
Creación de una política de CustomedHPA para el ajuste automático de cargas de trabajo
Una política de CustomedHPA escala las Deployments en función de métricas (como el uso de CPU y el uso de memoria) o en un intervalo periódico (un punto de tiempo específico cada día, cada semana, cada mes o cada año). Este tipo de política es una capacidad de ajuste automático mejorada por CCE.
- El ajuste se puede realizar basándose en el porcentaje del número actual de pods.
- Se puede establecer la etapa del ajuste mínimo.
- Se pueden realizar diferentes operaciones de ajuste según los valores métricos reales.
Requisitos previos
Para usar una política de CustomedHPA, debe instalar el complemento cce-hpa-controller. Si la versión cce-hpa-controller es anterior a 1.2.11, el complemento prometheus debe estar instalado. Si la versión de cce-hpa-controller es 1.2.11 o posterior, los complementos que pueden proporcionar API de métricas deben estar instalados. Seleccione uno de los siguientes complementos según la versión del clúster y los requisitos reales.
- metrics-server: proporciona las métricas básicas de uso de recursos, como CPU de contenedor y uso de memoria. Es compatible con todas las versiones de clúster.
- prometheus: proporciona las métricas personalizadas además de las métricas básicas de recursos. Es necesario registrar Prometheus como el servicio que proporciona API de métricas. Para obtener más información, véase Proporcionar métricas de recursos. Este complemento solo admite clústeres de v1.21 o anteriores.
- kube-prometheus-stack: proporciona las métricas personalizadas además de las métricas básicas de recursos. Es necesario registrar Prometheus como el servicio que proporciona API de métricas. Para obtener más información, véase Proporcionar métricas de recursos. Este complemento solo admite clústeres de v1.23 o posterior.
Notas y restricciones
- Las políticas de CustomedHPA solo se pueden crear para clústeres de v1.15 o posterior.
- Para los clústeres anteriores a v1.19.10, si se utiliza una política de HPA para escalar una carga de trabajo con volúmenes de EVS montados, los pods existentes no se pueden leer ni escribir cuando se programa un nuevo pod en otro nodo.
Para los clústeres de v1.19.10 y de las versiones posteriores, si se utiliza una política de HPA para escalar una carga de trabajo con un volumen de EVS montado, no se puede iniciar un nuevo pod porque no se pueden conectar los discos de EVS.
- Las especificaciones de cce-hpa-controller se deciden por el número total de contenedores en el clúster y el número de políticas de ajuste. Se recomienda configurar 500m CPU y 1,000 MiB de memoria por cada 5,000 contenedores y 100m CPU y 500 MiB de memoria por cada 1,000 políticas de ajuste.
Procedimiento
- Inicie sesión en la consola de CCE y acceda a la consola del clúster.
- Elija Workload Scaling en el panel de navegación y haga clic en la ficha CustomedHPA Policy.
- Si aparece Uninstalled junto al nombre del complemento, haga clic en Install y configure los parámetros del complemento según sea necesario y haga clic en Install para instalar el complemento.
- Si aparece Installed junto al nombre del complemento, este complemento se ha instalado.
- Después de instalar el complemento, haga clic en Create CustomedHPA Policy en la esquina superior derecha.
- Establezca los parámetros de política.
Tabla 1 Parámetros de política de CustomedHPA Parámetro
Descripción
Policy Name
Nombre de la política que se va a crear. Configure este parámetro según sea necesario.
Namespace
Espacio de nombres al que pertenece la carga de trabajo.
Associated Workload
Carga de trabajo con la que está asociada la política de CustomedHPA.
Pod Range
Número mínimo y máximo de pods.
Cuando se activa una política, los pods de carga de trabajo se escalan dentro de este intervalo.
Cooldown Period
Introduzca un intervalo, en minutos.
Este parámetro indica el intervalo entre las operaciones de ajuste consecutivas. El período de tiempo de reutilización garantiza que se inicie una operación de ajuste solo cuando se haya completado la anterior y el sistema se esté ejecutando de manera estable.
Rules
Haga clic en
 . En el cuadro de diálogo que se muestra, establezca los siguientes parámetros:
. En el cuadro de diálogo que se muestra, establezca los siguientes parámetros:- Name: Introduzca un nombre de regla personalizado.
- Type: Puede seleccionar Metric-based o Periodic.
Metric-based:
- Trigger: Seleccione CPU usage o Memory usage, elija > o < e introduzca un porcentaje. Como se muestra en la siguiente figura, la regla se ejecutará inmediatamente cuando el uso de CPU sea superior al 50%. NOTA:
Uso = CPU o memorias utilizadas por pods/CPU o memorias solicitadas.
- Action: Establezca una acción que se realizará cuando se cumpla la condición de activador. Se pueden agregar varias acciones. Como se muestra a continuación, cuando el uso de CPU supera el 50%, el número de pods se escala a 5. Cuando el uso de CPU supera el 70%, el número de pods se escala a 8. Cuando el uso de CPU supera el 90%, el número de pods se reduce a 18 (agregado 10 pods más). Estas reglas también funcionan para las operaciones de reducción.
- Enable: Habilitar o deshabilitar la regla de política.
Figura 1 Establecer una condición de activador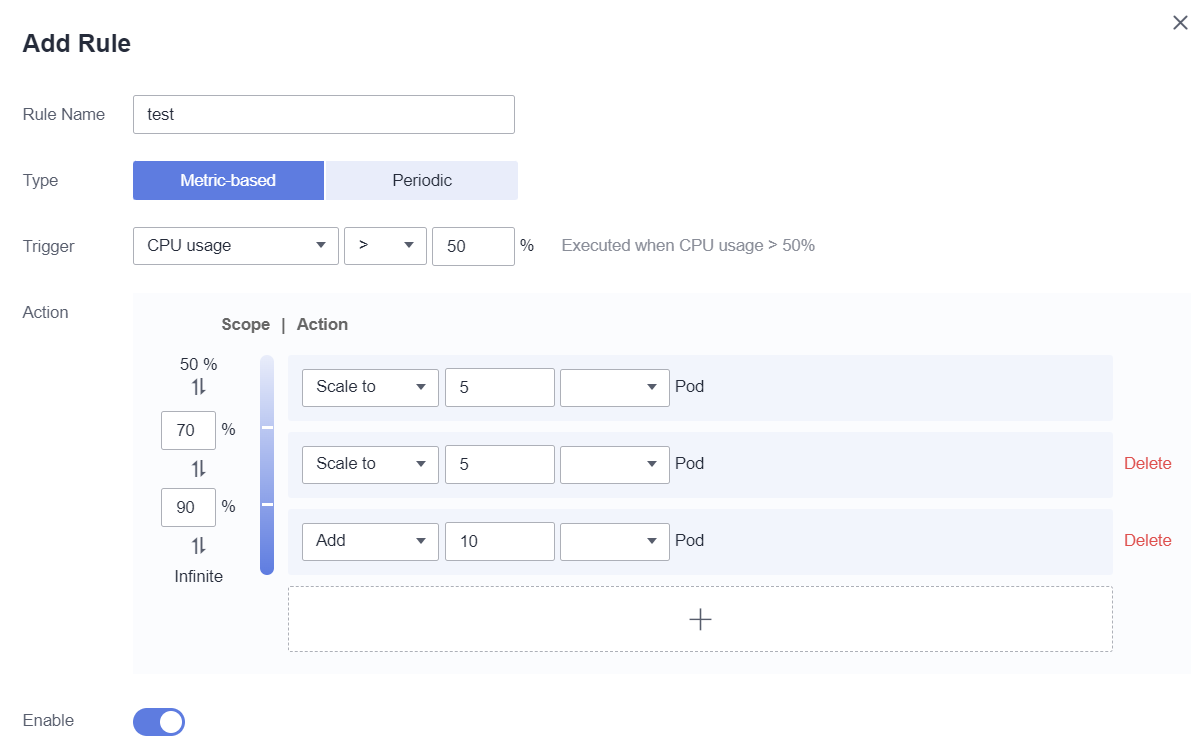
Periodic:
- Trigger Time: Puede seleccionar un punto de tiempo específico cada día, cada semana, cada mes o cada año.
- Action: Establezca una acción que se realizará cuando se alcance el valor Triggered Time. Como se muestra a continuación, se agregará un pod a las 17:00 todos los días.
- Enable: Habilitar o deshabilitar la regla de política.
Figura 2 Activación periódica (Diario)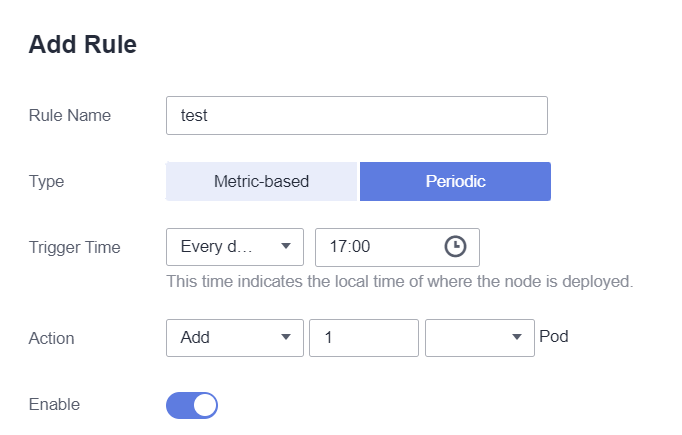
Haga clic en OK y, a continuación, puede ver la regla agregada en la lista de políticas.
- Haga clic en Create.
Uso de kubectl
Una política CustomHPA es un CustomResourceDefinition (CRD) y se puede definir de la siguiente manera en YAML:
apiVersion: autoscaling.cce.io/v1alpha1
kind: CustomedHorizontalPodAutoscaler
metadata:
name: customhpa-example
namespace: default
spec:
coolDownTime: 3m #Cooldown period
maxReplicas: 10 # Maximum number of pods
minReplicas: 1 # Minimum number of pods
rules:
- actions: #Policy rules
- metricRange: 0,0.1 # Metric range, from 0 to 10%
operationType: ScaleDown # Scaling type. ScaleDown indicates downsizing.
operationUnit: Task #Operation unit. Task indicates the number of tasks.
operationValue: 1 # Resource quantity in each scaling
- metricRange: 0.1,0.3 # Metric range, from 10% to 30%
operationType: ScaleDown
operationUnit: Task
operationValue: 2
disable: false
metricTrigger:
hitThreshold: 1
metricName: CPURatioToRequest # Metric name. CPURatioToRequest indicates the CPU usage.
metricOperation: < # Metric expression operator
metricValue: 0.3 # Value on the right of the metric expression
periodSeconds: 60 #
statistic: instantaneous #
ruleName: low
ruleType: Metric
- actions:
- metricRange: 0.7,0.9
operationType: ScaleUp
operationUnit: Task
operationValue: 1
- metricRange: 0.9,+Infinity
operationType: ScaleUp
operationUnit: Task
operationValue: 2
disable: false
metricTrigger:
hitThreshold: 1
metricName: CPURatioToRequest
metricOperation: '>'
metricValue: 0.7
periodSeconds: 60
statistic: instantaneous
ruleName: high
ruleType: Metric
scaleTargetRef: # Associated workload
apiVersion: apps/v1
kind: Deployment
name: nginx 



