
Política de programación (afinidad/antiafinidad)
Un nodeSelector proporciona una forma muy sencilla de restringir pods a nodos con etiquetas particulares, como se menciona en Creación de un DaemonSet. La función de afinidad y antiafinidad amplía enormemente los tipos de restricciones que puede expresar.
Kubernetes admite afinidad y antiafinidad a nivel de nodo y de pod. Puede configurar reglas personalizadas para lograr una programación de afinidad y antiafinidad.For example, you can deploy frontend pods and backend pods together, deploy the same type of applications on a specific node, or deploy different applications on different nodes.
Node Affinity (nodeAffinity)
Labels are the basis of affinity rules. Let's look at the labels on nodes in a cluster.
$ kubectl describe node 192.168.0.212
Name: 192.168.0.212
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
failure-domain.beta.kubernetes.io/is-baremetal=false
failure-domain.beta.kubernetes.io/region=******
failure-domain.beta.kubernetes.io/zone=******
kubernetes.io/arch=amd64
kubernetes.io/availablezone=******
kubernetes.io/eniquota=12
kubernetes.io/hostname=192.168.0.212
kubernetes.io/os=linux
node.kubernetes.io/subnetid=fd43acad-33e7-48b2-a85a-24833f362e0e
os.architecture=amd64
os.name=EulerOS_2.0_SP5
os.version=3.10.0-862.14.1.5.h328.eulerosv2r7.x86_64 Estas etiquetas son agregadas automáticamente por CCE durante la creación del nodo. A continuación se describen algunas que se utilizan con frecuencia durante la programación.
- failure-domain.beta.kubernetes.io/region: región donde se encuentra el nodo.
- failure-domain.beta.kubernetes.io/zone: zona de disponibilidad a la que pertenece el nodo.
- kubernetes.io/hostname: nombre de host del nodo.
Cuando despliega pods, puede usar un nodeSelector, como se describe en el documento DaemonSet para restringir pods a nodos con las etiquetas específicas. En el ejemplo siguiente se muestra cómo utilizar un nodeSelector para desplegar pods solo en los nodos con la etiqueta gpu=true.
apiVersion: v1 kind: Pod metadata: name: nginx spec: nodeSelector: # Node selection. A pod is deployed on a node only when the node has the gpu=true label. gpu: true ...
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpu
labels:
app: gpu
spec:
selector:
matchLabels:
app: gpu
replicas: 3
template:
metadata:
labels:
app: gpu
spec:
containers:
- image: nginx:alpine
name: gpu
resources:
requests:
cpu: 100m
memory: 200Mi
limits:
cpu: 100m
memory: 200Mi
imagePullSecrets:
- name: default-secret
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: gpu
operator: In
values:
- "true" Aunque la regla de afinidad de nodo requiere más líneas, es más expresiva, lo que se describirá más adelante.
requiredDuringSchedulingIgnoredDuringExecution parece ser complejo, pero puede entenderse fácilmente como una combinación de dos partes.
- requiredDuringScheduling indica que los pods se pueden programar en el nodo solo cuando se cumplen todas las reglas definidas (requerido).
- IgnoredDuringExecution indica que los pods que ya se están ejecutando en el nodo no necesitan cumplir las reglas definidas. Es decir, se ignora una etiqueta en el nodo, y los pods que requieren que el nodo contenga esa etiqueta no se reprogramarán.
Además, el valor de operator es In, indicando que el valor de la etiqueta debe estar en la lista de valores. Otros valores de operador disponibles son los siguientes:
- NotIn: El valor de etiqueta no está en una lista.
- Exists: Existe una etiqueta específica.
- DoesNotExist: No existe una etiqueta específica.
- Gt: El valor de etiqueta es mayor que un valor especificado (comparación de cadenas).
- Lt: El valor de etiqueta es menor que un valor especificado (comparación de cadenas).
Tenga en cuenta que no hay tal cosa como nodeAntiAffinity porque los operadores NotIn y DoesNotExist proporcionan la misma función.
A continuación se describe cómo comprobar si la regla tiene efecto. Suponga que un clúster tiene tres nodos.
$ kubectl get node NAME STATUS ROLES AGE VERSION 192.168.0.212 Ready <none> 13m v1.15.6-r1-20.3.0.2.B001-15.30.2 192.168.0.94 Ready <none> 13m v1.15.6-r1-20.3.0.2.B001-15.30.2 192.168.0.97 Ready <none> 13m v1.15.6-r1-20.3.0.2.B001-15.30.2
Agregue la etiqueta gpu=true al nodo 192.168.0.212.
$ kubectl label node 192.168.0.212 gpu=true node/192.168.0.212 labeled $ kubectl get node -L gpu NAME STATUS ROLES AGE VERSION GPU 192.168.0.212 Ready <none> 13m v1.15.6-r1-20.3.0.2.B001-15.30.2 true 192.168.0.94 Ready <none> 13m v1.15.6-r1-20.3.0.2.B001-15.30.2 192.168.0.97 Ready <none> 13m v1.15.6-r1-20.3.0.2.B001-15.30.2
Cree la Deployment. Puede encontrar que todos los pods se despliegan en el nodo 192.168.0.212.
$ kubectl create -f affinity.yaml deployment.apps/gpu created $ kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE gpu-6df65c44cf-42xw4 1/1 Running 0 15s 172.16.0.37 192.168.0.212 gpu-6df65c44cf-jzjvs 1/1 Running 0 15s 172.16.0.36 192.168.0.212 gpu-6df65c44cf-zv5cl 1/1 Running 0 15s 172.16.0.38 192.168.0.212
Regla de preferencia de nodo
La regla requiredDuringSchedulingIgnoredDuringExecution anterior es una regla de selección dura. Hay otro tipo de regla de selección, es decir, preferredDuringSchedulingIgnoredDuringExecution. Se utiliza para especificar qué nodos se prefieren durante la planificación.
Para lograr este efecto, agregue un nodo conectado con discos de SAS al clúster, agregue la etiqueta DISK=SAS al nodo y agregue la etiqueta DISK=SSD a los otros tres nodos.
$ kubectl get node -L DISK,gpu NAME STATUS ROLES AGE VERSION DISK GPU 192.168.0.100 Ready <none> 7h23m v1.15.6-r1-20.3.0.2.B001-15.30.2 SAS 192.168.0.212 Ready <none> 8h v1.15.6-r1-20.3.0.2.B001-15.30.2 SSD true 192.168.0.94 Ready <none> 8h v1.15.6-r1-20.3.0.2.B001-15.30.2 SSD 192.168.0.97 Ready <none> 8h v1.15.6-r1-20.3.0.2.B001-15.30.2 SSD
Defina una Deployment. Utilice la regla preferredDuringSchedulingIgnoredDuringExecution para establecer la ponderación de los nodos con el disco de SSD instalado como 80 y los nodos con la etiqueta gpu=true como 20. De esta manera, los pods se despliegan preferentemente en los nodos con el disco SSD instalado.
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpu
labels:
app: gpu
spec:
selector:
matchLabels:
app: gpu
replicas: 10
template:
metadata:
labels:
app: gpu
spec:
containers:
- image: nginx:alpine
name: gpu
resources:
requests:
cpu: 100m
memory: 200Mi
limits:
cpu: 100m
memory: 200Mi
imagePullSecrets:
- name: default-secret
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 80
preference:
matchExpressions:
- key: DISK
operator: In
values:
- SSD
- weight: 20
preference:
matchExpressions:
- key: gpu
operator: In
values:
- "true" Después del despliegue, hay cinco pods desplegados en el nodo 192.168.0.212 (etiqueta: DISK=SSD y GPU=true), tres pods desplegados en el nodo 192.168.0.97 (etiqueta: DISK=SSD), y dos pods desplegados en el nodo 192.168.0.100 (etiqueta: DISK=SAS).
En la salida anterior, puede encontrar que ningún pod de la Deployment está programado al nodo 192.168.0.94 (etiqueta:DISK=SSD). Esto se debe a que el nodo ya tiene muchos pods en él y su uso de recursos es alto. Esto también indica que la regla preferredDuringSchedulingIgnoredDuringExecution define una preferencia en lugar de un requisito difícil.
$ kubectl create -f affinity2.yaml deployment.apps/gpu created $ kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE gpu-585455d466-5bmcz 1/1 Running 0 2m29s 172.16.0.44 192.168.0.212 gpu-585455d466-cg2l6 1/1 Running 0 2m29s 172.16.0.63 192.168.0.97 gpu-585455d466-f2bt2 1/1 Running 0 2m29s 172.16.0.79 192.168.0.100 gpu-585455d466-hdb5n 1/1 Running 0 2m29s 172.16.0.42 192.168.0.212 gpu-585455d466-hkgvz 1/1 Running 0 2m29s 172.16.0.43 192.168.0.212 gpu-585455d466-mngvn 1/1 Running 0 2m29s 172.16.0.48 192.168.0.97 gpu-585455d466-s26qs 1/1 Running 0 2m29s 172.16.0.62 192.168.0.97 gpu-585455d466-sxtzm 1/1 Running 0 2m29s 172.16.0.45 192.168.0.212 gpu-585455d466-t56cm 1/1 Running 0 2m29s 172.16.0.64 192.168.0.100 gpu-585455d466-t5w5x 1/1 Running 0 2m29s 172.16.0.41 192.168.0.212
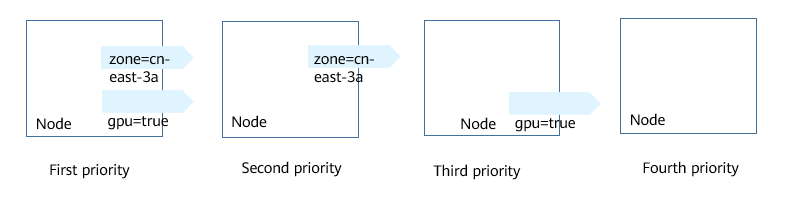
En el ejemplo anterior, la prioridad de planificación de nodo es como sigue. Los nodos con etiquetas SSD y gpu=true tienen la prioridad más alta. Los nodos con la etiqueta SSD pero sin etiqueta gpu=true tienen la segunda prioridad (peso: 80). Los nodos con la etiqueta gpu=true pero sin etiqueta SSD tienen la tercera prioridad. Los nodos sin ninguna de estas dos etiquetas tienen la prioridad más baja.
Afinidad de la carga de trabajo (podAffinity)
Las reglas de afinidad de nodos afectan solo a la afinidad entre pods y nodos. Kubernetes también admite la configuración de reglas de afinidad dentro de pod. Por ejemplo, el frontend y el backend de una aplicación se pueden desplegar juntos en un nodo para reducir la latencia de acceso. También hay dos tipos de reglas de afinidad dentro de pod: requiredDuringSchedulingIgnoredDuringExecution y preferredDuringSchedulingIgnoredDuringExecution.
Suponga que el backend de una aplicación ha sido creado y tiene la etiqueta app=backend.
$ kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE backend-658f6cb858-dlrz8 1/1 Running 0 2m36s 172.16.0.67 192.168.0.100
Puede configurar la siguiente regla de afinidad de pod para desplegar los pods frontend de la aplicación en el mismo nodo que los pods backend.
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend
labels:
app: frontend
spec:
selector:
matchLabels:
app: frontend
replicas: 3
template:
metadata:
labels:
app: frontend
spec:
containers:
- image: nginx:alpine
name: frontend
resources:
requests:
cpu: 100m
memory: 200Mi
limits:
cpu: 100m
memory: 200Mi
imagePullSecrets:
- name: default-secret
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- backend Despliegue el frontend y puede encontrar que el frontend se despliega en el mismo nodo que el backend.
$ kubectl create -f affinity3.yaml deployment.apps/frontend created $ kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE backend-658f6cb858-dlrz8 1/1 Running 0 5m38s 172.16.0.67 192.168.0.100 frontend-67ff9b7b97-dsqzn 1/1 Running 0 6s 172.16.0.70 192.168.0.100 frontend-67ff9b7b97-hxm5t 1/1 Running 0 6s 172.16.0.71 192.168.0.100 frontend-67ff9b7b97-z8pdb 1/1 Running 0 6s 172.16.0.72 192.168.0.100
El campo topologyKey se utiliza para dividir dominios de topología para especificar el rango de selección. Si las claves de etiqueta y los valores de los nodos son los mismos, se considera que los nodos están en el mismo dominio de topología. A continuación, se seleccionan los contenidos definidos en las siguientes reglas. El efecto de topologyKey no se demuestra completamente en el ejemplo anterior porque todos los nodos tienen la etiqueta kubernetes.io/hostname. Es decir, todos los nodos están dentro del rango.
Para ver cómo funciona topologyKey, suponga que el backend de la aplicación tiene dos pods, que se ejecutan en los nodos diferentes.
$ kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE backend-658f6cb858-5bpd6 1/1 Running 0 23m 172.16.0.40 192.168.0.97 backend-658f6cb858-dlrz8 1/1 Running 0 2m36s 172.16.0.67 192.168.0.100
Agregue la etiqueta prefer=true a los nodos 192.168.0.97 y 192.168.0.94.
$ kubectl label node 192.168.0.97 prefer=true node/192.168.0.97 labeled $ kubectl label node 192.168.0.94 prefer=true node/192.168.0.94 labeled $ kubectl get node -L prefer NAME STATUS ROLES AGE VERSION PREFER 192.168.0.100 Ready <none> 44m v1.15.6-r1-20.3.0.2.B001-15.30.2 192.168.0.212 Ready <none> 91m v1.15.6-r1-20.3.0.2.B001-15.30.2 192.168.0.94 Ready <none> 91m v1.15.6-r1-20.3.0.2.B001-15.30.2 true 192.168.0.97 Ready <none> 91m v1.15.6-r1-20.3.0.2.B001-15.30.2 true
Si la topologyKey de podAffinity se establece en prefer, los dominios de topología de nodo se dividen como se muestra en Figura 2.
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: prefer
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- backend 
Durante la planificación, los dominios de topología de nodo se dividen en función de la etiqueta prefer. En este ejemplo, las 192.168.0.97 y 192.168.0.94 se dividen en el mismo dominio de topología. Si un pod con la etiqueta app=backend se ejecuta en el dominio de topología, aunque no todos los nodos del dominio de topología ejecuten el pod con la etiqueta app=backend (en este ejemplo, solo el nodo 192.168.0.97 tiene tal pod) frontend también se despliega en este dominio de topología (192.168.0.97 o 192.168.0.94).
$ kubectl create -f affinity3.yaml deployment.apps/frontend created $ kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE backend-658f6cb858-5bpd6 1/1 Running 0 26m 172.16.0.40 192.168.0.97 backend-658f6cb858-dlrz8 1/1 Running 0 5m38s 172.16.0.67 192.168.0.100 frontend-67ff9b7b97-dsqzn 1/1 Running 0 6s 172.16.0.70 192.168.0.97 frontend-67ff9b7b97-hxm5t 1/1 Running 0 6s 172.16.0.71 192.168.0.97 frontend-67ff9b7b97-z8pdb 1/1 Running 0 6s 172.16.0.72 192.168.0.97
Antiafinidad de carga de trabajo (podAntiAffinity)
A diferencia de los escenarios en los que se prefiere que los pods se planifiquen en el mismo nodo, a veces, podría ser exactamente lo contrario. Por ejemplo, si ciertos pods se despliegan juntos, afectarán al rendimiento.
El siguiente es un ejemplo de definición de una regla antiafinidad. Esta regla divide los dominios de topología de nodo por la etiqueta kubernetes.io/hostname. Si ya existe un pod con la etiqueta app=frontend en un nodo del dominio de topología, los pods con la misma etiqueta no se pueden programar en otros nodos del dominio de topología.
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend
labels:
app: frontend
spec:
selector:
matchLabels:
app: frontend
replicas: 5
template:
metadata:
labels:
app: frontend
spec:
containers:
- image: nginx:alpine
name: frontend
resources:
requests:
cpu: 100m
memory: 200Mi
limits:
cpu: 100m
memory: 200Mi
imagePullSecrets:
- name: default-secret
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname # Topology domain of the node
labelSelector: # Pod label matching rule
matchExpressions:
- key: app
operator: In
values:
- frontend Cree una regla de antiafinidad y vea el resultado despliegue. En el ejemplo, los dominios de topología de nodo se dividen por la etiqueta kubernetes.io/hostname. Los valores de etiqueta de los nodos con la etiqueta kubernetes.io/hostname son diferentes, por lo que solo hay un nodo en un dominio de topología. Si ya existe un pod con la etiqueta frontend en un dominio de topología (un nodo en este ejemplo), el dominio de topología no programará pods con la misma etiqueta. En este ejemplo, solo hay cuatro nodos. Por lo tanto, hay un pod que está en el estado Pending y no se puede programar.
$ kubectl create -f affinity4.yaml deployment.apps/frontend created $ kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE frontend-6f686d8d87-8dlsc 1/1 Running 0 18s 172.16.0.76 192.168.0.100 frontend-6f686d8d87-d6l8p 0/1 Pending 0 18s <none> <none> frontend-6f686d8d87-hgcq2 1/1 Running 0 18s 172.16.0.54 192.168.0.97 frontend-6f686d8d87-q7cfq 1/1 Running 0 18s 172.16.0.47 192.168.0.212 frontend-6f686d8d87-xl8hx 1/1 Running 0 18s 172.16.0.23 192.168.0.94
Configuración de políticas de programación
- Inicie sesión en la consola de CCE.
- Cuando cree una carga de trabajo, haga clic en Scheduling en el área Advanced Settings.
Tabla 1 Configuración de afinidad de nodo Parámetro
Descripción
Required
Esta es una regla dura que se debe cumplir para la programación. Corresponde a requiredDuringSchedulingIgnoredDuringExecution en Kubernetes. Se pueden establecer varias reglas requeridas, y la programación se realizará si solo se cumple una de ellas.
Preferred
Esta es una regla flexible que especifica las preferencias que el planificador intentará aplicar, pero no garantiza. Corresponde a preferredDuringSchedulingIgnoredDuringExecution en Kubernetes. La programación se realiza cuando se cumple una regla o cuando no se cumple ninguna de las reglas.
- En Node Affinity, Workload Affinity y Workload Anti-Affinity, haga clic en
 para agregar políticas de programación. En el cuadro de diálogo que se muestra, agregue una política directamente o especificando un nodo o una AZ. La especificación de un nodo o una AZ se implementa esencialmente con etiquetas. La etiqueta kubernetes.io/hostname se utiliza cuando se especifica un nodo y la etiqueta failure-domain.beta.kubernetes.io/zone se utiliza cuando se especifica una AZ.
para agregar políticas de programación. En el cuadro de diálogo que se muestra, agregue una política directamente o especificando un nodo o una AZ. La especificación de un nodo o una AZ se implementa esencialmente con etiquetas. La etiqueta kubernetes.io/hostname se utiliza cuando se especifica un nodo y la etiqueta failure-domain.beta.kubernetes.io/zone se utiliza cuando se especifica una AZ.Tabla 2 Configuración de políticas de programación Parámetro
Descripción
Label
Etiqueta del nodo. Puede utilizar la etiqueta predeterminada o personalizar una etiqueta.
Operator
Se apoyan las siguientes relaciones: In, NotIn, Exists, DoesNotExist, Gt y Lt
- In: Existe una etiqueta en la lista de etiquetas.
- NotIn: Una etiqueta no existe en la lista de etiquetas.
- Exists: Existe una etiqueta específica.
- DoesNotExist: No existe una etiqueta específica.
- Gt: El valor de etiqueta es mayor que un valor especificado (comparación de cadenas).
- Lt: El valor de etiqueta es menor que un valor especificado (comparación de cadenas).
Label Value
Valor de etiqueta.
Namespace
Este parámetro solo está disponible en una política de programación de afinidad o antiafinidad de carga de trabajo.
Espacio de nombres para el que entra en vigor la política de programación.
Topology Key
Este parámetro solo se puede utilizar en una política de programación de afinidad o antiafinidad de carga de trabajo.
Seleccione el ámbito especificado por topologyKey y, a continuación, seleccione el contenido definido por la política.
Weight
Este parámetro solo se puede establecer en una política de programación de Preferred.




