
Configuración de la comprobación de estado de un contenedor
Escenario
Comprobación de estado comprueba regularmente el estado de salud de contenedores durante la ejecución de contenedor. Si la función de comprobación de estado no está configurada, un pod no puede detectar excepciones de aplicación ni reiniciar automáticamente la aplicación para restaurarla. Esto dará como resultado una situación en la que el estado del pod es normal pero la aplicación en el pod es anormal.
Kubernetes proporciona las siguientes sondas de comprobación de estado:
- Liveness probe (livenessProbe): comprueba si un contenedor sigue vivo. Es similar al comando ps que comprueba si existe un proceso. Si se produce un error en la comprobación de vida de un contenedor, el clúster reinicia el contenedor. Si la comprobación de vitalidad tiene éxito, no se ejecuta ninguna operación.
- Readiness probe (readinessProbe): comprueba si un contenedor está listo para procesar las solicitudes de los usuarios. Al detectarse que el contenedor no está listo, el tráfico de servicio no se dirigirá al contenedor. Algunas aplicaciones pueden tardar mucho tiempo en iniciarse antes de que puedan proporcionar servicios. Esto se debe a que necesitan cargar datos de disco o confiar en el inicio de un módulo externo. En este caso, el proceso de aplicación se está ejecutando, pero la aplicación no puede proporcionar servicios. Para solucionar este problema, se utiliza este sondeo de comprobación de estado. Si la comprobación de disponibilidad del contenedor falla, el clúster enmascara todas las solicitudes enviadas al contenedor. Si la comprobación de la preparación del contenedor se realiza correctamente, se puede acceder al contenedor.
- Startup probe (startupProbe): comprueba cuando se ha iniciado una aplicación de contenedor. Si se configura un sondeo de este tipo, deshabilita las comprobaciones de disponibilidad y de vida hasta que tenga éxito, asegurando que esos sondeos no interfieran con el inicio de la aplicación. Esto se puede usar para adoptar controles de vida en contenedores de inicio lento, evitando que el kubelet los termine antes de que se inicien.
Método de comprobación
- HTTP request
Este modo de comprobación de estado es aplicable a contenedores que proporcionan servicios HTTP/HTTPS. El clúster inicia periódicamente una solicitud GET de HTTP/HTTPS a tales contenedores. Si el código de retorno de la respuesta HTTP/HTTPS está dentro de 200-399, la sonda tiene éxito. De lo contrario, la sonda falla. En este modo de comprobación de estado, debe especificar un puerto de escucha contenedor y una ruta de solicitud HTTP/HTTPS.
Por ejemplo, para un contenedor que proporciona servicios HTTP, la ruta de comprobación HTTP es /health-check y el puerto es 80 y la dirección del host es opcional (que por defecto es la dirección IP de contenedor). Aquí, 172.16.0.186 se usa como ejemplo, y podemos obtener tal petición: GET http://172.16.0.186:80/health-check. El clúster inicia periódicamente esta solicitud al contenedor. También puede agregar uno o más encabezados a una solicitud de HTTP. Por ejemplo, establezca el nombre del encabezado de la solicitud en Custom-Header y el valor correspondiente en example.
Figura 1 Comprobación basada en solicitudes HTTP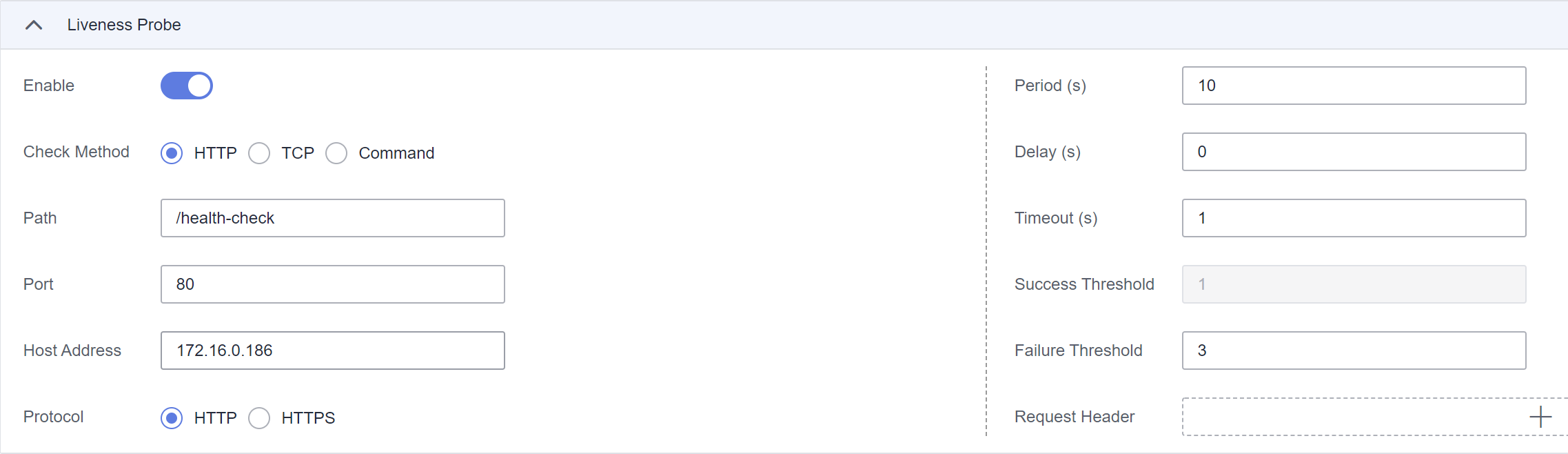
- TCP port
Para un contenedor que proporciona servicios de comunicación de TCP, el clúster establece periódicamente una conexión TCP con contenedor. Si la conexión se realiza correctamente, la sonda se realiza correctamente. De lo contrario, la sonda falla. En este modo de comprobación de estado, debe especificar un puerto de escucha de contenedor.
Por ejemplo, si tiene un contenedor Nginx con el puerto de servicio 80, después de especificar el puerto TCP 80 para la escucha de contenedor, el clúster iniciará periódicamente una conexión TCP con el puerto 80 del contenedor. Si la conexión se realiza correctamente, la sonda se realiza correctamente. De lo contrario, la sonda falla.
Figura 2 Comprobación basada en el puerto de TCP
- CLI
CLI es una herramienta eficiente para la comprobación de estado. Cuando utilice CLI, debe especificar un comando ejecutable en un contenedor. El clúster ejecuta periódicamente el comando en contenedor. Si el resultado del comando es 0, la comprobación de estado se realiza correctamente. De lo contrario, la comprobación de estado falla.
El modo de CLI se puede utilizar para reemplazar la comprobación de estado basada en petición HTTP y basada en el puerto de TCP.
- Para un puerto de TCP, puede utilizar un script de programa para conectarse a un puerto de contenedor. Si la conexión se realiza correctamente, el script devuelve 0. De lo contrario, la secuencia de comandos devuelve –1.
- Para una solicitud de HTTP, puede usar el comando script para ejecutar el comando wget para detectar el contenedor.
wget http://127.0.0.1:80/health-check
Compruebe el código de retorno de la respuesta. Si el código de retorno está dentro de 200-399, la secuencia de comandos devuelve 0. De lo contrario, la secuencia de comandos devuelve –1.
Figura 3 Comprobación basada en CLI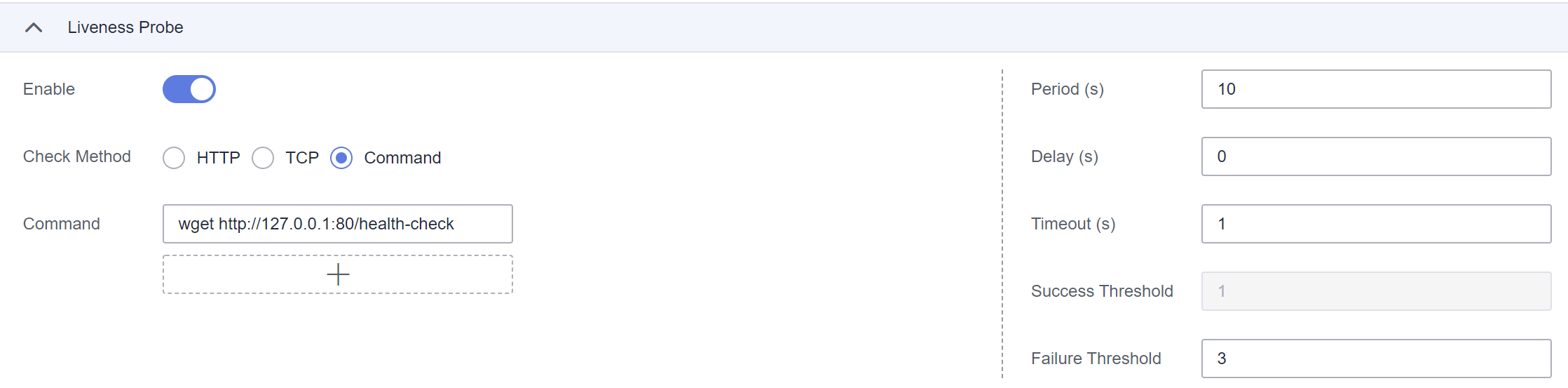

- Ponga el programa a ejecutar en la imagen contenedor para que el programa pueda ser ejecutado.
- Si el comando que se va a ejecutar es un script de shell, no especifique directamente el script como el comando, sino agregue un analizador de scripts. Por ejemplo, si el script es /data/scripts/health_check.sh debe especificar sh/data/scripts/health_check.sh para la ejecución del comando. La razón es que el clúster no está en el entorno de terminal cuando se ejecutan programas en un contenedor.
- gRPC Check Las comprobaciones de gRPC pueden configurar sondas de inicio, vida y preparación para su aplicación gRPC sin exponer ningún punto de conexión de HTTP, ni necesita un ejecutable. Kubernetes puede conectarse a su carga de trabajo a través de gRPC y consultar su estado.
- La comprobación de gRPC solo se admite en los clústeres de CCE de v1.25 o posterior.
- Para usar gRPC para verificación, su aplicación debe soportar el protocolo de verificación de estado de gRPC.
- Similar a los sondeos HTTP y TCP, si el puerto es incorrecto o la aplicación no admite el protocolo de comprobación de estado, la comprobación falla.
Figura 4 Comprobación de gRPC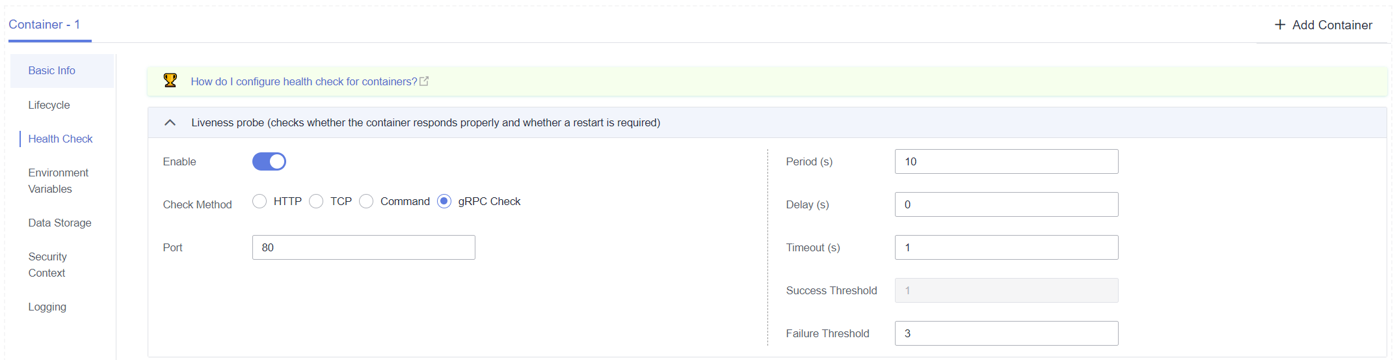
Parámetros comunes
| Parámetro | Descripción |
|---|---|
| Period (periodSeconds) | Indica el período de detección de la sonda, en segundos. Por ejemplo, si este parámetro se establece en 30, la detección se realiza cada 30 segundos. |
| Delay (initialDelaySeconds) | Compruebe el tiempo de retraso en segundos. Establezca este parámetro de acuerdo con la hora normal de inicio de los servicios. Por ejemplo, si este parámetro se establece en 30, la comprobación de estado se iniciará 30 segundos después de iniciar el contenedor. El tiempo está reservado para que comiencen los servicios en contenedores. |
| Timeout (timeoutSeconds) | Número de segundos después de los cuales la sonda se agota. Unidad: segundo. Por ejemplo, si este parámetro se establece en 10, el tiempo de espera para realizar una comprobación de estado es de 10s. Si el tiempo de espera transcurre, la comprobación de estado se considera una falla. Si el parámetro se deja en blanco o se establece en 0, el tiempo de espera predeterminado es de 1s. |
| Success Threshold (successThreshold) | Mínimo éxitos consecutivos para que la sonda se considere exitosa después de haber fallado. Por ejemplo, si este parámetro se establece en 1, el estado de la carga de trabajo es normal solo cuando la comprobación de estado es correcta durante una vez consecutiva después de que la comprobación de estado falla. El valor predeterminado es 1, que también es el valor mínimo. El valor de este parámetro se fija a 1 en las Liveness Probe y Startup Probe. |
| Failure Threshold (failureThreshold) | Número de reintentos cuando falla la detección. Renunciarse en caso de sonda de vida significa reiniciar el contenedor. En caso de sonda de preparación, el pod estará marcada como Unready. El valor predeterminado es 3. El valor mínimo es 1. |
Ejemplo de YAML
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: nginx:alpine
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 80
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
startupProbe:
httpGet:
path: /healthz
port: 80
failureThreshold: 30
periodSeconds: 10 



