
Uso de HPA y CA para el ajuste automático de cargas de trabajo y nodos
Escenarios de aplicación
La mejor manera de manejar el tráfico creciente es ajustar automáticamente el número de máquinas según el volumen de tráfico o el uso de recursos, lo que se denomina ajuste.
Cuando se utilizan pods o contenedores para desplegar aplicaciones, normalmente se requiere establecer el límite superior de recursos disponibles para pods o contenedores para evitar el uso ilimitado de recursos de nodo durante las horas pico. Sin embargo, después de alcanzar el límite superior, puede producirse un error de aplicación. Para resolver este problema, escala el edición de pods para compartir cargas de trabajo. Si el uso de recursos de nodo aumenta hasta cierto punto que los pods recién agregados no pueden planificarse, ajuste el número de nodos basándose en el uso de recursos de nodo.
Solución
Dos políticas principales de ajuste automático son HPA (Horizontal Pod Autoscaling) y CA (Cluster AutoScaling). HPA es para el ajuste automático de la carga de trabajo y CA es para el ajuste automático de nodos.
HPA y CA trabajan entre sí. HPA requiere suficientes recursos de clúster para escalar con éxito. Cuando los recursos del clúster son insuficientes, se necesita CA para agregar nodos. Si HPA reduce las cargas de trabajo, el clúster tendrá una gran cantidad de recursos inactivos. En este caso, CA necesita liberar nodos para evitar el desperdicio de recursos.
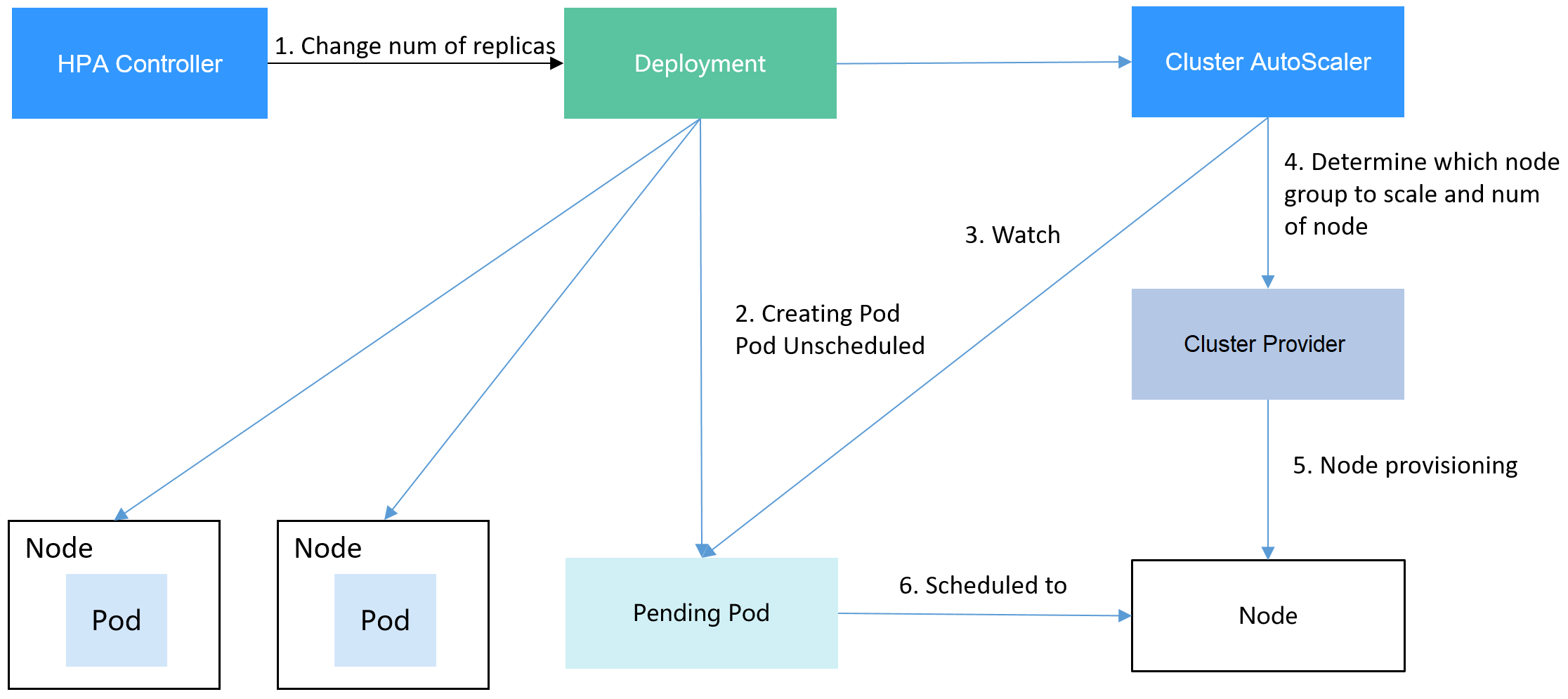
El uso de HPA y CA puede implementar fácilmente el ajuste automático en la mayoría de los escenarios. Además, el proceso de ajuste de nodos y pods se puede observar fácilmente.
En esta sección se utiliza un ejemplo para describir el proceso de ajuste automático con políticas de HPA y CA juntas.
Preparaciones
- Cree un clúster con un nodo. El nodo debe tener 2 núcleos de vCPUs y 4 GiB de memoria, o una especificación más alta, así como una EIP para permitir el acceso externo. Si no hay ninguna EIP vinculada al nodo durante la creación del nodo, puede enlazar manualmente uno en la consola de ECS después de crear el nodo.

- Instalar complementos para el clúster.
- Mecanismos de escalado: complemento de ajuste de nodos
- metrics-server: un agregador de datos de uso de recursos en un clúster de Kubernetes. Puede recopilar datos de medición de los principales recursos de Kubernetes, como pods, nodos, contenedores y Services.
- Inicie sesión en el nodo del clúster y ejecute una aplicación informática intensiva. Cuando un usuario envía una solicitud, el resultado debe calcularse antes de ser devuelto al usuario.
- Cree un archivo de PHP llamado index.php para calcular la raíz cuadrada de la solicitud de 1,000,000 veces antes de devolver OK!.
vi index.php
El contenido del archivo es el siguiente:<?php $x = 0.0001; for ($i = 0; $i <= 1000000; $i++) { $x += sqrt($x); } echo "OK!"; ?> - Compile un archivo Dockerfile para crear una imagen.
vi Dockerfile
El contenido es el siguiente:FROM php:5-apache COPY index.php /var/www/html/index.php RUN chmod a+rx index.php
- Ejecute el siguiente comando para crear una imagen llamada hpa-example con la etiqueta latest.
docker build -t hpa-example:latest .
- (Opcional) Inicie sesión en la consola de SWR, elija Organizations en el panel de navegación y haga clic en Create Organization en la esquina superior derecha para crear una organización.
Omita este paso si ya tiene una organización.
- En el panel de navegación, elija My Images y, a continuación, haga clic en Upload Through Client. En la página mostrada, haga clic en Generate a temporary login command y haga clic en
 para copiar el comando.
para copiar el comando. - Ejecute el comando login copiado en el paso anterior en el nodo del clúster. Si el inicio de sesión es exitoso, se muestra el mensaje "Login Succeeded".
- Etiquete la imagen de ejemplo hpa.
docker tag {Image name 1:Tag 1}/{Image repository address}/{Organization name}/{Image name 2:Tag 2}
- {Image name 1:Tag 1}: nombre y etiqueta de la imagen local que se va a cargar.
- {Image repository address}: el nombre de dominio al final del comando de inicio de sesión en login command. Se puede obtener en la consola de SWR.
- {Organization name}: nombre de la organización creada.
- {Image name 2:Tag 2}: nombre de imagen y etiqueta deseados que se mostrarán en la consola de SWR.
A continuación, se presenta un ejemplo:
docker tag hpa-example:latest swr.ap-southeast-1.myhuaweicloud.com/cloud-develop/hpa-example:latest
- Empuje la imagen al repositorio de imágenes.
docker push {Image repository address}/{Organization name}/{Image name 2:Tag 2}
A continuación, se presenta un ejemplo:
docker push swr.ap-southeast-1.myhuaweicloud.com/cloud-develop/hpa-example:latest
La siguiente información será devuelta tras un empuje exitoso:
6d6b9812c8ae: Pushed ... fe4c16cbf7a4: Pushed latest: digest: sha256:eb7e3bbd*** size: **
Para ver la imagen enviada, vaya a la consola de SWR y actualice la página My Images.
- Cree un archivo de PHP llamado index.php para calcular la raíz cuadrada de la solicitud de 1,000,000 veces antes de devolver OK!.
Creación de un grupo de nodos y una política de escalado de nodos
- Inicie sesión en la consola de CCE, acceda al clúster creado, haga clic en Nodes a la izquierda, haga clic en la ficha Node Pools y haga clic en Create Node Pool en la esquina superior derecha.
- Configure el grupo de nodos.
- Nodes: Establezca el valor de 1 para indicar que se crea un nodo de forma predeterminada cuando se crea un grupo de nodos.
- Specifications: 2 vCPU | 4 GiB
Conservar los valores predeterminados para otros parámetros. Para obtener más información, consulte Creación de un grupo de nodos.
- Busque la fila que contiene el grupo de nodos recién creado y haga clic en Auto Scaling en la esquina superior derecha. Para obtener más información, consulte Creación de una política de escala de nodos. Si el complemento de CCE Cluster Autoscaler no está instalado en el clúster, instálelo primero. Para obtener más información, consulte CCE Cluster Autoscaler.
- Automatic expansión: Si esta función está habilitada, los nodos de un grupo de nodos se agregarán automáticamente en función de la carga del clúster.
- Customized Rule: Haga clic en Customized Rule. En el cuadro de diálogo que se muestra, configure los parámetros. Si la tasa de asignación de CPU es mayor que 70%, se agrega un nodo a cada grupo de nodos asociado. Una política de ajuste de nodos debe estar asociada a un grupo de nodos. Se pueden asociar varios grupos de nodos. Cuando necesite escalar nodos, el nodo con las especificaciones adecuadas se agregará o reducirá del grupo de nodos según el principio de desperdicio mínimo.
- Automatic reducción: Si esta función está habilitada, los nodos de un grupo de nodos se eliminarán automáticamente en función de la carga del clúster. Por ejemplo, activar la reducción cuando la utilización de recursos de nodo es inferior al 50%.
- AS Configuration: Modifique el rango de cantidades de nodo. Durante el escalado automático, el número de nodos en un grupo de nodos está siempre dentro del rango de cantidades configurado.
- AS Object: Habilita el escalado automático para las especificaciones de nodos en un grupo de nodos.
- Haga clic en OK.
Creación de una carga de trabajo
Utilice la imagen hpa-example para crear un Deployment con una réplica. La ruta de la imagen está relacionada con la organización cargada en el repositorio de SWR y necesita ser reemplazada por el valor real.
kind: Deployment apiVersion: apps/v1 metadata: name: hpa-example spec: replicas: 1 selector: matchLabels: app: hpa-example template: metadata: labels: app: hpa-example spec: containers: - name: container-1 image: 'hpa-example:latest' # Replace it with the address of the image you uploaded to SWR. resources: limits: # The value of limits must be the same as that of requests to prevent flapping during scaling. cpu: 500m memory: 200Mi requests: cpu: 500m memory: 200Mi imagePullSecrets: - name: default-secret
A continuación, cree un Service de NodePort para la carga de trabajo de modo que se pueda acceder a la carga de trabajo desde redes externas.
Para permitir el acceso externo a los Services de NodePort, asigne una EIP para el nodo del clúster. Después de la asignación, sincronice los datos del nodo. Para obtener más información, consulte Sincronización de datos con servidores en la nube. Si el nodo ya está enlazado con una EIP, no es necesario crear uno.
Alternativamente, puede crear un Service con un balanceador de carga de ELB para el acceso externo. Para obtener más información, consulte Uso de kubectl para crear un Service (Creación automática de un balanceador de carga compartido).
kind: Service
apiVersion: v1
metadata:
name: hpa-example
spec:
ports:
- name: cce-service-0
protocol: TCP
port: 80
targetPort: 80
nodePort: 31144
selector:
app: hpa-example
type: NodePort Creación de una política de HPA
Cree una política de HPA. Como se muestra a continuación, la política está asociada con la carga de trabajo de ejemplo hpa y el uso de CPU de destino es del 50%.
Hay otras dos anotaciones. Una anotación define los umbrales de la CPU, indicando que el ajuste no se realiza cuando el uso de la CPU está entre el 30% y el 70% para evitar el impacto causado por una ligera fluctuación. La otra es la ventana de tiempo de ajuste, que indica que una vez que la política se ejecuta correctamente, una operación de ajuste no se activará de nuevo en este intervalo de enfriamiento para evitar el impacto causado por la fluctuación a corto plazo.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-policy
annotations:
extendedhpa.metrics: '[{"type":"Resource","name":"cpu","targetType":"Utilization","targetRange":{"low":"30","high":"70"}}]'
extendedhpa.option: '{"downscaleWindow":"5m","upscaleWindow":"3m"}'
spec:
scaleTargetRef:
kind: Deployment
name: hpa-example
apiVersion: apps/v1
minReplicas: 1
maxReplicas: 100
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50 Configure los parámetros de la siguiente manera si está utilizando la consola.

Observación del proceso de escalado automático
- Compruebe el estado del nodo del clúster. En el siguiente ejemplo, hay dos nodos.
# kubectl get node NAME STATUS ROLES AGE VERSION 192.168.0.183 Ready <none> 2m20s v1.17.9-r0-CCE21.1.1.3.B001-17.36.8 192.168.0.26 Ready <none> 55m v1.17.9-r0-CCE21.1.1.3.B001-17.36.8
Verifique la política de HPA. El uso de CPU de la carga de trabajo de destino es 0%.
# kubectl get hpa hpa-policy NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE hpa-policy Deployment/hpa-example 0%/50% 1 100 1 4m
- Ejecute el siguiente comando para acceder a la carga de trabajo. En el siguiente comando, {ip:port} indica la dirección de acceso de la carga de trabajo, que se puede consultar en la página de detalles de la carga de trabajo.
while true;do wget -q -O- http://{ip:port}; done
Si no se muestra ninguna EIP, al nodo del clúster no se le ha asignado ninguna EIP. Asigne una, vincúlela al nodo y sincronice los datos del nodo. Para obtener más información, consulte Sincronización de datos con servidores en la nube.
Observe el proceso de ajuste de la carga de trabajo.
# kubectl get hpa hpa-policy --watch NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE hpa-policy Deployment/hpa-example 0%/50% 1 100 1 4m hpa-policy Deployment/hpa-example 190%/50% 1 100 1 4m23s hpa-policy Deployment/hpa-example 190%/50% 1 100 4 4m31s hpa-policy Deployment/hpa-example 200%/50% 1 100 4 5m16s hpa-policy Deployment/hpa-example 200%/50% 1 100 4 6m16s hpa-policy Deployment/hpa-example 85%/50% 1 100 4 7m16s hpa-policy Deployment/hpa-example 81%/50% 1 100 4 8m16s hpa-policy Deployment/hpa-example 81%/50% 1 100 7 8m31s hpa-policy Deployment/hpa-example 57%/50% 1 100 7 9m16s hpa-policy Deployment/hpa-example 51%/50% 1 100 7 10m hpa-policy Deployment/hpa-example 58%/50% 1 100 7 11mPuede ver que el uso de la CPU de la carga de trabajo es del 190% a 4m23s, lo que excede el valor objetivo. En este caso, se activa el ajuste para expandir la carga de trabajo a cuatro réplicas/pods. En los siguientes minutos, el uso de la CPU no disminuye hasta 7m16s. Esto se debe a que es posible que los nuevos pods no se creen correctamente. La posible causa es que los recursos son insuficientes y los pods están en estado Pending. Durante este período, se agregan nodos.
A 7m16s, el uso de la CPU disminuye, lo que indica que los pods se crean con éxito y comienzan a soportar tráfico. El uso de CPU disminuye a 81% a 8m, aún mayor que el valor objetivo (50%) y el umbral alto (70%). Por lo tanto, se agregan 7 pods a 9m16s, y el uso de CPU disminuye a 51%, que está dentro del rango de 30% a 70%. A partir de entonces, el número de pods sigue siendo 7.
En el siguiente resultado, puede ver el proceso de ajuste de la carga de trabajo y el momento en que la política de HPA entra en vigor.
# kubectl describe deploy hpa-example ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal ScalingReplicaSet 25m deployment-controller Scaled up replica set hpa-example-79dd795485 to 1 Normal ScalingReplicaSet 20m deployment-controller Scaled up replica set hpa-example-79dd795485 to 4 Normal ScalingReplicaSet 16m deployment-controller Scaled up replica set hpa-example-79dd795485 to 7 # kubectl describe hpa hpa-policy ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 20m horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target Normal SuccessfulRescale 16m horizontal-pod-autoscaler New size: 7; reason: cpu resource utilization (percentage of request) above target
Compruebe el número de nodos. El siguiente resultado muestra que se agregan dos nodos.
# kubectl get node NAME STATUS ROLES AGE VERSION 192.168.0.120 Ready <none> 3m5s v1.17.9-r0-CCE21.1.1.3.B001-17.36.8 192.168.0.136 Ready <none> 6m58s v1.17.9-r0-CCE21.1.1.3.B001-17.36.8 192.168.0.183 Ready <none> 18m v1.17.9-r0-CCE21.1.1.3.B001-17.36.8 192.168.0.26 Ready <none> 71m v1.17.9-r0-CCE21.1.1.3.B001-17.36.8
También puede ver el historial de ajuste en la consola. Por ejemplo, la política de CA se ejecuta una vez cuando la tasa de asignación de CPU en el clúster es mayor que 70%, y el número de nodos en el grupo de nodos aumenta de 2 a 3. El nuevo nodo se agrega automáticamente por el autoscaler basado en el estado pendiente de los pods en la fase inicial de HPA.
El proceso de ajuste de nodos es el siguiente:
- Después de que el número de pods cambia a 4, los pods están en estado Pending debido a recursos insuficientes. Como resultado, se activa la política de expansión predeterminada del complemento del autoscaler, y el número de nodos se incrementa en uno.
- El segundo nodo expansión se activa porque la tasa de asignación de CPU en el clúster es superior al 70%. Como resultado, el número de nodos aumenta en uno, que se registra en el historial de ajuste en la consola. El escalado basado en la tasa de asignación garantiza que el clúster tenga suficientes recursos.
- Deje de acceder a la carga de trabajo y compruebe el número de pods.
# kubectl get hpa hpa-policy --watch NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE hpa-policy Deployment/hpa-example 50%/50% 1 100 7 12m hpa-policy Deployment/hpa-example 21%/50% 1 100 7 13m hpa-policy Deployment/hpa-example 0%/50% 1 100 7 14m hpa-policy Deployment/hpa-example 0%/50% 1 100 7 18m hpa-policy Deployment/hpa-example 0%/50% 1 100 3 18m hpa-policy Deployment/hpa-example 0%/50% 1 100 3 19m hpa-policy Deployment/hpa-example 0%/50% 1 100 3 19m hpa-policy Deployment/hpa-example 0%/50% 1 100 3 19m hpa-policy Deployment/hpa-example 0%/50% 1 100 3 19m hpa-policy Deployment/hpa-example 0%/50% 1 100 3 23m hpa-policy Deployment/hpa-example 0%/50% 1 100 3 23m hpa-policy Deployment/hpa-example 0%/50% 1 100 1 23m
Puede ver que el uso de la CPU es del 21% a 13m. El número de pods se reduce a 3 a 18m, y luego se reduce a 1 a 23m.
En el siguiente resultado, puede ver el proceso de ajuste de la carga de trabajo y el momento en que la política de HPA entra en vigor.
# kubectl describe deploy hpa-example ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal ScalingReplicaSet 25m deployment-controller Scaled up replica set hpa-example-79dd795485 to 1 Normal ScalingReplicaSet 20m deployment-controller Scaled up replica set hpa-example-79dd795485 to 4 Normal ScalingReplicaSet 16m deployment-controller Scaled up replica set hpa-example-79dd795485 to 7 Normal ScalingReplicaSet 6m28s deployment-controller Scaled down replica set hpa-example-79dd795485 to 3 Normal ScalingReplicaSet 72s deployment-controller Scaled down replica set hpa-example-79dd795485 to 1 # kubectl describe hpa hpa-policy ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 20m horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target Normal SuccessfulRescale 16m horizontal-pod-autoscaler New size: 7; reason: cpu resource utilization (percentage of request) above target Normal SuccessfulRescale 6m45s horizontal-pod-autoscaler New size: 3; reason: All metrics below target Normal SuccessfulRescale 90s horizontal-pod-autoscaler New size: 1; reason: All metrics below target
También puede ver el historial de ejecución de políticas de HPA en la consola. Espere hasta que se reduzca el nodo.
La razón por la que los otros dos nodos en el grupo de nodos no se reducen es que ambos tienen pods en el espacio de nombres del sistema kube (y estos pods no son creados por DaemonSets). Para obtener más información, consulte Mecanismos de escala de nodos.
Resumen
El uso de HPA y CA puede implementar fácilmente el ajuste automático en la mayoría de los escenarios. Además, el proceso de ajuste de nodos y pods se puede observar fácilmente.




