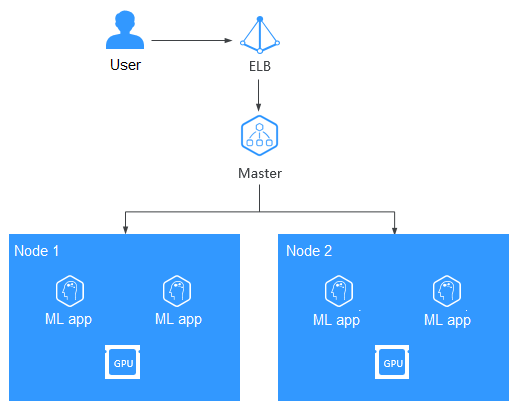
Programación de alto rendimiento
CCE integra Volcano para soportar cómputo de alto rendimiento.
Volcano es un sistema nativo de procesamiento por lotes de Kubernetes. Volcano proporciona una plataforma universal, escalable y estable para ejecutar trabajos de Big Data e IA. Es compatible con los marcos de cómputo generales para tareas de IA, big data, secuenciación de genes y renderizado. La excelencia de Volcano en la programación de tareas y la gestión de chips heterogéneos hace que el funcionamiento y la gestión de tareas sean más eficientes.
Escenario 1: Implementación híbrida de varios tipos de trabajos
Se desarrollan múltiples tipos de marcos de dominio para apoyar negocios en las diferentes industrias. Estos marcos, como Spark, TensorFlow y Flink, funcionan insustituiblemente en sus dominios de servicio. No trabajan solos, ya que los servicios y las empresas son cada vez más complejos. Sin embargo, la programación de recursos se convierte en un problema a medida que los clústeres en estos marcos crecen y un solo servicio puede tener cargas fluctuantes. Por lo tanto, un sistema de planificación unificado tiene una gran demanda.
Volcano resume una capa básica común para el cómputo por lotes basado en Kubernetes. Complementa Kubernetes en la programación y proporciona abstracciones de trabajo flexibles y universales para marcos de cómputo. Estas abstracciones (trabajos de Volcano) se implementan a través de plantillas multitarea para describir varios tipos de trabajos (como TensorFlow, Spark, MPI, y PyTorch). Los diferentes tipos de trabajos se pueden ejecutar juntos, y Volcano utiliza su sistema de programación unificada para realizar el uso compartido de recursos del clúster.
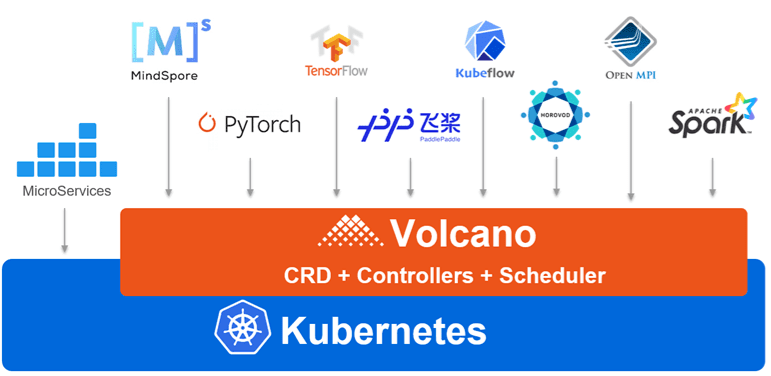
Escenario de aplicación 2: Optimización de programación en los escenarios de varias colas
El aislamiento y el uso compartido de recursos a menudo se requieren cuando se utiliza un clúster de Kubernetes. Sin embargo, Kubernetes no admite colas. No puede compartir recursos cuando varios usuarios o departamentos comparten una máquina. Sin el uso compartido de recursos basado en colas, los trabajos de HPC y big data no se pueden ejecutar.
Volcano soporta múltiples mecanismos de intercambio de recursos con colas. Puede establecer weight de una cola. El clúster asigna recursos a la cola calculando la relación entre el peso de la cola y el peso total de todas las colas. También puede establecer capability de recursos de una cola para determinar el límite superior de recursos que puede utilizar la cola.
Por ejemplo, en la siguiente figura, la cola 1 se asigna el 40% de los recursos del clúster y el 60% para la cola 2. De esta manera, se pueden asignar dos colas a diferentes departamentos o proyectos para usar recursos en el mismo clúster. Si una cola tiene recursos inactivos, se pueden asignar a trabajos de otra cola.

Escenario de la aplicación 3: Múltiples políticas avanzadas de programación
Los contenedores se programan en nodos que satisfacen sus requisitos en recursos de cómputo, como CPU, memoria y GPU. Normalmente, habrá más de un nodo calificado. Cada uno podría tener un volumen diferente de recursos disponibles para nuevas cargas de trabajo. Volcano analiza automáticamente la utilización de recursos de cada plan de programación y lo ayuda a lograr los resultados óptimos de implementación con gran facilidad.
La siguiente figura muestra cómo el planificador de Volcano programa los recursos. En primer lugar, el planificador carga la información de pod y PodGroup en el servidor API en la caché del planificador. En una sesión de programación, Volcano pasa por tres fases: "OpenSession", llamada de acción y "CloseSession". En OpenSession se carga la política de programación que configuraste en el complemento del planificador. Durante la llamada de acción, las acciones configuradas se llaman una por una y se utiliza la política de programación cargada. En CloseSession se realizan las operaciones finales para completar la programación.
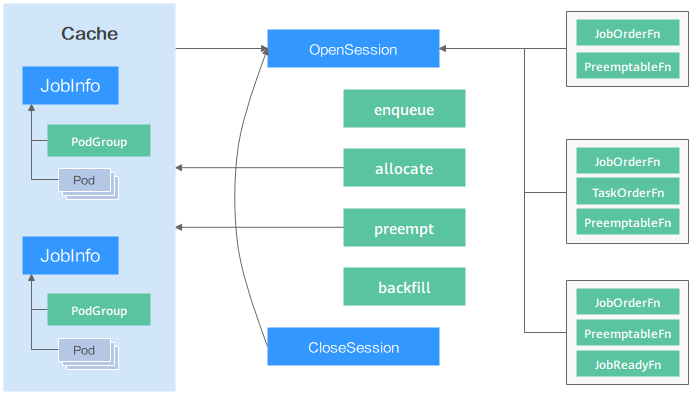
El planificador de Volcano proporciona plugins para soportar múltiples acciones de programación (como enqueue, allocate, preempt, reclaim y backfill) y políticas de programación (como gang, priority, drf, proportion y binpack). Puede configurarlos según sea necesario. Las API proporcionadas por el planificador también se pueden utilizar para el desarrollo personalizado.
Escenario de aplicación 4: Programación de recursos de alta precisión
Volcano proporciona políticas de programación de recursos de alta precisión para trabajos de inteligencia artificial y big data para mejorar la eficiencia informática. Tomemos a TensorFlow como ejemplo. Configure la afinidad entre ps y trabajador y la antiafinidad entre ps y ps, de modo que ps y trabajador al mismo nodo. Esto mejora el rendimiento de la red y la interacción de datos entre ps y el trabajador, mejorando así la eficiencia informática. Sin embargo, al programar pods, el planificador predeterminado de Kubernetes solo comprueba si las configuraciones de afinidad y antiafinidad de estos pods entran en conflicto con las de todos los pods en ejecución en el clúster y no tiene en cuenta los pods posteriores que también necesiten programación.
El algoritmo de topología de tareas proporcionado por Volcano calcula las prioridades de tareas y nodos en función de las configuraciones de afinidad y antiafinidad entre tareas en un trabajo. Las políticas de afinidad y antiafinidad de tareas en un trabajo y el algoritmo de topología de tareas garantizan que las tareas con configuraciones de afinidad se planifiquen preferentemente para el mismo nodo. y los pods con configuraciones antiafinidad están programados para los diferentes nodos. La diferencia entre el algoritmo de topología de tareas y el planificador predeterminado de Kubernetes es que el algoritmo de topología de tareas considera que los pods se programarán como un todo. Cuando los pods se programan por lotes, los ajustes de afinidad y antiafinidad entre los pods no programados se consideran y se aplican a los procesos de programación de pods en función de las prioridades.
Beneficios
La ejecución de contenedores en servidores en la nube acelerados por GPU de alto rendimiento mejora significativamente el rendimiento informático de IA de tres a cinco veces. Las GPU pueden costar mucho y compartir una GPU entre contenedores reduce en gran medida los costos de cómputo de IA. Además de las ventajas de rendimiento y costos, CCE también ofrece clústeres totalmente administrados que ocultarán toda la complejidad en la implementación y gestión de sus aplicaciones de IA para que pueda centrarse en el desarrollo de alto valor.
Ventajas
Al integrar Volcano, CCE tiene las siguientes ventajas en la ejecución de trabajos de cómputo de alto rendimiento, big data e inteligencia artificial:
- Implementación híbrida de trabajos de HPC, big data e IA
- Programación optimizada de múltiples colas: se pueden utilizar varias colas para compartir recursos con varios tenants y planificar grupos en función de prioridades y períodos de tiempo.
- Políticas de programación avanzadas: programación de grupos, programación justa, preferencia de recursos y topología de GPU
- Plantilla multitarea: Puede utilizar una plantilla para definir varias tareas en un solo trabajo de volcán, más allá del límite de los recursos nativos de Kubernetes. Volcano Jobs puede describir varios tipos de trabajo, como TensorFlow, MPI y PyTorch.
- Plugins de extensión de trabajo: El Volcano Controller le permite configurar plugins para personalizar la preparación y limpieza del entorno en etapas como el envío de trabajos y la creación de pods. Por ejemplo, antes de enviar un trabajo MPI común, puede configurar el complemento SSH para proporcionar la información SSH de los recursos de pod.
Servicios relacionados
GPU-accelerated Cloud Server (GACS), Elastic Load Balance (ELB), y Object Storage Service (OBS)