
npd
Presentación
node-problem-detector (npd para abreviar) es un complemento que monitorea eventos anormales de nodos de clúster y se conecta a una plataforma de monitoreo de terceros. Es un demonio que se ejecuta en cada nodo. Recopila problemas de nodos de diferentes demonios y los informa al servidor de API. El complemento npd puede ejecutarse como un demonio o un DaemonSet.
Para obtener más información, consulte node-problem-detector.
Notas y restricciones
- Cuando utilice este complemento, no formatee ni particione los discos de nodo.
- Cada proceso de npd ocupa 30 mCPU y 100 MB de memoria.
Descripción del permiso
Para monitorear los logs del núcleo, el complemento de npd necesita leer el host /dev/kmsg. Por lo tanto, el modo privilegiado debe estar habilitado. Para más detalles, consulte Privilegiado.
Además, CCE mitiga los riesgos de acuerdo con el principio de privilegio mínimo. Solo están disponibles los siguientes privilegios para la ejecución de npd:
- cap_dac_read_search: permiso para acceder a /run/log/journal.
- cap_sys_admin: permiso para acceder a /dev/kmsg.
Instalación del complemento
- Inicie sesión en la consola de CCE y acceda a la consola del clúster. Elija Add-ons en el panel de navegación, localice npd a la derecha y haga clic en Install.
- En la página Install Add-on, seleccione las especificaciones del complemento y establezca los parámetros relacionados.
- Pods: Establezca el número de pods en función de los requisitos de servicio.
- Containers: Seleccione una cuota de contenedor adecuada en función de los requisitos de servicio.
- Establezca los parámetros de npd y haga clic en Install.
Los parámetros son configurables solo en 1.16.0 y versiones posteriores. Para obtener más información, véase Tabla 7.
Conceptos de comprobación de npd
Los conceptos de comprobación solo se admiten en 1.16.0 y versiones posteriores.
Compruebe los conceptos cubren eventos y estados.
- Relacionado con eventos
Para los elementos de comprobación relacionados con eventos, cuando se produce un problema, npd informa de un evento al servidor de API. El tipo de evento puede ser Normal (evento normal) o Warning (evento anormal).
Tabla 1 Conceptos de comprobación relacionados con eventos Concepto de comprobación
Función
Descripción
OOMKilling
Escuche los logs del núcleo y compruebe si ocurren eventos de OOM y si se informan.
Escenario típico: cuando el uso de memoria de un proceso en un contenedor excede el límite, OOM se activa y el proceso se termina.
Evento de advertencia
Objeto de escucha: /dev/kmsg
Regla de coincidencia: "Killed process \\d+ (.+) total-vm:\\d+kB, anon-rss:\\d+kB, file-rss:\\d+kB.*"
TaskHung
Escuche los logs del núcleo y verifique si se producen y se informan los eventos de taskHung.
Escenario típico: La suspensión de E/S de disco provoca la suspensión del proceso.
Evento de advertencia
Objeto de escucha: /dev/kmsg
Regla de coincidencia: "task \\S+:\\w+ blocked for more than \\w+ seconds\\."
ReadonlyFilesystem
Compruebe si el error Remount root filesystem read-only ocurre en el kernel del sistema escuchando los logs del kernel.
Escenario típico: Un usuario separa un disco de datos de un nodo por error en el ECS y las aplicaciones escriben datos continuamente en el punto de montaje del disco de datos. Como resultado, se produce un error de E/S en el núcleo y el disco se vuelve a montar como un disco de solo lectura.
Evento de advertencia
Objeto de escucha: /dev/kmsg
Regla de coincidencia: Remounting filesystem read-only
- Relacionado con el estado
Para los elementos de comprobación relacionados con el estado, cuando se produce un problema, npd informa de un evento al servidor API y cambia el estado del nodo de forma síncrona. Esta función se puede utilizar junto con el aislamiento de fallas del node-problem-controller para aislar nodos.
Si el período de comprobación no se especifica en los siguientes elementos de comprobación, el período predeterminado es de 30 segundos.
Tabla 3 Comprobación de métricas del sistema Concepto de comprobación
Función
Descripción
Tabla de conntrack llena
ConntrackFullProblem
Compruebe si la tabla de conntrack está llena.
- Umbral predeterminado: 90%
- Uso: nf_conntrack_count
- Valor máximo: nf_conntrack_max
Recursos de disco insuficientes
DiskProblem
Compruebe el uso del disco del sistema y los discos de datos de CCE (incluidos el disco lógico CRI y el disco lógico kubelet) en el nodo.
- Umbral predeterminado: 90%
- Fuente:
df -h
Actualmente, no se admiten discos de datos adicionales.
Controladores de archivo insuficientes
FDProblem
Compruebe si los controladores de archivo de FD están agotados.
- Umbral predeterminado: 90%
- Uso: el primer valor de /proc/sys/fs/file-nr
- Valor máximo: el tercer valor de /proc/sys/fs/file-nr
Memoria de nodo insuficiente
MemoryProblem
Compruebe si la memoria está agotada.
- Umbral predeterminado: 80%
- Uso: MemTotal-MemAvailable en /proc/meminfo
- Valor máximo: MemTotal en /proc/meminfo
Recursos de proceso insuficientes
PIDProblem
Compruebe si los recursos del proceso PID están agotados.
- Umbral predeterminado: 90%
- Uso: nr_threads in /proc/loadavg
- Valor máximo: valor menor entre /proc/sys/kernel/pid_max y /proc/sys/kernel/threads-max.
Tabla 4 Comprobación del almacenamiento Concepto de comprobación
Función
Descripción
Disco de solo lectura
DiskReadonly
Realizar periódicamente pruebas de lectura y escritura en el disco del sistema y los discos de datos de CCE (incluidos el disco lógico de CRI y el disco lógico de Kubelet) del nodo para comprobar la disponibilidad de los discos clave.
Rutas de detección:
- /mnt/paas/kubernetes/kubelet/
- /var/lib/docker/
- /var/lib/containerd/
- /var/paas/sys/log/cceaddon-npd/
El archivo temporal npd-disk-write-ping se genera en la ruta de detección.
Actualmente, no se admiten discos de datos adicionales.
Recursos de disco insuficientes
DiskProblem
Compruebe el uso del disco del sistema y los discos de datos de CCE (incluidos el disco lógico CRI y el disco lógico kubelet) en el nodo.
- Umbral predeterminado: 90%
- Fuente:
df -h
Actualmente, no se admiten discos de datos adicionales.
Error de grupo de almacenamiento de emptyDir
EmptyDirVolumeGroupStatusError
Compruebe si el grupo de volúmenes efímeros en el nodo es normal.
Impacto: el pod que depende del grupo de almacenamiento no puede escribir datos en el volumen temporal. El volumen temporal se vuelve a montar como un sistema de archivos de solo lectura por el kernel debido a un error de E/S.
Escenario típico: al crear un nodo, un usuario configura dos discos de datos como un grupo de almacenamiento de volumen temporal. El usuario elimina algunos discos de datos por error. Como resultado, el grupo de almacenamiento se vuelve anormal.
- Periodo de detección: 30s
- Fuente:
vgs -o vg_name, vg_attr
- Principio: Compruebe si el VG (grupo de almacenamiento) está en el estado P. En caso afirmativo, se pierden algunos PV (discos de datos).
- Programación conjunta: El planificador puede identificar automáticamente un error de grupo de almacenamiento de PV y evitar que los pods que dependen del grupo de almacenamiento se programen en el nodo.
- Escenario excepcional: El complemento de npd no puede detectar la pérdida de todos los PV (discos de datos), lo que resulta en la pérdida de VG (grupos de almacenamiento). En este caso, kubelet aísla automáticamente el nodo, detecta la pérdida de VG (grupos de almacenamiento) y actualiza los recursos correspondientes de nodestatus.allocatable a 0. Esto evita que los pods que dependen del grupo de almacenamiento se programen en el nodo. El daño de un PV solo no se puede detectar por este elemento de comprobación, sino por el elemento de comprobación ReadonlyFilesystem.
Error del grupo de almacenamiento de PV
LocalPvVolumeGroupStatusError
Compruebe el grupo de PV en el nodo.
Impacto: los pods que dependen del grupo de almacenamiento no pueden escribir datos en el volumen persistente. El volumen persistente se vuelve a montar como un sistema de archivos de solo lectura por el kernel debido a un error de E/S.
Escenario típico: Al crear un nodo, un usuario configura dos discos de datos como un grupo de almacenamiento de volúmenes persistentes. Algunos discos de datos se eliminan por error.
Error de punto de montaje
MountPointProblem
Compruebe el punto de montaje en el nodo.
Definición excepcional: No se puede acceder al punto de montaje ejecutando el comando cd.
Escenario típico: Network File System (NFS), por ejemplo, obsfs y s3fs se monta en un nodo. Cuando la conexión es anormal debido a excepciones del servidor de NFS de red o del mismo nivel, todos los procesos que acceden al punto de montaje se suspenden. Por ejemplo, durante una actualización del clúster, se reinicia un kubelet y se analizan todos los puntos de montaje. Si se detecta el punto de montaje anormal, la actualización falla.
Alternativamente, puede ejecutar el comando siguiente:
for dir in `df -h | grep -v "Mounted on" | awk "{print \\$NF}"`;do cd $dir; done && echo "ok"E/S de disco suspendido
DiskHung
Compruebe si la suspensión de E/S se produce en todos los discos del nodo, es decir, si no se responden las operaciones de lectura y escritura de E/S.
Definición de suspensión de E/S: El sistema no responde a las solicitudes de E/S de disco y algunos procesos están en estado D.
Escenario típico: Los discos no pueden responder debido a controladores de disco duro del sistema operativo anormales o a fallas graves en la red subyacente.
- Objeto de comprobación: todos los discos de datos
- Fuente: Alternativamente, puede ejecutar el comando siguiente:
iostat -xmt 1
- Umbral:
- Uso medio: ioutil >= 0.99
- Longitud media de la cola de E/S: avgqu-sz >= 1
- Volumen medio de transferencia de E/S: iops (w/s) + ioth (wMB/s) <= 1
NOTA:En algunos sistemas operativos, no hay cambios de datos durante la E/S. En este caso, calcule el uso de tiempo de E/S de CPU. El valor de iowait debe ser mayor que 0.8.
E/S de disco lento
DiskSlow
Compruebe si todos los discos del nodo tienen E/S lentas, es decir, si las E/S responden lentamente.
Escenario típico: los discos de EVS tienen E/S lentas debido a la fluctuación de la red.
- Objeto de comprobación: todos los discos de datos
- Fuente: Alternativamente, puede ejecutar el comando siguiente:
iostat -xmt 1
- Umbral predeterminado:
NOTA:Si las solicitudes de E/S no se responden y los datos await no se actualizan, este elemento de comprobación no es válido.
Tabla 5 Otros artículos de cheques Concepto de comprobación
Función
Descripción
NTP anormal
NTPProblem
Compruebe si el servicio de sincronización de reloj de nodo ntpd o chronyd se está ejecutando correctamente y si se produce una desviación de tiempo del sistema.
Umbral de desplazamiento de reloj predeterminado: 8000 ms
Error de proceso D
ProcessD
Compruebe si hay un proceso D en el nodo.
Umbral predeterminado: 10 procesos anormales detectados por tres veces consecutivas
Fuente:
- /proc/{PID}/stat
- Alternativamente, puede ejecutar el comando ps aux.
Escenario excepcional: ProcessD ignora los procesos D residentes (latido del corazón y actualización) de los que depende el controlador de SDI en el nodo de BMS.
Error del proceso Z
ProcessZ
Compruebe si el nodo tiene procesos en estado Z.
Error de ResolvConf
ResolvConfFileProblem
Compruebe si se ha perdido el archivo ResolvConf.
Comprueba si el archivo ResolvConf es normal.
Definición excepcional: No se incluye ningún servidor de resolución de nombres de dominio ascendente (servidor de nombres).
Objeto: /etc/resolv.conf
Evento programado existente
ScheduledEvent
Compruebe si existen eventos de migración en vivo programados en el nodo. Un evento de plan de migración en vivo generalmente se desencadena por una falla de hardware y es un método automático de rectificación de fallas en la capa IaaS.
Escenario típico: El host está defectuoso. Por ejemplo, el ventilador está dañado o el disco tiene sectores defectuosos. Como resultado, se activa la migración en vivo para las máquinas virtuales.
Fuente:
- http://169.254.169.254/meta-data/latest/events/scheduled
Este elemento de verificación es una función Alfa y está deshabilitado de forma predeterminada.
El componente de kubelet tiene los siguientes elementos de comprobación predeterminados, que tienen errores o defectos. Puede solucionarlos actualizando el clúster o usando npd.
Tabla 6 Conceptos de comprobación predeterminados de kubelet Concepto de comprobación
Función
Descripción
Recursos de PID insuficientes
PIDPressure
Compruebe si los PID son suficientes.
- Intervalo: 10 segundos
- Umbral: 90%
- Defecto: En la versión de comunidad 1.23.1 y versiones anteriores, este concepto de comprobación no es válido cuando se utilizan más de 65535 PID. Para más detalles, véase el problema 107107. En la versión de comunidad 1.24 y versiones anteriores, el hilo-max no se considera en este concepto de comprobación.
Memoria insuficiente
MemoryPressure
Compruebe si la memoria asignable para los contenedores es suficiente.
- Intervalo: 10 segundos
- Umbral: máx.100 MiB
- Asignable = Memoria total de un nodo - Memoria reservada de un nodo
- Defecto: Este concepto de comprobación comprueba solo la memoria consumida por contenedores y no la considera consumida por otros elementos del nodo.
Recursos de disco insuficientes
DiskPressure
Compruebe el uso del disco y el uso de inodes de los discos de kubelet y de Docker.
- Intervalo: 10 segundos
- Umbral: 90%
Aislamiento de fallas de node-problem-controller
El aislamiento de fallas solo es compatible con complementos de 1.16.0 y versiones posteriores.
De forma predeterminada, si varios nodos se vuelven defectuosos, NPC agrega manchas hasta un 10% de los nodos. Puede configurar npc.maxTaintedNode para aumentar el umbral.
El complemento de NPD de código abierto proporciona detección de fallas pero no aislamiento de fallas. CCE mejora el node-problem-controller (NPC) basado en el NPD de código abierto. Este componente se implementa en función del controlador de nodo de Kubernetes. Para las fallas reportadas por NPD, NPC agrega automáticamente manchas a los nodos para el aislamiento de fallas de nodo.
| Parámetro | Descripción | Predeterminado |
|---|---|---|
| npc.enable | Si habilitar NPC NPC no se puede deshabilitar en 1.18.0 o versiones posteriores. | true |
| npc. maxTaintedNode | Verifique cuántos nodos pueden agregar manchas npc para mitigar el impacto cuando se produce una única falla en varios nodos. El formato int y el formato porcentual son compatibles. | 10% Rango de valores:
|
| npc.affinity | Afinidad de nodos del responsable del tratamiento | N/A |
Consulta de eventos de NPD
Los eventos reportados por el complemento de npd se pueden consultar en la página Nodes.
- Inicie sesión en la consola de CCE.
- Haga clic en el nombre del clúster para acceder a la consola del clúster. Elija Nodes en el panel de navegación.
- Busque la fila que contiene el nodo de destino y haga clic en View Events. Figura 1 Consulta de eventos de nodo

Puede consultar eventos en la página mostrada.

Alarmas de AOM
Para los elementos de comprobación de NPD relacionados con el estado, puede configurar Application Operations Management (AOM) para convertir estados anormales en alarmas de AOM y notificarlo por mensaje SMS o correo electrónico.
- Inicie sesión en la consola de AOM.
- En el panel de navegación, elija Alarm Center > Alarm Rules y haga clic en Create Alarm Rule.
- Establezca una regla de alarma.
- Rule Type: Seleccione Threshold alarm.
- Monitored Object: Seleccione Command input.
- Escriba `sum(problem_gauge{clusterName="test"}) by (podIP,type)` en el cuadro de texto.

- Alarm Condition: Activar una alarma importante si el valor promedio es mayor o igual a 1 por una vez consecutiva en un período de monitorización.
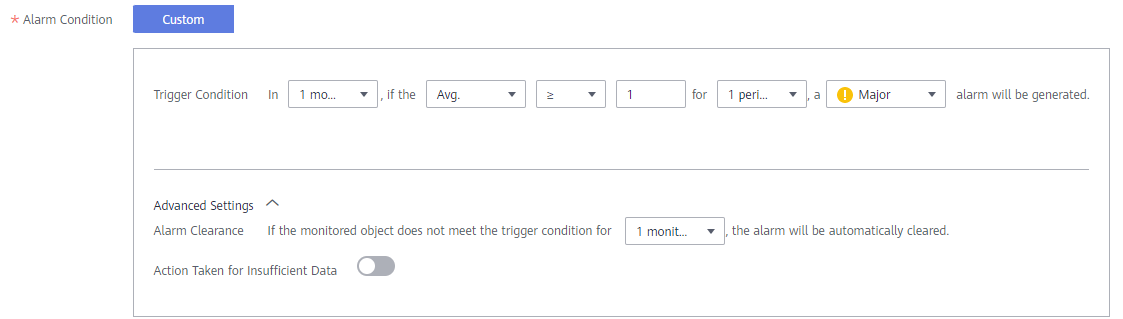
- (Opcional) Alarm notification: Para recibir notificaciones de alarmas por correo electrónico o mensaje SMS, configure las reglas de acción para la regla de alarma. Si no hay ninguna regla de acción disponible, puede crear una.
Recopilación de métricas de Prometheus
El pod daemon de NPD expone los datos métricos de Prometheus en el puerto 19901. De forma predeterminada, el pod de NPD se agrega con la anotación metrics.alpha.kubernetes.io/custom-endpoints:'[{"api":"prometheus","path":"/metrics","port":"19901","names":""}]'. Puede crear un colector de Prometheus para identificar y obtener métricas de NPD desde http://{{NpdPodIP}}:{{NpdPodPort}}/metrics.
Si la versión del complemento npd es anterior a 1.16.5, el puerto expuesto de las métricas de Prometheus es 20257.
Actualmente, los datos métricos incluyen problem_counter y problem_gauge como se muestra a continuación.
# HELP problem_counter Number of times a specific type of problem have occurred.
# TYPE problem_counter counter
problem_counter{reason="DockerHung"} 0
problem_counter{reason="DockerStart"} 0
problem_counter{reason="EmptyDirVolumeGroupStatusError"} 0
...
# HELP problem_gauge Whether a specific type of problem is affecting the node or not.
# TYPE problem_gauge gauge
problem_gauge{reason="CNIIsDown",type="CNIProblem"} 0
problem_gauge{reason="CNIIsUp",type="CNIProblem"} 0
problem_gauge{reason="CRIIsDown",type="CRIProblem"} 0
problem_gauge{reason="CRIIsUp",type="CRIProblem"} 0
.. Historial de cambios
| Versión del complemento | Versión de clúster admitida | Característica actualizada | Versión de la comunidad (solo para clústeres de v1.17 y posteriores) |
|---|---|---|---|
| 1.17.4 | /v1.(17|19|21|23|25).*/ |
| |
| 1.17.3 | /v1.(17|19|21|23|25).*/ |
| |
| 1.17.2 | /v1.(17|19|21|23|25).*/ |
| |
| 1.16.4 | /v1.(17|19|21|23).*/ |
| |
| 1.16.3 | /v1.(17|19|21|23).*/ |
| |
| 1.16.1 | /v1.(17|19|21|23).*/ |
| |
| 1.15.0 | /v1.(17|19|21|23).*/ |
| |
| 1.14.11 | /v1.(17|19|21).*/ |
| |
| 1.14.5 | /v1.(17|19).*/ |
| |
| 1.14.4 | /v1.(17|19).*/ | ||
| 1.14.2 | /v1.(17|19).*/ |
| |
| 1.13.8 | /v1.15.11|v1.17.*/ |
| |
| 1.13.6 | /v1.15.11|v1.17.*/ |
| |
| 1.13.5 | /v1.15.11|v1.17.*/ |
| |
| 1.13.2 | /v1.15.11|v1.17.*/ |
|




