
¿Qué debo hacer si falla la programación de pods?
Localización de fallas
Si el pod se encuentra en el estado Pending y el evento contiene información de falla de programación de pod, localice la causa basándose en la información del evento. Para obtener más información acerca de cómo ver eventos, consulte ¿Cómo uso eventos para corregir cargas de trabajo anormales?.
Proceso de solución de problemas
Determine la causa basándose en la información del evento, tal como aparece en Tabla 1.
| Información del evento | Motivo y solución |
|---|---|
| no nodes available to schedule pods. | No hay ningún nodo disponible en el clúster. Concepto de comprobación 1: Si un nodo está disponible en el clúster |
| 0/2 nodes are available: 2 Insufficient cpu. 0/2 nodes are available: 2 Insufficient memory. | Los recursos de nodo (CPU y memoria) son insuficientes. Concepto de comprobación 2: Si los recursos de nodo (CPU y memoria) son suficientes |
| 0/2 nodes are available: 1 node(s) didn't match node selector, 1 node(s) didn't match pod affinity rules, 1 node(s) didn't match pod affinity/anti-affinity. | Las configuraciones de afinidad de nodo y pod son mutuamente excluyentes. Ningún nodo cumple con los requisitos del pod. Concepto de comprobación 3: Configuración de afinidad y antiafinidad de la carga de trabajo |
| 0/2 nodes are available: 2 node(s) had volume node affinity conflict. | El volumen de EVS montado en el pod y el nodo no están en la misma AZ. Concepto de comprobación 4: Si el volumen y el nodo de la carga de trabajo residen en la misma AZ |
| 0/1 nodes are available: 1 node(s) had taints that the pod didn't tolerate. | Existen marcas en el nodo, pero el pod no puede tolerar estas manchas. Concepto de comprobación 5: Toleración a la mancha de los pods |
| 0/7 nodes are available: 7 Insufficient ephemeral-storage. | El espacio de almacenamiento efímero del nodo es insuficiente. |
| 0/1 nodes are available: 1 everest driver not found at node | El controlador everest-csi en el nodo no está en el estado de ejecución. Concepto de comprobación 7: Si everest funciona correctamente |
| Failed to create pod sandbox: ... Create more free space in thin pool or use dm.min_free_space option to change behavior | El espacio de thin pool del nodo es insuficiente. |
Concepto de comprobación 1: Si un nodo está disponible en el clúster
Inicie sesión en la consola de CCE y compruebe si el estado del nodo es Available. Alternativamente, ejecute el siguiente comando para comprobar si el estado del nodo es de Ready:
$ kubectl get node NAME STATUS ROLES AGE VERSION 192.168.0.37 Ready <none> 21d v1.19.10-r1.0.0-source-121-gb9675686c54267 192.168.0.71 Ready <none> 21d v1.19.10-r1.0.0-source-121-gb9675686c54267
Si el estado de todos los nodos es Not Ready, no hay ningún nodo disponible en el clúster.
Solución
- Agregue un nodo. Si no se configura una política de afinidad para la carga de trabajo, el pod se migrará automáticamente al nuevo nodo para garantizar que los servicios se ejecuten correctamente.
- Localice el nodo no disponible y rectifique el error. Para obtener más información, véase ¿Qué debo hacer si un clúster está disponible pero algunos nodos no están disponibles?.
- Restablezca el nodo no disponible. Para obtener más información, consulte Restablecer un nodo.
Concepto de comprobación 2: Si los recursos de nodo (CPU y memoria) son suficientes
0/2 nodes are available: 2 Insufficient cpu. Esto significa que no quedan CPU suficientes.
0/2 nodes are available: 2 Insufficient memory. Esto significa la memoria insuficiente.
Si los recursos solicitados por el pod exceden los recursos asignables del nodo donde se ejecuta el pod, el nodo no puede proporcionar los recursos requeridos para ejecutar nuevos pods y la planificación del pod en el nodo fallará definitivamente.
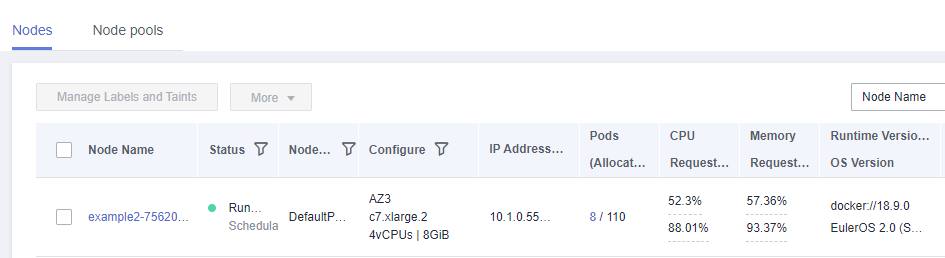
Si el número de recursos que se pueden asignar a un nodo es menor que el número de recursos que solicita un pod, el nodo no cumple los requisitos de recursos del pod. Como resultado, la programación falla.
Solución
Agregar nodos al clúster. La ampliación es la solución común a la insuficiencia de recursos.
Concepto de comprobación 3: Configuración de afinidad y antiafinidad de la carga de trabajo
Las políticas de afinidad inapropiadas causarán un error en la programación de pods.
Ejemplo:
Se establece una relación antiafinidad entre la carga de trabajo 1 y la carga de trabajo 2. La carga de trabajo 1 se despliega en el nodo 1 mientras que la carga de trabajo 2 se despliega en el nodo 2.
Cuando intenta desplegar la carga de trabajo 3 en el nodo 1 y establecer una relación de afinidad con la carga de trabajo 2, se produce un conflicto, lo que resulta en un error de despliegue de la carga de trabajo.
0/2 nodes are available: 1 node(s) no coincidió con node selector, 1 nodo (s) no coincidió con pod affinity rules, 1 nodo (s) no coincidió con pod affinity/anti-affinity.
- node selector indica que no se cumple la afinidad del nodo.
- pod affinity rules indican que no se cumple la afinidad del pod.
- pod affinity/anti-affinity indica que no se cumple la afinidad/antiafinidad del pod.
Solución
- Al agregar la afinidad de carga de trabajo-carga de trabajo y las políticas de afinidad de carga de trabajo-nodo, asegúrese de que los dos tipos de políticas no entren en conflicto. De lo contrario, el despliegue de carga de trabajo fallará.
- Si la carga de trabajo tiene una política de afinidad de nodo, asegúrese de que supportContainer en la etiqueta del nodo de afinidad está establecido en true. De lo contrario, los pods no se pueden programar en el nodo de afinidad y se genera el siguiente evento:
No nodes are available that match all of the following predicates: MatchNode Selector, NodeNotSupportsContainer
Si el valor es de false, la programación falla.
Concepto de comprobación 4: Si el volumen y el nodo de la carga de trabajo residen en la misma AZ
0/2 nodes are available: 2 node(s) had volume node affinity conflict. Se produce un conflicto de afinidad entre volúmenes y nodos. Como resultado, la programación falla.
Esto se debe a que los discos de EVS no se pueden conectar a los nodos entre las AZ. Por ejemplo, si el volumen de EVS se encuentra en AZ 1 y el nodo se encuentra en AZ 2, la planificación falla.
El volumen de EVS creado en CCE tiene la configuración de afinidad de forma predeterminada, como se muestra a continuación.
kind: PersistentVolume apiVersion: v1 metadata: name: pvc-c29bfac7-efa3-40e6-b8d6-229d8a5372ac spec: ... nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: failure-domain.beta.kubernetes.io/zone operator: In values: - ap-southeast-1a
Solución
En la AZ donde reside el nodo de la carga de trabajo, cree un volumen. Alternativamente, cree una carga de trabajo idéntica y seleccione un volumen de almacenamiento en la nube asignado automáticamente.
Concepto de comprobación 5: Toleración a la mancha de los pods
0/1 nodes are available: 1 node(s) had taints that the pod didn't tolerate. Esto significa que el nodo está contaminado y el pod no se puede programar para el nodo.
Comprueba las manchas en el nodo. Si se muestra la siguiente información, existen manchas en el nodo:
$ kubectl describe node 192.168.0.37
Name: 192.168.0.37
...
Taints: key1=value1:NoSchedule
... En algunos casos, el sistema agrega automáticamente una mancha a un nodo. Las manchas incorporadas actuales incluyen:
- node.kubernetes.io/not-ready: El nodo no está listo.
- node.kubernetes.io/unreachable: El controlador de nodo no puede acceder al nodo.
- node.kubernetes.io/memory-pressure: El nodo tiene presión de memoria.
- node.kubernetes.io/disk-pressure: El nodo tiene presión de disco. Siga las instrucciones descritas en Concepto de comprobación 4: Si el espacio en disco del nodo es insuficiente para manejarlo.
- node.kubernetes.io/pid-pressure: El nodo está bajo presión de PID. Siga las instrucciones en Cambio de límites del ID de proceso (kernel.pid_max) para manejarlo.
- node.kubernetes.io/network-unavailable: La red del nodo no está disponible.
- node.kubernetes.io/unschedulable: No se puede programar el nodo.
- node.cloudprovider.kubernetes.io/uninitialized: Si se especifica un controlador de plataforma en la nube externo cuando se inicia kubelet, kubelet agrega una mancha al nodo actual y lo marca como no disponible. Después de que cloud-controller-manager inicialice el nodo, kubelet elimina la mancha.
Solución
Para programar el pod en el nodo, utilice uno de los métodos siguientes:
- Si un usuario agrega la mancha, puede eliminar la mancha en el nodo. Si la mancha es agregada automáticamente por el sistema, la mancha se eliminará automáticamente después de que se corrija la falla.
- Especifique una tolerancia para el pod que contiene la mancha. Para obtener más información, consulte Manchas y tolerancias.
apiVersion: v1 kind: Pod metadata: name: nginx spec: containers: - name: nginx image: nginx:alpine tolerations: - key: "key1" operator: "Equal" value: "value1" effect: "NoSchedule"
Concepto de comprobación 6: Uso del volumen efímero
0/7 nodes are available: 7 Insufficient ephemeral-storage. Esto significa el almacenamiento efímero insuficiente del nodo.
Compruebe si el tamaño del volumen efímero en el pod es limitado. Si el tamaño del volumen efímero requerido por la aplicación excede la capacidad existente del nodo, la aplicación no se puede programar. Para resolver este problema, cambie el tamaño del volumen efímero o amplíe la capacidad del disco del nodo.
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
ephemeral-storage: "2Gi"
limits:
ephemeral-storage: "4Gi"
volumeMounts:
- name: ephemeral
mountPath: "/tmp"
volumes:
- name: ephemeral
emptyDir: {} Concepto de comprobación 7: Si everest funciona correctamente
0/1 nodes are available: 1 everest driver not found at node. Esto significa que el everest-csi-driver de everest no se inicia correctamente en el nodo.
Compruebe el daemon llamado everest-csi-driver en el espacio de nombres del sistema kube y verifique si el pod se ha iniciado correctamente. Si no es así, elimine el pod. El demonio reiniciará el pod.
Concepto de comprobación 8: Espacio de thin pool
Un disco de datos de 100 GB dedicado a Docker está montado en el nuevo nodo. Para obtener más información, consulte Asignación de espacio en disco de datos. Si el espacio en disco de datos es insuficiente, no se puede crear el pod.
Solución 1
Puede ejecutar el siguiente comando para borrar las imágenes de Docker no utilizadas:
docker system prune -a

Este comando eliminará todas las imágenes de Docker no utilizadas. Ejercite precaución cuando ejecute este comando.
Solución 2
También puede ampliar la capacidad del disco mediante el procedimiento siguiente:
- Amplíe la capacidad del disco de datos en la consola de EVS.
- Inicie sesión en la consola de CCE y haga clic en el clúster. En el panel de navegación, elija Nodes. Haga clic en More > Sync Server Data en la fila que contiene el nodo de destino.
- Inicie sesión en el nodo de destino.
- Ejecute el comando lsblk para comprobar la información del dispositivo de bloque del nodo.
Un disco de datos se divide en función del Rootfs de almacenamiento contenedor:
- Overlayfs: No se asigna ningún thin pool independiente. Los datos de imagen se almacenan en el disco dockersys.
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 50G 0 disk └─sda1 8:1 0 50G 0 part / sdb 8:16 0 200G 0 disk ├─vgpaas-dockersys 253:0 0 90G 0 lvm /var/lib/docker # Space used by Docker. └─vgpaas-kubernetes 253:1 0 10G 0 lvm /mnt/paas/kubernetes/kubelet # Space used by Kubernetes.
Ejecute los siguientes comandos en el nodo para agregar la nueva capacidad de disco al disco dockersys:
pvresize /dev/sdb lvextend -l+100%FREE -n vgpaas/dockersys resize2fs /dev/vgpaas/dockersys
- Devicemapper: Se asigna un thin pool para almacenar datos de imagen.
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 50G 0 disk └─sda1 8:1 0 50G 0 part / sdb 8:16 0 200G 0 disk ├─vgpaas-dockersys 253:0 0 18G 0 lvm /var/lib/docker ├─vgpaas-thinpool_tmeta 253:1 0 3G 0 lvm │ └─vgpaas-thinpool 253:3 0 67G 0 lvm # Thin pool space. │ ... ├─vgpaas-thinpool_tdata 253:2 0 67G 0 lvm │ └─vgpaas-thinpool 253:3 0 67G 0 lvm │ ... └─vgpaas-kubernetes 253:4 0 10G 0 lvm /mnt/paas/kubernetes/kubelet
- Ejecute los siguientes comandos en el nodo para agregar la nueva capacidad de disco al disco thinpool:
pvresize /dev/sdb lvextend -l+100%FREE -n vgpaas/thinpool
- Ejecute los siguientes comandos en el nodo para agregar la nueva capacidad de disco al disco dockersys:
pvresize /dev/sdb lvextend -l+100%FREE -n vgpaas/dockersys resize2fs /dev/vgpaas/dockersys
- Ejecute los siguientes comandos en el nodo para agregar la nueva capacidad de disco al disco thinpool:
- Overlayfs: No se asigna ningún thin pool independiente. Los datos de imagen se almacenan en el disco dockersys.




