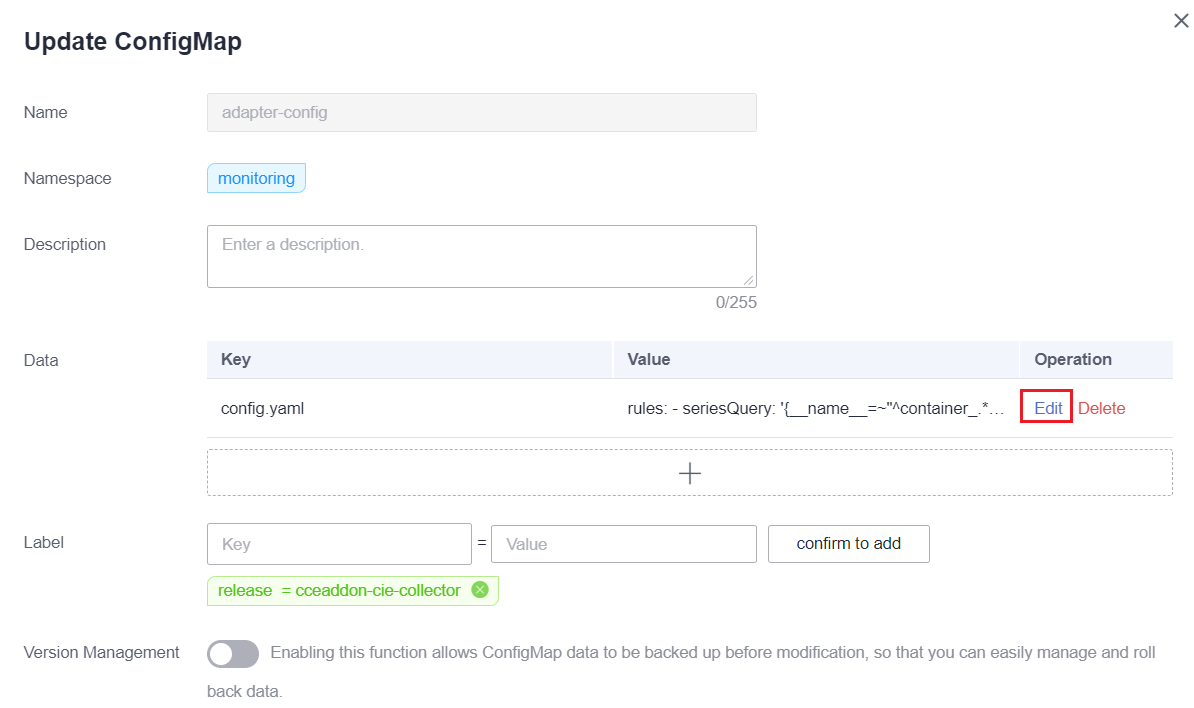
- Redistribuya la carga de trabajo custom-metrics-apiserver en el espacio de nombres monitoring.
Componentes
Todos los recursos de Kubernetes creados durante la instalación del complemento kube-prometheus-stack se crean en el espacio de nombres monitoring.
| Componente del contenedor | Descripción | Tipo de recurso |
|---|---|---|
| prometheusOperator (nombre de la carga de trabajo: prometheus-operator) | Despliega y gestiona el Prometheus Server basado en CRD (CustomResourceDefinitions), y monitorea y procesa los eventos relacionados con estos CRD. Es el centro de control de todo el sistema. | Deployment |
| prometheus (nombre de la carga de trabajo: prometheus-server) | Un clúster de Prometheus Server desplegado por el operador basado en los CRD de Prometheus que puede considerarse StatefulSets. | StatefulSet |
| alertmanager (nombre de la carga de trabajo: alertmanager-alertmanager) | Centro de alarma del complemento. Recibe alarmas enviadas por Prometheus y gestiona la información de alarmas deduplicando, agrupando y distribuyendo. | StatefulSet |
| thanosSidecar | Disponible solo en modo HA. Se ejecuta con prometheus-server en el mismo pod para implementar el almacenamiento persistente de datos métricos de Prometheus. | Container |
| thanosQuery | Disponible solo en modo HA. Entrada para la consulta de PromQL cuando Prometheus está en escenarios de HA. Puede eliminar métricas duplicadas de Store o Prometheus. | Deployment |
| adapter (nobre de carga de trabajo: custom-metrics-apiserver) | Agrega métricas personalizadas al servidor nativo de la API de Kubernetes. | Deployment |
| kubeStateMetrics (nombre de la carga de trabajo: kube-state-metrics) | Convierte los datos de métricas de Prometheus en un formato que las API de Kubernetes pueden identificar. De forma predeterminada, el componente kube-state-metrics no recopila todas las etiquetas y anotaciones de los recursos de Kubernetes. Para recopilar todas las etiquetas y anotaciones, consulte Recopilación de todas las etiquetas y anotaciones de un pod. | Deployment |
| nodeExporter (nombre de la carga de trabajo: node-exporter) | Se despliega en cada nodo para recopilar datos de monitoreo de nodo. | DaemonSet |
| grafana (nombre de la carga de trabajo: grafana) | Visualiza los datos de monitoreo. grafana crea un volumen de almacenamiento de 5 GiB por defecto. La desinstalación del complemento no eliminará este volumen. | Deployment |
| clusterProblemDetector (nombre de la carga de trabajo: cluster-problem-detector) | Supervisa las excepciones del clúster. | Deployment |
Acceso a Grafana
Si Grafana se instala durante la instalación del complemento, puede acceder al nodo a través del Service llamado grafana que es un Service de NodePort. Si se accede al nodo desde una red externa, puede vincular una EIP al nodo y acceder al nodo a través del puerto del nodo.
Como se muestra en la siguiente figura, la dirección de acceso es http://{{Node IP address}}:30913.

Recopilación de todas las etiquetas y anotaciones de un pod
- Inicie sesión en la consola de CCE y acceda a la consola del clúster. En el panel de navegación, elija Workloads.
- Cambie al espacio de nombres monitoring, busque la carga de trabajo kube-state-metrics en la página de ficha Deployments y haga clic en Upgrade en la columna Operation.
- En el área Lifecycle de la configuración del contenedor, edite el comando de inicio.
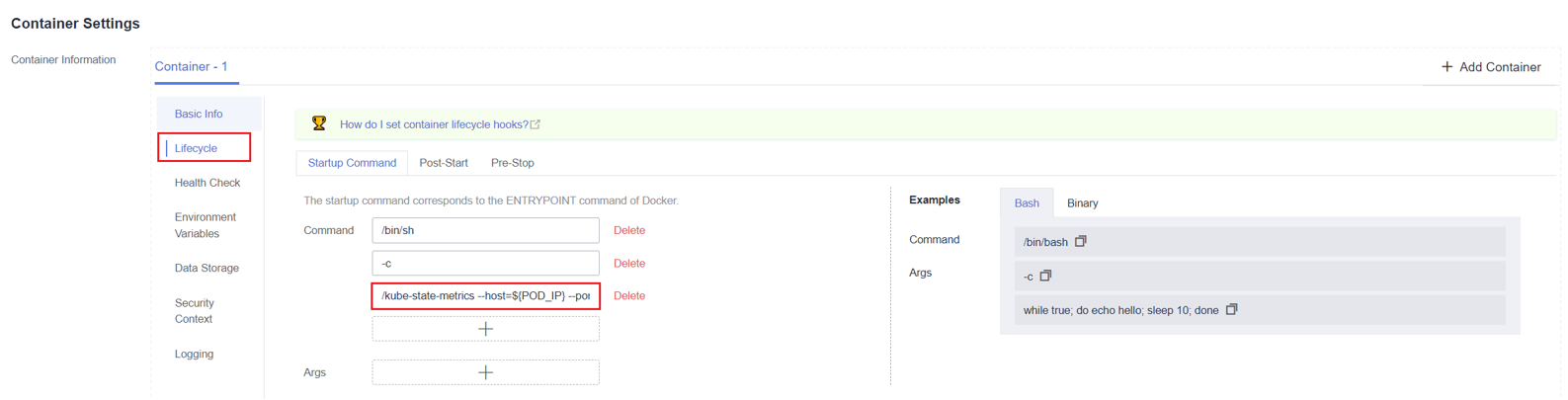 Agregue la siguiente información al final del parámetro original de inicio kube-state-metrics:
Agregue la siguiente información al final del parámetro original de inicio kube-state-metrics:--metric-labels-allowlist=pods=[*],nodes=[node,failure-domain.beta.kubernetes.io/zone,topology.kubernetes.io/zone]
Para recopilar anotaciones, agregue parámetros en los parámetros de inicio de la misma manera.--metric-annotations-allowlist=pods=[*],nodes=[node,failure-domain.beta.kubernetes.io/zone,topology.kubernetes.io/zone]
Al editar el comando de inicio, no modifique otros parámetros de inicio originales. De lo contrario, el componente puede ser anormal.
- kube-state-metrics comienza a recopilar las etiquetas/anotaciones de pods y nodos y comprueba si kube_pod_labels/kube_pod_annotations está en la tarea de recopilación de CloudScope.
kubectl get servicemonitor kube-state-metrics -nmonitoring -oyaml | kube_pod_labels
Para obtener más parámetros de inicio de kube-state-metrics, consulte kube-state-metrics/cli-arguments.
Proporcionar métricas de recursos
Las métricas de recursos de contenedores y nodos, como el uso de CPU y memoria, se pueden obtener con la API de métricas de Kubernetes. Se puede acceder directamente a las métricas de recursos, por ejemplo, mediante el comando kubectl top, o utilizar las políticas HPA o CustomedHPA personalizadas para el ajuste automático.
El complemento puede proporcionar la API de Kubernetes Metrics que está deshabilitada de forma predeterminada. Para habilitar la API, cree el siguiente objeto de APIService:
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
app: custom-metrics-apiserver
release: cceaddon-prometheus
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: custom-metrics-apiserver
namespace: monitoring
port: 443
version: v1beta1
versionPriority: 100 Puede guardar el objeto como un archivo, nombrarlo metrics-apiservice.yaml y ejecutar el siguiente comando:
kubectl create -f metrics-apiservice.yaml
Ejecute el comando kubectl top. Si se muestra la siguiente información, se puede acceder a la API de métricas:
# kubectl top pod -n monitoring NAME CPU(cores) MEMORY(bytes) ...... custom-metrics-apiserver-d4f556ff9-l2j2m 38m 44Mi ......
Para desinstalar el complemento, ejecute el siguiente comando kubectl y elimine el objeto APIService. De lo contrario, el complemento de metrics-server no se puede instalar debido a los recursos APIService residuales.
kubectl delete APIService v1beta1.metrics.k8s.io




