
Estos contenidos se han traducido de forma automática para su comodidad, pero Huawei Cloud no garantiza la exactitud de estos. Para consultar los contenidos originales, acceda a la versión en inglés.
Centro de ayuda/ Cloud Container Engine/ Preguntas frecuentes/ Nodo/ Núcleo de nodos/ ¿Por qué los pods son desalojados por kubelet debido a estadísticas anormales de cgroup?
Actualización más reciente 2023-08-08 GMT+08:00
¿Por qué los pods son desalojados por kubelet debido a estadísticas anormales de cgroup?
Síntoma
En un nodo de brazo, los pod son desalojados por kubelet debido a las estadísticas anormales de cgroup. Como resultado, el nodo funciona anormalmente.
kubelet sigue desalojando los pod. Después de que todos los contenedores están muertos, kubelet todavía considera que la memoria es insuficiente.
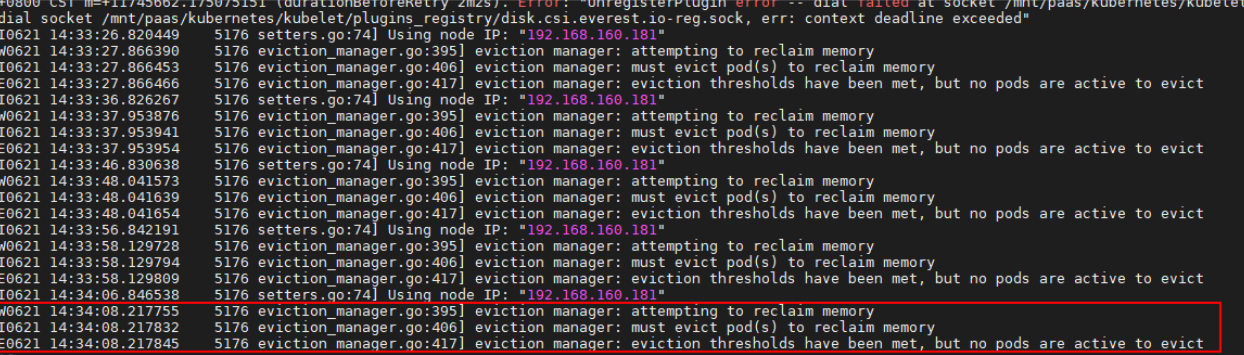
De hecho, el uso de recursos es normal.

El valor de usage_in_bytes de cgroup en el directorio /sys/fs/cgroup/memory es anormal.
# cd /sys/fs/cgroup/memory # cat memory.usage_in_bytes 17618837504
Causa posible
En un nodo Arm, el núcleo de EulerOS 2.8 y 2.9 tiene un error, que hace que kubelet desaloje los pods y resulta en la falta de disponibilidad del servicio.

Este problema se ha resuelto en las siguientes versiones:
- EulerOS 2.8: kernel-4.19.36-vhulk1907.1.0.h1088.eulerosv2r8.aarch64
- EulerOS 2.9: kernel-4.19.90-vhulk2103.1.0.h539.eulerosv2r9.aarch64
Solución
- Si la versión de clúster es 1.19.16-r0, 1.21.7-r0, 1.23.5-r0, 1.25.1-r0 o posterior, restablezca el sistema operativo del nodo a la versión más reciente.
- Si la versión de clúster no cumple con los requisitos, actualice el clúster a la versión especificada y, a continuación, restablezca el sistema operativo del nodo a la versión más reciente.
Tema principal: Núcleo de nodos
Comentarios
¿Le pareció útil esta página?
Deje algún comentario Muchas gracias por sus comentarios. Seguiremos trabajando para mejorar la documentación.
El sistema está ocupado. Vuelva a intentarlo más tarde.




