
¿Qué debo hacer si un clúster está disponible pero algunos nodos no están disponibles?
Si el estado del clúster está disponible pero algunos nodos del clúster no están disponibles, realice las siguientes operaciones para rectificar el error:
Mecanismo para detectar la indisponibilidad de nodos
Kubernetes proporciona el mecanismo de latidos para ayudarlo a determinar la disponibilidad de los nodos. Para obtener detalles sobre el mecanismo y el intervalo, consulte Latidos cardíacos.
Localización de fallas
Los métodos de resolución de problemas se ordenan en función de la probabilidad de ocurrencia de las posibles causas. Se recomienda comprobar las posibles causas de alta probabilidad a baja probabilidad para localizar rápidamente la causa del problema.
Si la falla persiste después de rectificar una posible causa, compruebe otras posibles causas.
- Concepto de comprobación 1: Si el nodo está sobrecargado
- Concepto de comprobación 2: Si el ECS está eliminado o defectuoso
- Concepto de comprobación 3: Si puede iniciar sesión en el ECS
- Concepto de comprobación 4: Si el grupo de seguridad está modificado
- Concepto de comprobación 5: Si las reglas del grupo de seguridad contienen la política de grupo de seguridad para la comunicación entre el nodo principal y el nodo de trabajo
- Concepto de comprobación 6: Si el disco es anormal
- Concepto de comprobación 7: Si los componentes internos son normales
- Concepto de comprobación 8: Si la dirección DNS es correcta
- Concepto de comprobación 9: Si se elimina el disco vdb en el nodo
- Concepto de comprobación 10: Si el servicio Docker es normal
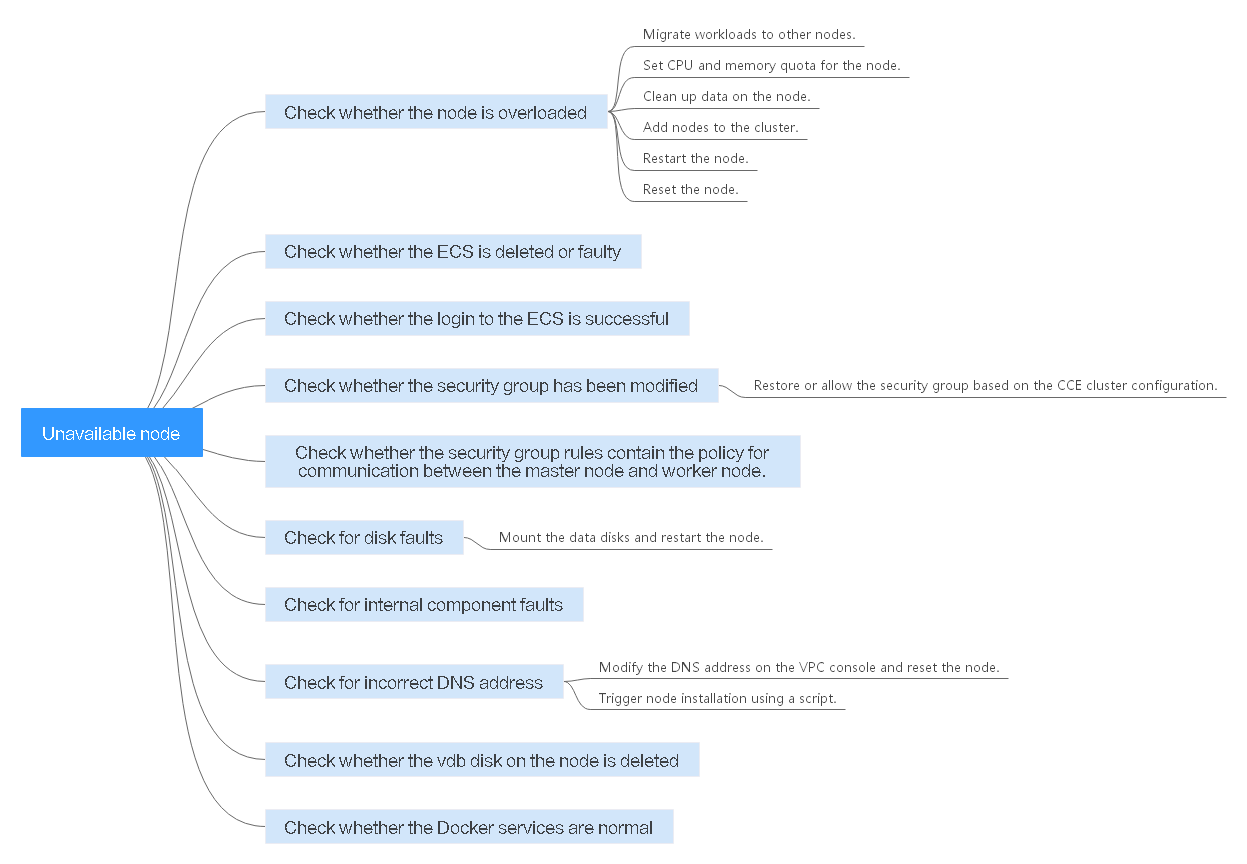
Concepto de comprobación 1: Si el nodo está sobrecargado
Síntoma
La conexión de nodo en el clúster es anormal. Varios nodos informan de errores de escritura, pero los servicios no se ven afectados.
Localización de fallas
- Inicie sesión en la consola de CCE y haga clic en el clúster. En el panel de navegación, elija Nodes. Haga clic en Monitor en la fila del nodo no disponible.
- En la parte superior de la página mostrada, haga clic en View More para ir a la consola de AOM y ver los registros de supervisión históricos.
Un uso demasiado alto de CPU o memoria del nodo dará como resultado una alta latencia de red o sistema de activación OOM. Por lo tanto, el nodo se muestra como no disponible.
Solución
- Se recomienda migrar servicios para reducir las cargas de trabajo en el nodo y establecer el límite superior de recursos para las cargas de trabajo.
- Borre los datos de los nodos de CCE en el clúster.
- Limite la CPU y las cuotas de memoria de cada contenedor.
- Agregue más nodos al clúster.
- También puede reiniciar el nodo en la consola de ECS.
- Agregue los nodos para desplegar contenedores con uso intensivo de memoria por separado.
- Restablezca el nodo. Para obtener más información, consulte Restablecer un nodo.
Una vez que el nodo esté disponible, se restaura la carga de trabajo.
Concepto de comprobación 2: Si el ECS está eliminado o defectuoso
- Compruebe si el clúster está disponible.
Inicie sesión en la consola de CCE y compruebe si el clúster está disponible.
- Si el clúster no está disponible, por ejemplo, se produce un error, consulte ¿Cómo puedo rectificar la falla cuando el estado del clúster no está disponible?.
- Si el clúster se está ejecutando pero algunos nodos del clúster no están disponibles, vaya a 2.
- Inicie sesión en la consola de ECS y vea el estado de ECS.
- Si el estado de ECS es Deleted, vuelva a la consola de CCE, elimine el nodo correspondiente de la lista de nodos del clúster y, a continuación, cree otro.
- Si el estado de ECS es Stopped o Frozen, restaure el ECS. Se tarda aproximadamente 3 minutos en restaurar el ECS.
- Si el ECS es Faulty, reinicie el ECS para rectificar la falla.
- Si el estado del ECS es Running, inicie sesión en el ECS para localizar la falla de acuerdo con Concepto de comprobación 7: Si los componentes internos son normales.
Concepto de comprobación 3: Si puede iniciar sesión en el ECS
- Inicie sesión en la consola de ECS.
- Compruebe si el nombre de nodo que se muestra en la página es el mismo que en la máquina virtual y si la contraseña o la clave se pueden utilizar para iniciar sesión en el nodo. Figura 2 Comprobación del nombre de nodo mostrado en la página
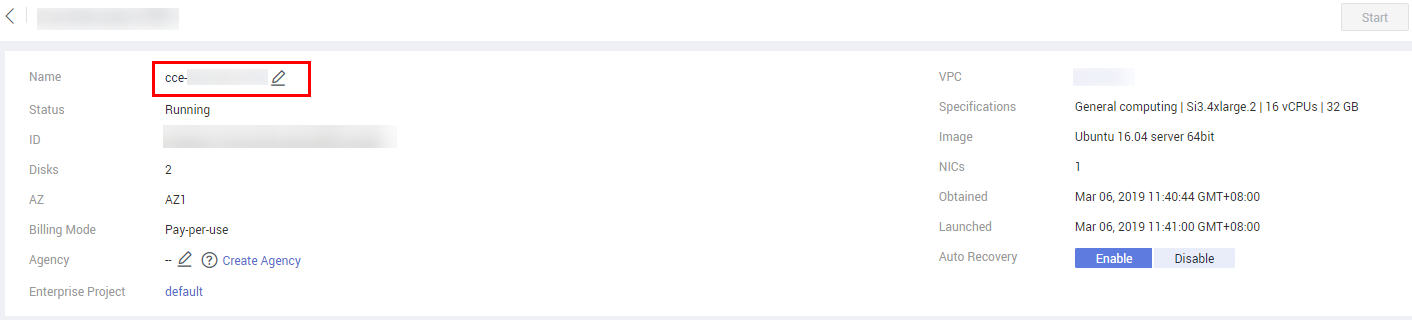 Figura 3 Comprobación del nombre del nodo en la máquina virtual y si el nodo puede iniciar sesión en
Figura 3 Comprobación del nombre del nodo en la máquina virtual y si el nodo puede iniciar sesión en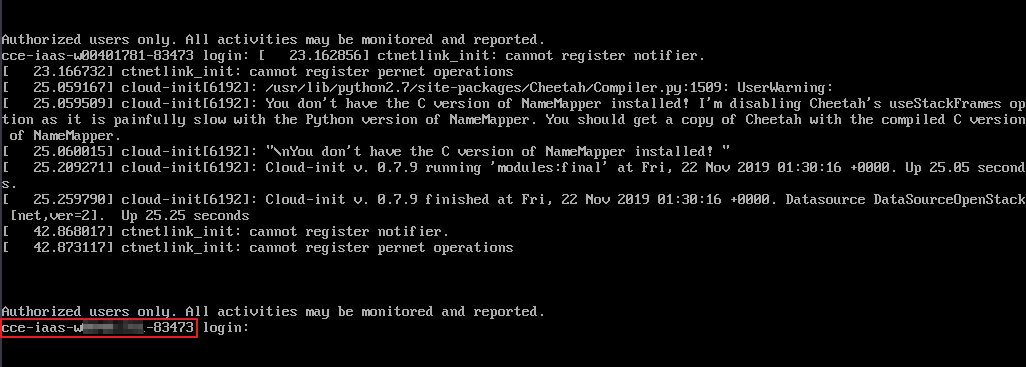
Si los nombres de nodo son inconsistentes y la contraseña y la clave no se pueden usar para iniciar sesión en el nodo, se produjeron problemas de Cloud-Init cuando se creó un ECS. En este caso, reinicie el nodo y envíe un ticket de servicio al personal de ECS para localizar la causa raíz.
Concepto de comprobación 4: Si el grupo de seguridad está modificado
Inicie sesión en la consola de VPC. En el panel de navegación, elija Access Control > Security Groups y busque el grupo de seguridad del nodo principal del clúster.
El nombre de este grupo de seguridad tiene el formato de Cluster name-cce-control-ID. Se puede buscar el grupo de seguridad por cluster name.
Compruebe si se modifican las reglas del grupo de seguridad. Para obtener más información, véase Configuración de reglas de grupo de seguridad de clúster.
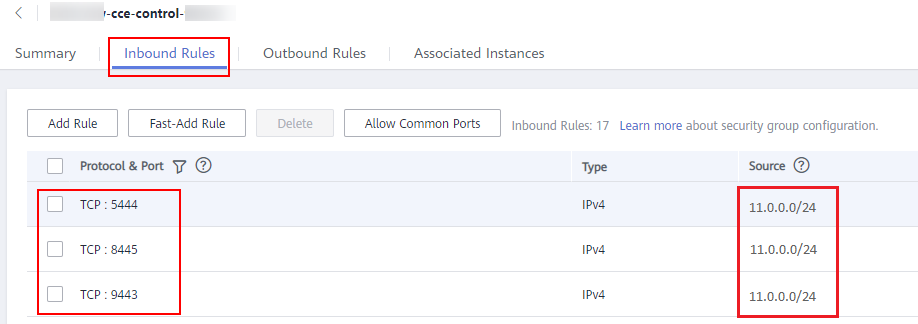
Concepto de comprobación 5: Si las reglas del grupo de seguridad contienen la política de grupo de seguridad para la comunicación entre el nodo principal y el nodo de trabajo
Compruebe si existe una política de grupo de seguridad de este tipo.
Cuando se agrega un nodo a un clúster existente, si se agrega un bloque CIDR extendido a la VPC correspondiente a la subred y la subred es un bloque CIDR extendido, necesita agregar las siguientes tres reglas de grupo de seguridad al grupo de seguridad del nodo principal (el nombre del grupo tiene el formato Cluster name-cce-control-Random number). Estas reglas garantizan que los nodos agregados al clúster estén disponibles. (Este paso no es necesario si se ha agregado un bloque CIDR extendido a la VPC durante la creación del clúster.)
Para obtener más información acerca de la seguridad, consulte Configuración de reglas de grupo de seguridad de clúster.
Concepto de comprobación 6: Si el disco es anormal
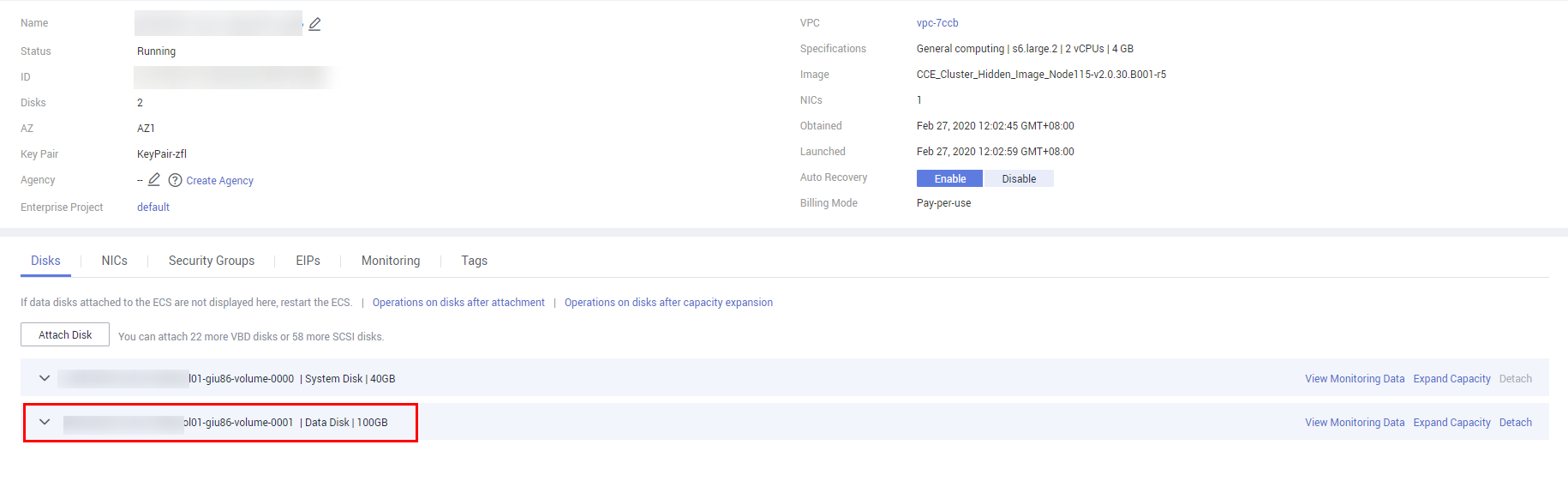
Un disco de datos de 100 GB dedicado a Docker está conectado al nuevo nodo. Si el disco de datos se desinstala o se daña, el servicio Docker se vuelve anormal y el nodo no está disponible.
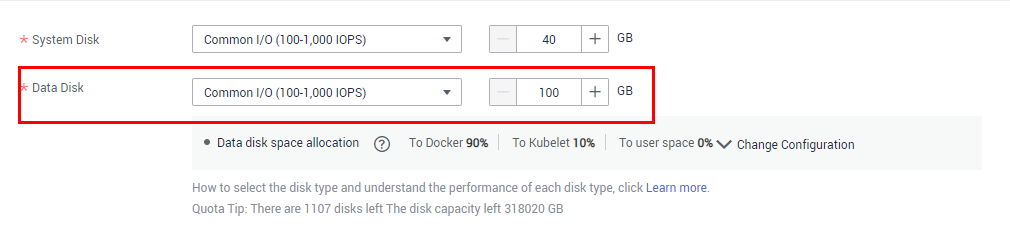
Haga clic en el nombre del nodo para comprobar si se desinstala el disco de datos montado en el nodo. Si se desinstala el disco, vuelva a montar un disco de datos en el nodo y reinicie el nodo. Entonces el nodo puede ser recuperado.
Concepto de comprobación 7: Si los componentes internos son normales
- Inicie sesión en el ECS donde se encuentra el nodo no disponible.
- Ejecute el siguiente comando para comprobar si los componentes PaaS son normales:
systemctl status kubelet
Si el comando se ejecuta correctamente, el estado de cada componente se muestra como active, como se muestra en la siguiente figura.

Si el estado del componente no es active, ejecute los siguientes comandos (usando el componente defectuoso canal como ejemplo):
Ejecute systemctl restart canal para reiniciar el componente.
Después de reiniciar el componente, ejecute systemctl status canal para comprobar el estado.
- Si el comando de reinicio no se ejecuta, ejecute el siguiente comando para comprobar el estado de ejecución del proceso monitrc:
ps -ef | grep monitrc
Si el proceso monitrc existe, ejecute el siguiente comando para eliminar este proceso. El proceso monitrc se reiniciará automáticamente después de que se elimine.
kill -s 9 `ps -ef | grep monitrc | grep -v grep | awk '{print $2}'`
Concepto de comprobación 8: Si la dirección DNS es correcta
- Después de iniciar sesión en el nodo, compruebe si se registra algún error de resolución de nombres de dominio en el archivo /var/log/cloud-init-output.log.
cat /var/log/cloud-init-output.log | grep resolv
Si el resultado del comando contiene la siguiente información, el nombre de dominio no se puede resolver:
Could not resolve host: test.obs.ap-southeast-1.myhuaweicloud.com; Unknown error
- En el nodo, haga ping al nombre de dominio que no se puede resolver en el paso anterior para comprobar si el nombre de dominio se puede resolver en el nodo.
ping test.obs.ap-southeast-1.myhuaweicloud.com
- Si no, el DNS no puede resolver la dirección IP. Compruebe si la dirección de DNS del archivo /etc/resolv.conf es la misma que la configurada en la subred de VPC. En la mayoría de los casos, la dirección DNS del archivo está configurada incorrectamente. Como resultado, el nombre de dominio no se puede resolver. Corrija la configuración de DNS de la subred de VPC y restablezca el nodo.
- Si es así, la configuración de la dirección de DNS es correcta. Comprueba si hay otras fallas.
Concepto de comprobación 9: Si se elimina el disco vdb en el nodo
Si se elimina el disco vdb de un nodo, puede consultar este tema para restaurar el nodo.
Concepto de comprobación 10: Si el servicio Docker es normal
- Ejecute el siguiente comando para comprobar si el servicio Docker se está ejecutando:
systemctl status docker
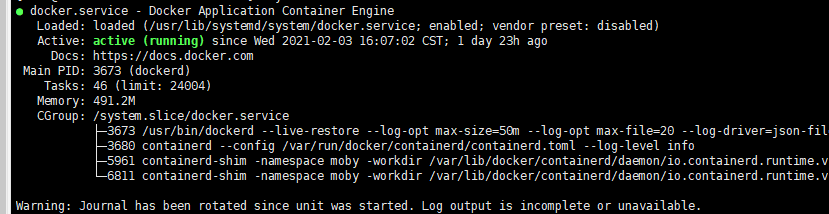
Si el comando falla o el estado del servicio Docker no está activo, localice la causa o póngase en contacto con el soporte técnico si es necesario.
- Ejecute el siguiente comando para comprobar el número de contenedores en el nodo:
docker ps -a | wc -l
Si el comando se suspende, la ejecución del comando tarda mucho tiempo, o hay más de 1000 contenedores anormales, compruebe si las cargas de trabajo se crean y eliminan repetidamente. Si con frecuencia se crean y eliminan un gran número de recipientes, puede ocurrir un gran número de recipientes anormales y no pueden despejarse de manera oportuna.
En este caso, detenga la creación y eliminación repetidas de la carga de trabajo o utilice más nodos para compartir la carga de trabajo. Generalmente, los nodos se restaurarán después de un periodo de tiempo. Si es necesario, ejecute el comando docker rm {container_id} para borrar manualmente los contenedores anormales.




