
Creación de ELB Ingress en la consola
Requisitos previos
- Un ingreso proporciona acceso a la red para cargas de trabajo backend. Asegúrese de que una carga de trabajo esté disponible en un clúster. Si no hay ninguna carga de trabajo disponible, despliegue una carga de trabajo haciendo referencia a Creación de una Deployment, Creación de un StatefulSet o Creación de un DaemonSet.
- Los balanceadores de carga dedicados deben ser del tipo de aplicación (HTTP/HTTPS) que admita las redes privadas (con una IP privada).
- En las redes de paso a través de ELB (clúster de Turbo de CCE + balanceador de carga dedicado), ELB Ingress admite servicios ClusterIP. En otros escenarios, ELB Ingress admite los servicios de NodePort.
Precauciones
- Se recomienda que otros recursos no utilicen el balanceador de carga creado automáticamente por un ingreso. De lo contrario, el balanceador de carga estará ocupado cuando se elimine la entrada, dando como resultado recursos residuales.
- Después de crear una entrada, actualice y mantenga la configuración de los balanceadores de carga seleccionados en la consola de CCE. No modifique la configuración en la consola de ELB. De lo contrario, el servicio de entrada puede ser anormal.
- El URL registrado en una política de reenvío de ingreso debe ser la misma que la dirección URL utilizada para acceder al Service de backend. De lo contrario, se devolverá un error 404.
- En un clúster que usa el modo proxy IPVS, si el ingreso y el Service usan el mismo balanceador de carga de ELB, no se puede acceder a la entrada desde los nodos y contenedores en el clúster porque kube-proxy monta la dirección de LoadBalancer Service en el puente ipvs-0. Este puente intercepta el tráfico del balanceador de carga conectado a la entrada. Se recomienda utilizar diferentes balanceadores de carga de ELB para la entrada y el Service.
- No conecte el ingreso y el Service usando HTTP al mismo oyente del mismo balanceador de carga. De lo contrario, se produce un conflicto de puerto.
Adición de un ingreso de ELB
Esta sección utiliza una carga de trabajo de Nginx como ejemplo para describir cómo agregar un ingreso de ELB.
- Inicie sesión en la consola de CCE y acceda a la consola del clúster.
- Elija Networking en el panel de navegación, haga clic en la ficha Ingresses y haga clic en Create Service en la esquina superior derecha.
- Establezca los parámetros de entrada.
- Name: Especifique el nombre de una entrada, por ejemplo, ingress-demo.
- Interconnect with Nginx: Esta opción solo se muestra después de instalar el complemento nginx-ingress. Si esta opción está disponible, se ha instalado el complemento nginx-ingress. Al activar esta opción se creará una entrada de Nginx. Desactívela si desea crear una entrada de ELB. Para obtener más información, véase Creación de entradas de Nginx en la consola.
- Load Balancer
Seleccione el balanceador de carga que desea interconectar. Solo se admiten balanceadores de carga en la misma VPC que el clúster. Si no hay ningún balanceador de carga disponible, haga clic en Create Load Balancer para crear uno en la consola de ELB.
Los balanceadores de carga dedicados deben admitir HTTP y el tipo de red debe admitir las redes privadas.
La consola de CCE admite la creación automática de balanceadores de carga. Seleccione Auto create en el cuadro de lista desplegable y establezca los siguientes parámetros:- Instance Name: Ingrese un nombre de balanceador de carga.
- Public Access: Si está habilitado, se creará una EIP con ancho de banda de 5 Mbit/s. De forma predeterminada, se cobra por el tráfico.
- AZ, Subnet y Specifications (disponible solo para balanceadores de carga dedicados): Establezca la AZ, la subred y las especificaciones. Actualmente, solo se pueden crear automáticamente los balanceadores de carga dedicados del tipo de red (TCP/UDP).
- Listener Configuration: Ingreso configura un oyente para el balanceador de carga, que escucha las solicitudes del balanceador de carga y distribuye el tráfico. Una vez completada la configuración, se crea un oyente en el balanceador de carga. El nombre de oyente predeterminado es k8s__<Protocol type>_<Port number>, por ejemplo, k8s_HTTP_80.
- Front-End Protocol: HTTP y HTTPS están disponibles.
- External Port: Número de puerto abierto a la dirección de servicio de ELB. El número de puerto se puede especificar aleatoriamente.
- Certificate Source: Se admite el secreto de TLS y el certificado de servidor de ELB.
- Server Certificate: Cuando se crea un oyente de HTTPS para un balanceador de carga, debe vincular un certificado al balanceador de carga para admitir la autenticación cifrada para la transmisión de datos de HTTPS.
- TLS secret: Para obtener más información sobre cómo crear un certificado secreto, consulte Creación de un secreto.
- ELB server certificate: Utilice el certificado creado en el servicio de ELB.
Si ya hay un ingreso de HTTPS para el puerto elegido en el balanceador de carga, el certificado del nuevo ingreso de HTTPS debe ser el mismo que el certificado del ingreso existente. Esto significa que un oyente solo tiene un certificado. Si se agregan dos certificados, cada uno con una entrada diferente, al mismo oyente del mismo balanceador de carga, solo el certificado agregado más temprano tiene efecto en el balanceador de carga.
- SNI: Server Name Indication (SNI) es un protocolo extendido de TLS. Permite proporcionar múltiples nombres de dominio de acceso basados en TLS para sistemas externos que utilizan la misma dirección IP y puerto. Diferentes nombres de dominio pueden utilizar diferentes certificados de seguridad. Después de habilitar el SNI, el cliente puede enviar el nombre de dominio solicitado al iniciar una solicitud de handshake de TLS. Después de recibir la solicitud de TLS, el balanceador de carga busca el certificado basado en el nombre de dominio en la solicitud. Si se encuentra el certificado correspondiente al nombre de dominio, el balanceador de carga devuelve el certificado para la autorización. De lo contrario, se devuelve el certificado predeterminado (certificado de servidor) para la autorización.
- La opción SNI solo está disponible cuando se selecciona HTTPS.
- Esta función solo se admite para clústeres de v1.15.11 y posteriores.
- Especifique el nombre de dominio para el certificado de SNI. Solo se puede especificar un nombre de dominio para cada certificado. Se admiten los certificados de dominio comodín.
- Forwarding Policies: Cuando la dirección de acceso de una solicitud coincide con la política de reenvío (una política de reenvío consiste en un nombre de dominio y un URL, por ejemplo, 10.117.117.117:80/helloworld), la solicitud se reenvía al Service de destino correspondiente para su procesamiento. Puede hacer clic en
 para agregar varias políticas de reenvío.
para agregar varias políticas de reenvío. - Domain Name: nombre de dominio real. Asegúrese de que el nombre de dominio ha sido registrado y archivado. Una vez configurada una regla de nombre de dominio, debe usar el nombre de dominio para tener acceso.
- Regla de coincidencia para direcciones URL
- Prefix match: Si el URL está establecido en /healthz, se puede acceder al URL que cumple con el prefijo. Por ejemplo, /healthz/v1 y /healthz/v2.
- Exact match: Se puede acceder al URL solo cuando está totalmente coincidente. Por ejemplo, si el URL está establecido en /healthz, solo se puede acceder a /healthz.
- Regular expression: El URL se hace coincidir en función de la expresión regular. Por ejemplo, si la expresión regular es /[A-Za-z0-9_.-]+/test, se puede acceder a todos los URL que cumplan con esta regla, por ejemplo, /abcA9/test y /v1-Ab/test. Se admiten dos estándares de expresión regular: POSIX y Perl.
- URL: ruta de acceso a registrar, por ejemplo, /healthz.
La ruta de acceso agregada aquí debe existir en la aplicación de backend. De lo contrario, el reenvío falla.
Por ejemplo, el URL de acceso predeterminado de la aplicación Nginx es /usr/share/nginx/html. Al agregar /test a la política de reenvío de ingreso, asegúrese de que su aplicación de Nginx contiene el mismo URL, es decir, /usr/share/nginx/html/test, de lo contrario, se devuelve 404.
- Destination Service: Seleccione un Service existente o cree un Service. Los Service que no cumplen los criterios de búsqueda se eliminan automáticamente.
- Destination Service Port: Seleccione el puerto de acceso del Service de destino.
- Set ELB:
- Distribution Policy: Hay tres algoritmos disponibles: Round robin ponderado, algoritmo de conexiones mínimas ponderadas o hash de IP de origen.
- Round robin ponderado: las solicitudes se reenvían a diferentes servidores en función de sus pesos, lo que indica el rendimiento del procesamiento del servidor. Los servidores backend con mayores pesos reciben proporcionalmente más solicitudes, mientras que los servidores con igual peso reciben el mismo número de solicitudes. Este algoritmo se utiliza a menudo para las conexiones cortas, como los servicios de HTTP.
- Conexiones mínimas ponderadas: Además del peso asignado a cada servidor, también se considera el número de conexiones procesadas por cada servidor backend. Las solicitudes se reenvían al servidor con la relación de conexiones/peso más baja. Basado en las conexiones mínimas, el algoritmo conexiones mínimas ponderadas asigna un peso a cada servidor basado en su capacidad de procesamiento. Este algoritmo se utiliza a menudo para las conexiones persistentes, tales como las conexiones de base de datos.
- Hash de IP de origen: La dirección IP de origen de cada solicitud se calcula usando el algoritmo hash para obtener una clave hash única, y todos los servidores backend están numerados. La clave generada asigna el cliente a un servidor determinado. Esto permite que las solicitudes de diferentes clientes se distribuyan en modo de equilibrio de carga y garantiza que las solicitudes del mismo cliente se reenvíen al mismo servidor. Este algoritmo se aplica a las conexiones de TCP sin cookies.
- Sticky Session: Esta función está deshabilitada por defecto. Las opciones son las siguientes:
- Load balancer cookie: Ingrese la Stickness Duration que va de 1 a 1,440 minutos.
- Application cookie: Este parámetro solo está disponible para los balanceadores de carga compartidos. Además, debe introducir Cookie Name que oscila entre 1 y 64 caracteres.
Cuando la política de distribución utiliza el hash IP de origen, no se puede establecer la sesión adhesiva.
- Health Check: Establezca la configuración de comprobación de estado del balanceador de carga. Si esta función está habilitada, se admiten las siguientes configuraciones:
Parámetro
Descripción
Protocol
Cuando el protocolo del puerto de servicio de destino se establece en TCP, se admiten TCP y HTTP. Cuando se establece en UDP, solo se admite UDP.
- Check Path (soportado únicamente por el protocolo de comprobación de estado HTTP): especifica el URL de comprobación de estado. La ruta de comprobación debe comenzar con un (/) de barra diagonal y contener entre 1 y 80 caracteres.
Port
De forma predeterminada, el puerto de Service (Puerto de nodo y puerto contenedor del Service) se utiliza para la comprobación de estado. También puede especificar otro puerto para la comprobación de estado. Después de especificar el puerto, se agregará un puerto de servicio llamado cce-healthz para el Service.
- Node Port: si se utiliza un balanceador de carga compartido o no se asocia ninguna instancia ENI, el puerto de nodo se utiliza como puerto de comprobación de estado. Si no se especifica este parámetro, se utiliza un puerto aleatorio. El valor oscila entre 30000 y 32767.
- Container Port: Cuando un balanceador de carga dedicado está asociado a una instancia ENI, el puerto contenedor se utiliza para la comprobación de estado. El valor varía de 1 a 65535.
Check Interval (s)
Especifica el intervalo máximo entre las comprobaciones de estado. El valor varía de 1 a 50.
Timeout (s)
Especifica la duración máxima del tiempo de espera para cada comprobación de estado. El valor varía de 1 a 50.
Max. Retries
Especifica el número máximo de reintentos de comprobación de estado. El valor varía de 1 a 10.
- Distribution Policy: Hay tres algoritmos disponibles: Round robin ponderado, algoritmo de conexiones mínimas ponderadas o hash de IP de origen.
- Operation: Haga clic en Delete para eliminar la configuración.
- Annotation: Las entradas proporcionan algunas funciones avanzadas de CCE, que se implementan mediante anotaciones. Cuando se usa kubectl para crear un contenedor se usarán anotaciones. Para más detalles, véase Creación de una entrada - Creación automática de un balanceador de carga y Creación de un ingreso - interconexión con un balanceador de carga existente.
- Una vez completada la configuración, haga clic en OK. Después de crear la entrada, se muestra en la lista de entrada.
En la consola de ELB, puede ver el ELB creado automáticamente con CCE. El nombre predeterminado es cce-lb-ingress.UID. Haga clic en el nombre del ELB para acceder a su página de detalles. En la página de ficha Listeners, vea la configuración de la ruta del ingreso, incluidos el URL, el puerto de oyente y el puerto del grupo de servidores backend.

Después de crear la entrada, actualice y mantenga el balanceador de carga seleccionado en la consola de CCE. No mantenga el balanceador de carga en la consola de ELB. De lo contrario, el servicio de entrada puede ser anormal.
Figura 1 Configuración de enrutamiento de ELB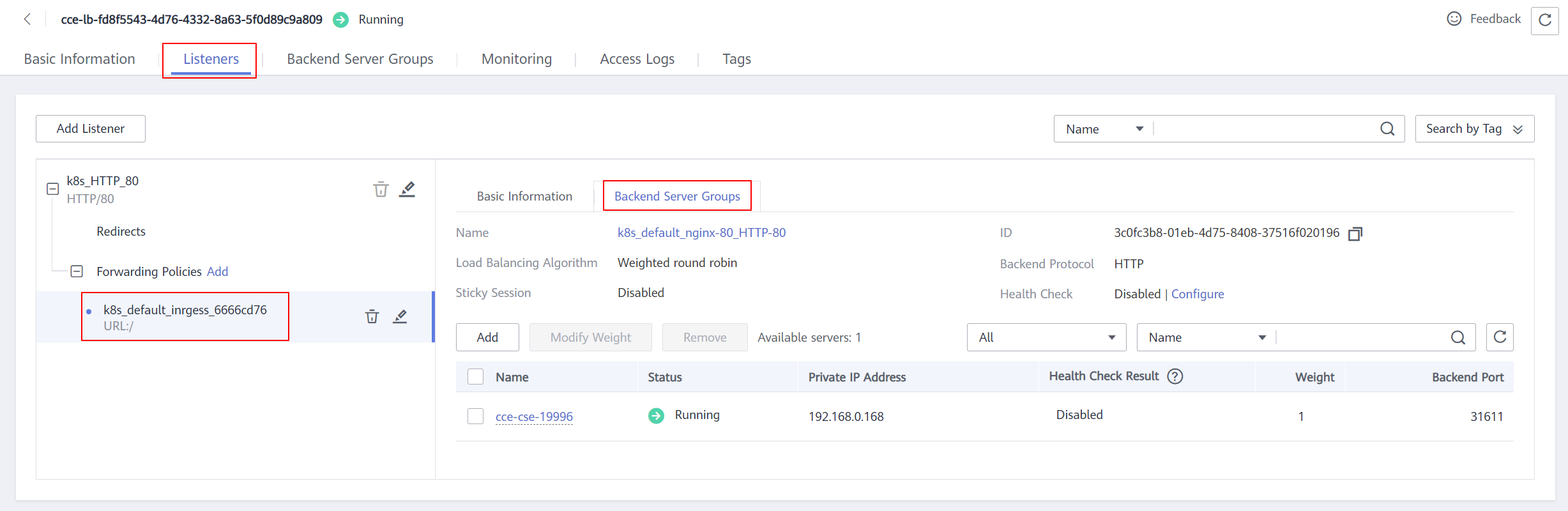
- Acceda a la interfaz /healthz de la carga de trabajo, por ejemplo, carga de trabajo defaultbackend.
- Obtenga la dirección de acceso de la interfaz /healthz de la carga de trabajo. La dirección de acceso consiste en la dirección IP del balanceador de carga, el puerto externo y el URL de asignación, por ejemplo, 10.**.**.**:80/healthz.
- Ingrese el URL de la interfaz /healthz, por ejemplo http://10**.**.**:80/healthz, en el cuadro de direcciones del navegador para acceder a la carga de trabajo, como se muestra en Figura 2.

Operaciones relacionadas
La estructura de entrada de Kubernetes no contiene el campo property. Por lo tanto, la entrada creada por la API invocada por client-go no contiene el campo property. CCE proporciona una solución para garantizar la compatibilidad con Kubernetes client-go. Para obtener más información sobre la solución, consulte ¿Cómo puedo lograr la compatibilidad entre la propiedad de Ingress y el cliente-go de Kubernetes?




