
Resumen de monitoreo
CCE trabaja con AOM para monitorear de forma integral los clústeres. Cuando se crea un nodo, el ICAgent (el DaemonSet llamado icagent en el espacio de nombres del kube-system del clúster) de AOM está instalado de forma predeterminada. ICAgent recopila datos de supervisión de los recursos y cargas de trabajo subyacentes que se ejecutan en el clúster. También recopila datos de monitoreo de métricas personalizadas de la carga de trabajo.
- Métricas de recursos
El monitoreo básico de recursos incluye monitoreo a CPU, a memoria y a disco. Para obtener más información, véase Métricas de recursos. Puede ver estas métricas de clústeres, nodos y cargas de trabajo en la consola de CCE o de AOM.
- Métricas personalizadas
El ICAgent recopila métricas personalizadas de aplicaciones y las carga en AOM. Para obtener más información, véase Supervisión de métricas personalizadas en AOM.
- Monitorización de NPD
node-problem-detector (npd para abreviar) es un complemento que monitorea e informa sobre el estado de un nodo. Se puede conectar a una plataforma de monitoreo de terceros. Es un demonio que se ejecuta en cada nodo. Recopila problemas de nodos de diferentes demonios y los informa al servidor de API. El complemento npd puede ejecutarse como un demonio o un DaemonSet.
CCE mejora npd en la versión 1.16.0, que ahora admite comprobaciones de recursos de nodo, componentes y eventos, así como aislamiento de fallas. Para obtener más información, véase npd.
Además, puede instalar el complemento de Prometheus en un clúster y usar Prometheus para recopilar y mostrar datos de supervisión. Para obtener más información, véase Monitoreo de métricas personalizadas con prometheus.
Métricas de recursos
En la consola de CCE, puede ver las siguientes métricas.
| Métrica | Descripción |
|---|---|
| CPU Allocation Rate | Indica el porcentaje de CPUs asignadas a cargas de trabajo. |
| Memory Allocation Rate | Indica el porcentaje de memoria asignada a las cargas de trabajo. |
| CPU Usage | Indica la utilización del CPU. |
| Memory Usage | Indica el uso de la memoria. |
| Disk Usage | Indica el uso del disco. |
| Down | Indica la velocidad a la que se descargan los datos en un nodo. La unidad es KB/s. |
| Up | Indica la velocidad a la que se cargan los datos desde un nodo. La unidad es KB/s. |
| Disk Read Rate | Indica el volumen de datos leído de un disco por segundo. La unidad es KB/s. |
| Disk Write Rate | Indica el volumen de datos escrito en un disco por segundo. La unidad es KB/s. |
En la consola de AOM, puede ver las métricas del host y las métricas de contenedor. Para obtener más información, consulte Descripción de métrica.
Consulta de datos de supervisión de clústeres
Haga clic en el nombre del clúster y acceda a la consola del clúster. En el panel de navegación, elija Cluster Information. En el panel derecho, puede ver el uso de CPU y memoria de todos los nodos (excepto los nodos maestros) del clúster en la última hora.
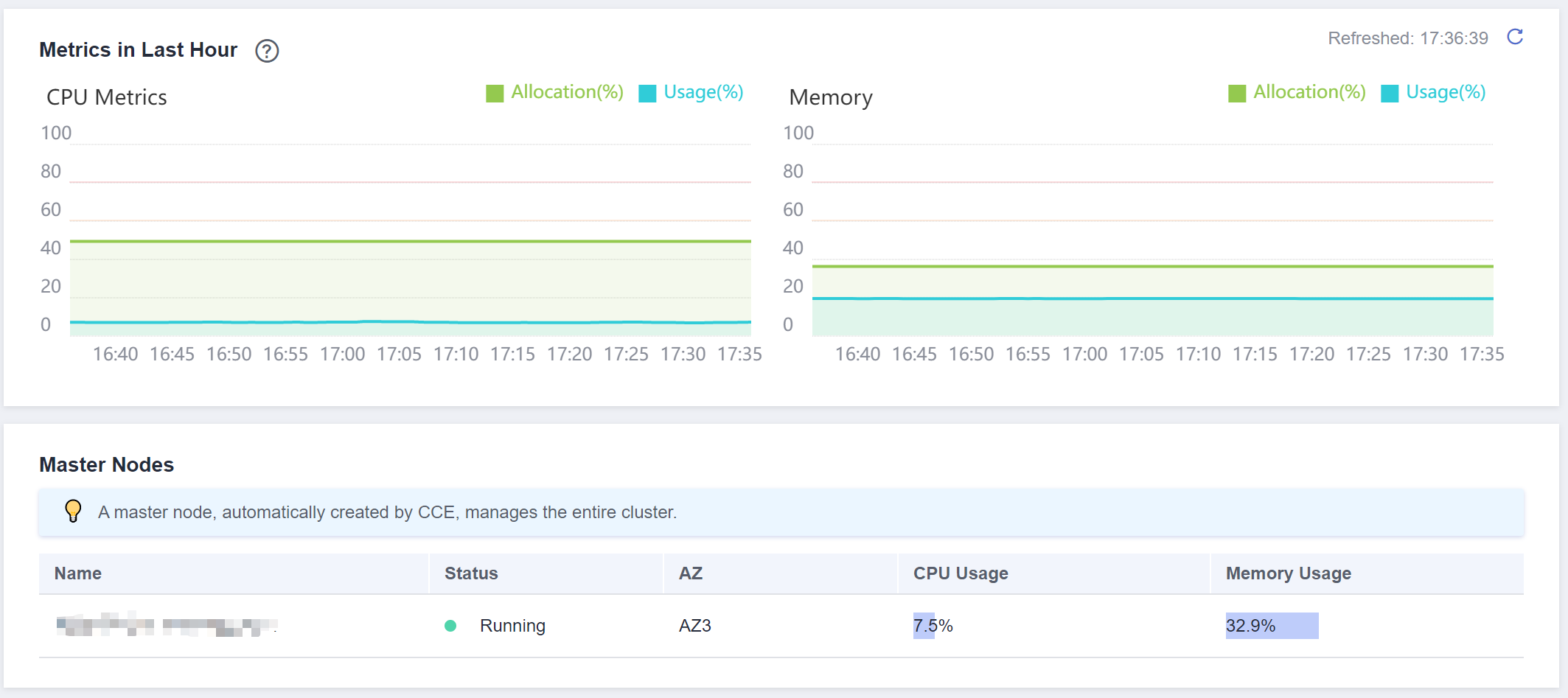
Explicación de las métricas de monitorización:
- Tasa de asignación de CPU = Suma de cuotas de CPU solicitadas por los pods en el clúster/Suma de cuotas de CPU que se pueden asignar a todos los nodos (excepto los nodos maestros) en el clúster
- Tasa de asignación de memoria = Suma de cuotas de memoria solicitadas por los pods en el clúster/Suma de cuotas de memoria que se pueden asignar a todos los nodos (excepto los nodos maestros) en el clúster
- Uso de CPU: Uso promedio de CPU de todos los nodos (excepto los nodos maestros) en un clúster
- Uso de memoria: Uso medio de memoria de todos los nodos (excepto los nodos maestros) en un clúster
Recursos de nodo asignables (CPU o memoria) = Importe total - Importe reservado - Umbrales de desalojo. Para obtener más información, véase Descripción de los recursos de nodos reservados.
CCE proporciona el estado, la zona de disponibilidad (AZ), el uso de CPU y el uso de memoria de los nodos maestros.
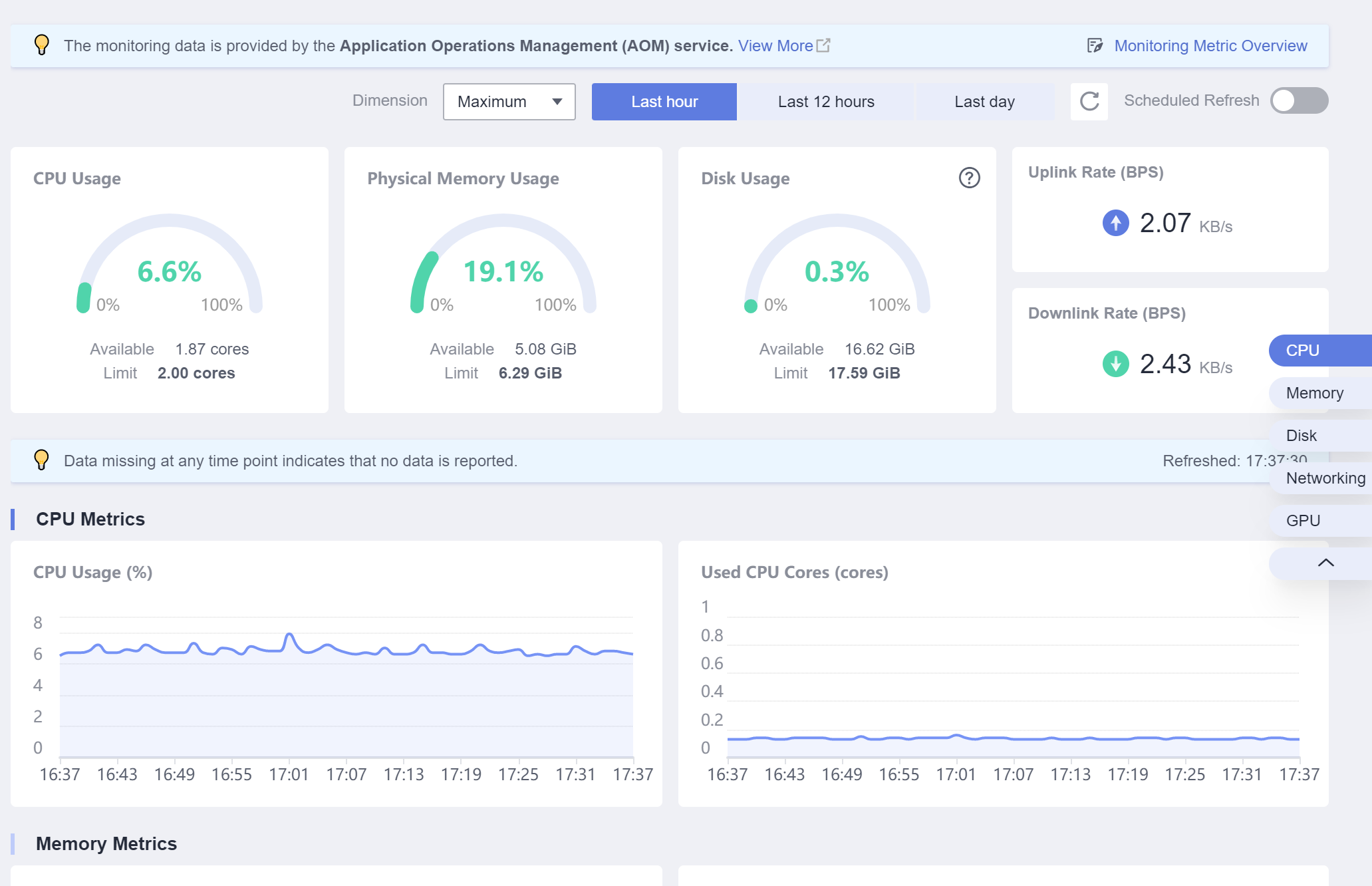
Consulta de datos de supervisión de nodos de trabajo
Además de ver los datos de supervisión de todos los nodos, también puede ver los datos de supervisión de un solo nodo. Haga clic en el nombre del clúster y acceda a la consola del clúster. Elija Nodes en el panel de navegación y haga clic en Monitor en la columna Operation del nodo de destino.
Los datos de monitoreo provienen de AOM. Puede ver los datos de supervisión de un nodo, incluidos la CPU, la memoria, el disco, la red y la GPU.
Consulta de datos de supervisión de carga de trabajo
Puede ver los datos de supervisión de una carga de trabajo en la página de ficha Monitoring de la página de detalles de la carga de trabajo. Haga clic en el nombre del clúster y acceda a la consola del clúster. Elija Workloads en el panel de navegación y haga clic en Monitor en la columna Operation de la carga de trabajo de destino.
Los datos de monitoreo provienen de AOM. Puede ver los datos de supervisión de una carga de trabajo, incluida la CPU, la memoria, la red y la GPU, en la consola de la unidad de procesamiento.
- Carga de trabajo Uso de CPU = Uso máximo de CPU en cada pod de la carga de trabajo
- Uso de memoria de carga de trabajo = Uso máximo de memoria en cada pod de la carga de trabajo
También puede hacer clic en View More para ir a la consola de AOM y ver los datos de supervisión de la carga de trabajo.
Consulta de datos de supervisión de pod
Puede ver los datos de supervisión de un pod en la página de ficha Pods de la página de detalles de la carga de trabajo.
- Uso de CPU de pod = Los núcleos de CPU usados/La suma de todos los límites de CPU de los pods (Si no se especifica, se usan todos los núcleos de CPU de nodo.)
- Uso de memoria de pod = La memoria física usada/La suma de todos los límites de memoria de pods (Si no se especifica, se usa toda la memoria de nodo.)




