
Política de CPU mejorada
Kubernetes proporciona dos políticas de CPU: ninguna y estática.
- none: La política de CPU está deshabilitada de forma predeterminada, lo que indica el comportamiento de programación existente.
- static: La política de enlace estática del núcleo de la CPU está habilitada. Esta política permite que los pods con ciertas características de recursos reciban una afinidad y exclusividad mejoradas de la CPU en el nodo.
Basado en la política estática de Kubernetes, la política de CPU mejorada (estática mejorada) admite pods explosibles (cuyas solicitudes y límites de CPU son enteros positivos) y les permite usar preferentemente ciertas CPUs, asegurando la estabilidad de la aplicación. Por ejemplo:
...
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "300Mi"
cpu: "2"
requests:
memory: "200Mi"
cpu: "1" Esta característica se basa en la programación optimizada de la CPU en el núcleo de Huawei Cloud EulerOS 2.0. Cuando el uso de CPU utilizado preferentemente por un contenedor supera el 85%, el contenedor se asigna automáticamente a otras CPU con bajo uso para garantizar la capacidad de respuesta de las aplicaciones.

- Cuando se habilita la política de CPU mejorada, el rendimiento de la aplicación es mejor que el de la política none), pero peor que el de la política static.
- La CPU no sería utilizada exclusivamente por los pods explosibles, todavía está en el grupo de CPU compartido. Cuando los pods explosibles están en la marea baja, otros pods pueden compartir esta CPU.
Notas y restricciones
Para utilizar esta función, se deben cumplir las siguientes condiciones:
- La versión del clúster es v1.23 o posterior.
- El sistema operativo del nodo es Huawei Cloud EulerOS 2.0.
Procedimiento
- Inicie sesión en la consola de CCE.
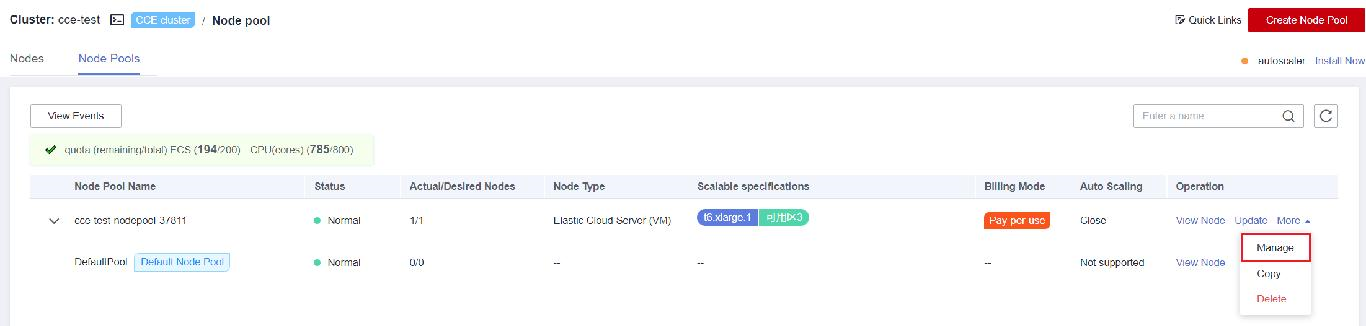
- Haga clic en el nombre del clúster y acceda a la consola del clúster. Elija Nodes en el panel de navegación y haga clic en la ficha Node Pools de la derecha.
- Seleccione un grupo de nodos cuyo sistema operativo sea Huawei Cloud EulerOS 2.0 y elija More > Manage en la columna Operation.
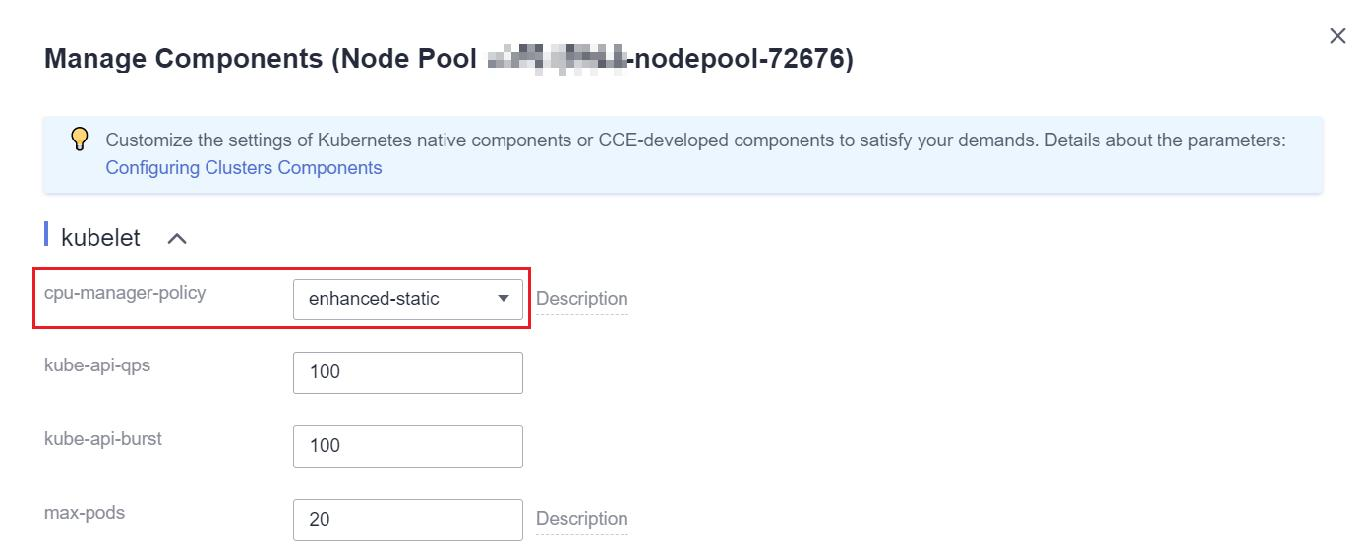
- En la ventana Manage Component que se muestra, cambie el valor de cpu-manager-policy del componente kubelet a enhanced-staic.
- Haga clic en OK.
Verificación
Tome un nodo con 8 vCPUs y 32 GB de memoria como ejemplo. Despliegue una carga de trabajo cuya solicitud de CPU es 1 y el límite es 2 en el clúster por adelantado.
- Inicie sesión en un nodo en el grupo de nodos y vea la salida /var/lib/kubelet/cpu_manager_state.
cat /var/lib/kubelet/cpu_manager_state
Salida del comando:
{"policyName":"enhanced-static","defaultCpuSet":"0,2-7","entries":{"6739f6f2-ebe5-48ae-945a-986d5d8919b9":{"container-1":"0-7,10001"}},"checksum":1638128523}- Si el valor de policyName es de enhanced-static, la política se configura correctamente.
- 10000 se utiliza como base para el ID de CPU. En este ejemplo, 10001 indica que el ID de CPU de afinidad usado por el contenedor es la CPU 1, y 0-7 indica el conjunto de CPU que puede ser usado por el contenedor en el pod.
- Compruebe la configuración de cgroup de cpuset.preferred_cpus del contenedor. La salida es el ID de la CPU que se utiliza preferentemente.
cat /sys/fs/cgroup/cpuset/kubepods/burstable/pod {pod uid} / {Container ID} /cpuset.preferred_cpus
- {pod uid} indica el UID de pod, que se puede obtener ejecutando el siguiente comando en el host que se ha conectado al clúster mediante kubectl:
kubectl get po {pod name} -n {namespace} -ojsonpath='{.metadata.uid}{"\n"}'
En el comando anterior, {pod name} y {namespace} indican el nombre del pod y el espacio de nombres al que pertenece el pod.
- {Container id} debe ser un ID de contenedor completo. Puede ejecutar el siguiente comando en el nodo donde se está ejecutando contenedor para obtener el ID de contenedor: Grupo de nodos de Docker:
docker ps --no-trunc | grep {pod name} | grep -v cce-pause | awk '{print $1}'Grupo de nodos en containerd:
crictl ps --no-trunc | grep {pod name} | grep -v cce-pause | awk '{print $1}'
Un ejemplo completo es el siguiente:
cat /sys/fs/cgroup/cpuset/kubepods/burstable/pod6739f6f2-ebe5-48ae-945a-986d5d8919b9/5ba5603434b95fd22d36fba6a5f1c44eba83c18c2e1de9b52ac9b52e93547a13/cpuset.preferred_cpus
Si se presenta la siguiente salida de commando, se utiliza preferentemente la CPU 1.
1
- {pod uid} indica el UID de pod, que se puede obtener ejecutando el siguiente comando en el host que se ha conectado al clúster mediante kubectl:




