
¿Qué debo hacer si falla el inicio del contenedor?
Localización de fallas
En la página de detalles de una carga de trabajo, si se muestra un evento que indica que el contenedor no se inicia, realice los siguientes pasos para localizar el error:
- Inicie sesión en el nodo donde se encuentra la carga de trabajo anormal.
- Compruebe el ID del contenedor donde el pod de carga de trabajo sale de forma anormal.
docker ps -a | grep $podName
- Vea los logs del contenedor correspondiente.
docker logs $containerID
Rectifique la falla de la carga de trabajo basado en logs.
- Compruebe los logs de errores.
cat /var/log/messages | grep $containerID | grep oom
Compruebe si OOM del sistema se activa en función de los logs.
Proceso de solución de problemas
Determine la causa basándose en la información del evento, tal como aparece en Tabla 1.
| Log o evento | Motivo y solución |
|---|---|
| El log contiene la salida (0). | No existe ningún proceso en el contenedor. Compruebe si el contenedor está funcionando correctamente. |
| Información del evento: Liveness probe failed: Get http... El log contiene la salida (137). | La comprobación de estado falla. Concepto de comprobación 2: Si no se realiza la comprobación de estado (Código de salida: 137) |
| Información del evento: Thin Pool tiene 15991 bloques de datos libres que son menos que el mínimo requerido 16383 bloques de datos libres. Cree más espacio libre en el thin pool o use la opción dm.min_free_space para cambiar el comportamiento | El espacio en disco es insuficiente. Limpie el espacio en disco. Concepto de comprobación 3: Si el espacio en disco del contenedor es insuficiente |
| La palabra clave OOM existe en el log. | La memoria es insuficiente. Concepto de comprobación 4: Si se ha alcanzado el límite superior de los recursos de contenedores |
| Dirección ya en uso | Se produce un conflicto entre los puertos contenedor en el pod. |
Además de las posibles causas precedentes, hay otras tres causas posibles:
- Concepto de comprobación 7: Si el comando de inicio del contenedor está correctamente configurado
- Concepto de comprobación 8: Si la versión de la sonda de Java es la última
- Concepto de comprobación 9: Si el servicio de usuario tiene un error
- Utilice la imagen correcta cuando cree una carga de trabajo en un nodo Arm.
Concepto de comprobación 1: Si hay procesos que siguen ejecutándose en el contenedor (Código de salida: 0)
- Inicie sesión en el nodo donde se encuentra la carga de trabajo anormal.
- Vea el estado del contenedor.
docker ps -a | grep $podName
Ejemplo:

Si no existe ningún proceso en ejecución en el contenedor, se muestra el código de estado Exited (0).
Concepto de comprobación 2: Si no se realiza la comprobación de estado (Código de salida: 137)
La comprobación de estado configurada para una carga de trabajo se realiza en los servicios periódicamente. Si se produce una excepción, el pod informa de un evento y el pod no se reinicia.
Si se configura la comprobación de estado de tipo de vida (exploración de vida de carga de trabajo) para la carga de trabajo y el número de fallas de comprobación de estado excede el umbral, se reiniciarán los contenedores en el pod. En la página de detalles de la carga de trabajo, si los eventos de Kubernetes contienen Liveness probe failed: Get http..., se produce un error en la comprobación de estado.
Solución
En la página de detalles de la carga de trabajo, elija Upgrade > Advanced Settings > Health Check de estado para comprobar si la política de comprobación de estado está configurada correctamente y si los servicios son normales.
Concepto de comprobación 3: Si el espacio en disco del contenedor es insuficiente
El siguiente mensaje hace referencia al disco de Thin Pool asignado desde el disco de Docker seleccionado durante la creación del nodo. Puede ejecutar el comando lvs como usuario root para ver el uso actual del disco.
Thin Pool has 15991 free data blocks which are less than minimum required 16383 free data blocks. Create more free space in thin pool or use dm.min_free_space option to change behavior

Solución
Solución 1
Puede ejecutar el siguiente comando para borrar las imágenes basura no utilizadas:
docker system prune -a

Este comando eliminará todas las imágenes de Docker no utilizadas. Ejercite precaución cuando ejecute este comando.
Solución 2
También puede ampliar la capacidad del disco mediante el procedimiento siguiente:
- Amplíe la capacidad del disco de datos en la consola de EVS.
- Inicie sesión en la consola de CCE y haga clic en el clúster. En el panel de navegación, elija Nodes. Haga clic en More > Sync Server Data en la fila que contiene el nodo de destino.
- Inicie sesión en el nodo de destino.
- Ejecute el comando lsblk para comprobar la información del dispositivo de bloque del nodo.
Un disco de datos se divide en función del Rootfs de almacenamiento contenedor:
- Overlayfs: No se asigna ningún thin pool independiente. Los datos de imagen se almacenan en el disco dockersys.
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 50G 0 disk └─sda1 8:1 0 50G 0 part / sdb 8:16 0 200G 0 disk ├─vgpaas-dockersys 253:0 0 90G 0 lvm /var/lib/docker # Space used by Docker. └─vgpaas-kubernetes 253:1 0 10G 0 lvm /mnt/paas/kubernetes/kubelet # Space used by Kubernetes.
Ejecute los siguientes comandos en el nodo para agregar la nueva capacidad de disco al disco dockersys:
pvresize /dev/sdb lvextend -l+100%FREE -n vgpaas/dockersys resize2fs /dev/vgpaas/dockersys
- Devicemapper: Se asigna un thin pool para almacenar datos de imagen.
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 50G 0 disk └─sda1 8:1 0 50G 0 part / sdb 8:16 0 200G 0 disk ├─vgpaas-dockersys 253:0 0 18G 0 lvm /var/lib/docker ├─vgpaas-thinpool_tmeta 253:1 0 3G 0 lvm │ └─vgpaas-thinpool 253:3 0 67G 0 lvm # Thin pool space. │ ... ├─vgpaas-thinpool_tdata 253:2 0 67G 0 lvm │ └─vgpaas-thinpool 253:3 0 67G 0 lvm │ ... └─vgpaas-kubernetes 253:4 0 10G 0 lvm /mnt/paas/kubernetes/kubelet
- Ejecute los siguientes comandos en el nodo para agregar la nueva capacidad de disco al disco thinpool:
pvresize /dev/sdb lvextend -l+100%FREE -n vgpaas/thinpool
- Ejecute los siguientes comandos en el nodo para agregar la nueva capacidad de disco al disco dockersys:
pvresize /dev/sdb lvextend -l+100%FREE -n vgpaas/dockersys resize2fs /dev/vgpaas/dockersys
- Ejecute los siguientes comandos en el nodo para agregar la nueva capacidad de disco al disco thinpool:
- Overlayfs: No se asigna ningún thin pool independiente. Los datos de imagen se almacenan en el disco dockersys.
Concepto de comprobación 4: Si se ha alcanzado el límite superior de los recursos de contenedores
Si se ha alcanzado el límite superior de los recursos del contenedor, OOM se mostrará en los detalles del evento, así como en el log:
cat /var/log/messages | grep 96feb0a425d6 | grep oom

Cuando se crea una carga de trabajo, si los recursos solicitados superan el límite superior configurado, se activa la OOM del sistema y el contenedor sale inesperadamente.
Concepto de comprobación 5: Si los límites de recursos están configurados incorrectamente para el contenedor
Si los límites de recursos establecidos para el contenedor durante la creación de la carga de trabajo son menores que los necesarios, no se puede reiniciar el contenedor.
Concepto de comprobación 6: Si los puertos de contenedores en el mismo pod entran en conflicto entre sí
- Inicie sesión en el nodo donde se encuentra la carga de trabajo anormal.
- Compruebe el ID del contenedor donde el pod de carga de trabajo sale de forma anormal.
docker ps -a | grep $podName
- Vea los logs del contenedor correspondiente.
docker logs $containerID
Rectifique la falla de la carga de trabajo basado en logs. Como se muestra en la siguiente figura, los puertos de contenedor en el mismo pod entran en conflicto. Como resultado, el contenedor no se inicia.
Figura 2 Falla de reinicio del contenedor debido a un conflicto de puerto de contenedor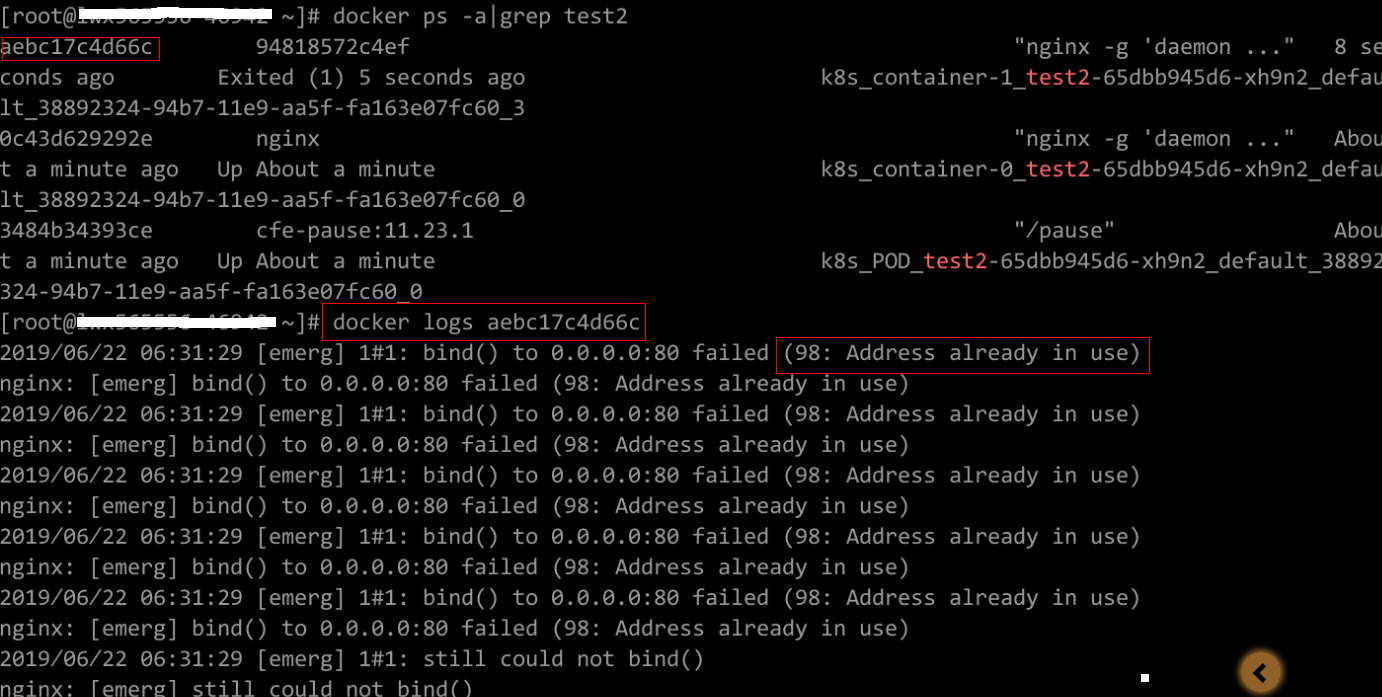
Solución
Vuelva a crear la carga de trabajo y establezca un número de puerto que no utilice ningún otro pod.
Concepto de comprobación 7: Si el comando de inicio del contenedor está correctamente configurado
Los mensajes de error son los siguientes:
Solución
Inicie sesión en la consola de CCE. En la página de detalles de la carga de trabajo, elija Upgrade > Advanced Settings > Lifecycle para comprobar si el comando de inicio está configurado correctamente.
Concepto de comprobación 8: Si la versión de la sonda de Java es la última
Se produce el evento de Kubernetes "Created container init-pinpoint".
Solución
- Al crear una carga de trabajo, seleccione la última versión de sondeo de Java específica (por ejemplo, 1.0.36 y no la opción latest) en la ficha APM Settings del área Advanced Settings.
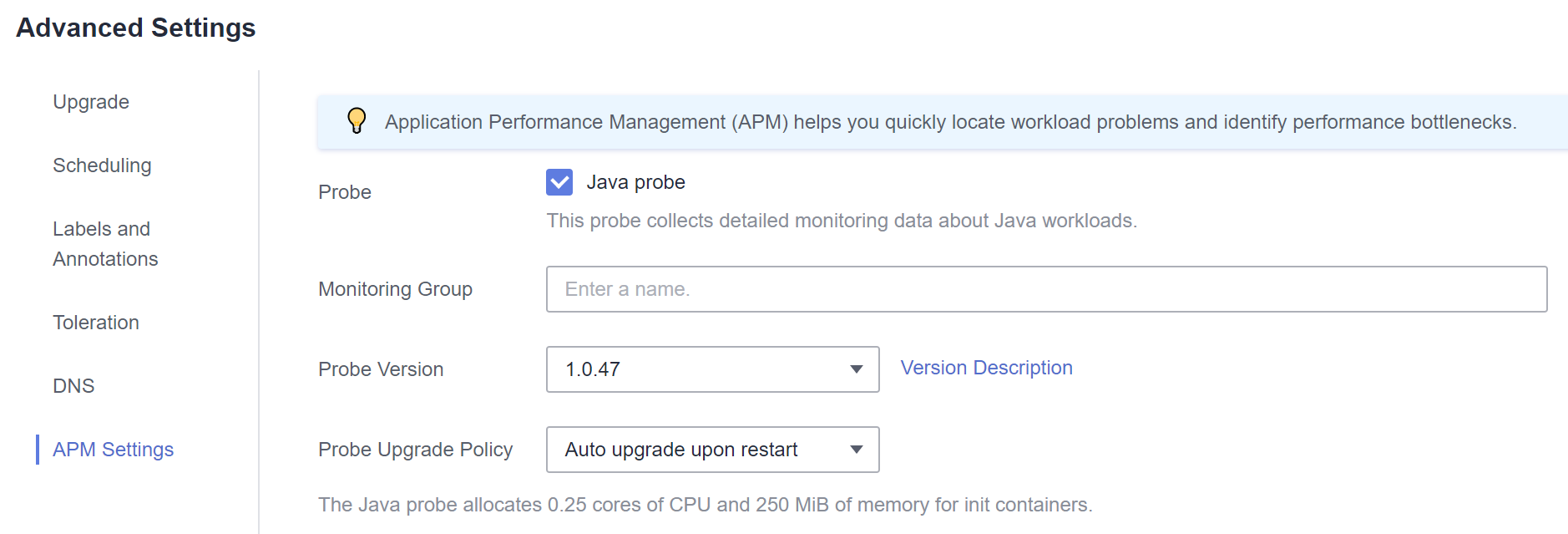
- Si seleccionó latest para el sondeo de Java durante la creación de la carga de trabajo, puede actualizar la carga de trabajo y cambiarla a la versión más reciente específica (por ejemplo, 1.0.36).
Concepto de comprobación 9: Si el servicio de usuario tiene un error
Compruebe si el comando de inicio de la carga de trabajo se ejecuta correctamente o si la carga de trabajo tiene un error.
- Inicie sesión en el nodo donde se encuentra la carga de trabajo anormal.
- Compruebe el ID del contenedor donde el pod de carga de trabajo sale de forma anormal.
docker ps -a | grep $podName
- Vea los logs del contenedor correspondiente.
docker logs $containerID
Nota: En el comando anterior, containerID indica el ID del contenedor que ha salido.
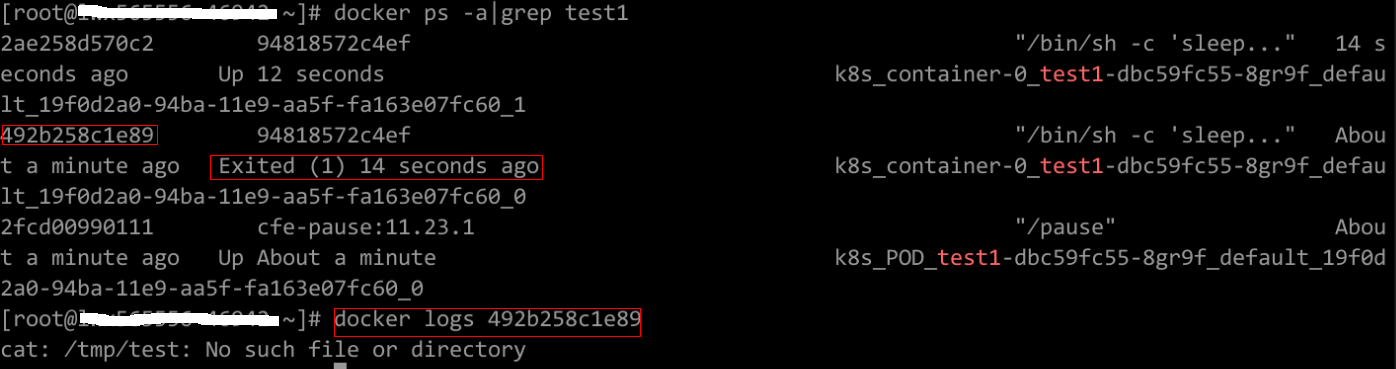
Figura 3 Comando de inicio incorrecto del contenedor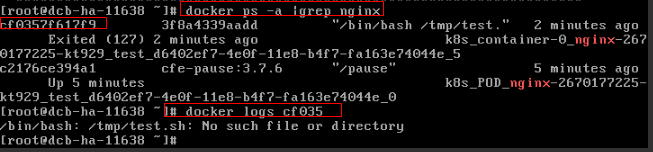
Como se muestra en la figura anterior, el contenedor no puede iniciarse debido a un comando de inicio incorrecto. Para otros errores, rectifique los errores basados en los registros.
Solución
Cree una nueva carga de trabajo y configure un comando de inicio correcto.




