

- 最新动态
- 功能总览
- 服务公告
- 产品介绍
- 计费说明
- 快速入门
-
ModelArts用户指南(Standard)
- ModelArts Standard使用流程
- ModelArts Standard准备工作
- ModelArts Standard资源管理
- 使用自动学习实现零代码AI开发
- 使用Workflow实现低代码AI开发
- 使用Notebook进行AI开发调试
- 数据准备与处理
- 使用ModelArts Standard训练模型
- 使用ModelArts Standard部署模型并推理预测
- 制作自定义镜像用于ModelArts Standard
- ModelArts Standard资源监控
- 使用CTS审计ModelArts服务
- ModelArts用户指南(Studio)
- ModelArts用户指南(Lite Server)
- ModelArts用户指南(Lite Cluster)
- ModelArts用户指南(AI Gallery)
-
最佳实践
- ModelArts最佳实践案例列表
- 昇腾能力应用地图
- DeepSeek系列模型推理应用
-
LLM大语言模型训练推理
- 在ModelArts Studio基于Qwen2-7B模型实现新闻自动分类
- 主流开源大模型基于Lite Server适配Ascend-vLLM PyTorch NPU推理指导(6.5.901)
- 主流开源大模型基于Lite Server适配ModelLink PyTorch NPU训练指导(6.5.901)
- 主流开源大模型基于Lite Cluster适配ModelLink PyTorch NPU训练指导(6.5.901)
- 主流开源大模型基于Standard+OBS适配ModelLink PyTorch NPU训练指导(6.5.901)
- 主流开源大模型基于Standard+OBS+SFS适配ModelLink PyTorch NPU训练指导(6.5.901)
- 主流开源大模型基于Lite Server适配LlamaFactory PyTorch NPU训练指导(6.5.901)
- 主流开源大模型基于Lite Server适配Ascend-vLLM PyTorch NPU推理指导(6.3.912)
- 主流开源大模型基于Lite Server适配ModelLink PyTorch NPU训练指导(6.3.912)
- 主流开源大模型基于Lite Cluster适配ModelLink PyTorch NPU训练指导(6.3.912)
- 主流开源大模型基于Standard+OBS适配ModelLink PyTorch NPU训练指导(6.3.912)
- 主流开源大模型基于Standard+OBS+SFS适配ModelLink PyTorch NPU训练指导(6.3.912)
- 主流开源大模型基于Lite Server适配LlamaFactory PyTorch NPU训练指导(6.3.912)
- 主流开源大模型基于Lite Server适配PyTorch NPU推理指导(6.3.911)
- 主流开源大模型基于Standard适配PyTorch NPU推理指导(6.3.911)
- 主流开源大模型基于Lite Cluster适配PyTorch NPU推理指导(6.3.911)
- 主流开源大模型基于Lite Server适配ModelLink PyTorch NPU训练指导(6.3.911)
- 主流开源大模型基于Lite Server适配LlamaFactory PyTorch NPU训练指导(6.3.911)
- 主流开源大模型基于Standard+OBS适配ModelLink PyTorch NPU训练指导(6.3.911)
- 主流开源大模型基于Standard+OBS+SFS适配ModelLink PyTorch NPU训练指导(6.3.911)
- 主流开源大模型基于Lite Cluster适配ModelLink PyTorch NPU训练指导(6.3.911)
- 主流开源大模型基于Lite Server适配PyTorch NPU推理指导(6.3.910)
- 主流开源大模型基于Standard适配PyTorch NPU推理指导(6.3.910)
- 主流开源大模型基于Lite Cluster适配PyTorch NPU推理指导(6.3.910)
- 主流开源大模型基于Lite Server适配ModelLink PyTorch NPU训练指导(6.3.910)
- 主流开源大模型基于Lite Server适配LlamaFactory PyTorch NPU训练指导(6.3.910)
- 主流开源大模型基于Standard+OBS适配ModelLink PyTorch NPU训练指导(6.3.910)
- 主流开源大模型基于Standard+OBS+SFS适配ModelLink PyTorch NPU训练指导(6.3.910)
- 主流开源大模型基于Lite Cluster适配ModelLink PyTorch NPU训练指导(6.3.910)
- 主流开源大模型基于Lite Server适配PyTorch NPU推理指导(6.3.909)
- 主流开源大模型基于Standard适配PyTorch NPU推理指导(6.3.909)
- 主流开源大模型基于Lite Cluster适配PyTorch NPU推理指导(6.3.909)
- 主流开源大模型基于Lite Server适配ModelLink PyTorch NPU训练指导(6.3.909)
- 主流开源大模型基于Lite Server适配LlamaFactory PyTorch NPU训练指导(6.3.909)
- 主流开源大模型基于Standard+OBS适配ModelLink PyTorch NPU训练指导(6.3.909)
- 主流开源大模型基于Standard+OBS+SFS适配ModelLink PyTorch NPU训练指导(6.3.909)
- 主流开源大模型基于Lite Cluster适配ModelLink PyTorch NPU训练指导(6.3.909)
- 主流开源大模型基于Lite Server适配PyTorch NPU推理指导(6.3.908)
- 主流开源大模型基于Standard适配PyTorch NPU推理指导(6.3.908)
- 主流开源大模型基于Lite Server适配ModelLink PyTorch NPU训练指导(6.3.908)
- 主流开源大模型基于Lite Server适配LlamaFactory PyTorch NPU训练指导(6.3.908)
- 主流开源大模型基于Standard+OBS适配ModelLink PyTorch NPU训练指导(6.3.908)
- 主流开源大模型基于Standard+OBS+SFS适配ModelLink PyTorch NPU训练指导(6.3.908)
- 主流开源大模型基于Lite Server适配ModelLink PyTorch NPU训练指导(6.3.907)
- 主流开源大模型基于Lite Server适配LlamaFactory PyTorch NPU训练指导(6.3.907)
- 主流开源大模型基于Lite Server适配PyTorch NPU推理指导(6.3.907)
- 主流开源大模型基于Standard+OBS适配PyTorch NPU训练指导(6.3.907)
- 主流开源大模型基于Standard+OBS+SFS适配PyTorch NPU训练指导(6.3.907)
- 主流开源大模型基于Standard适配PyTorch NPU推理指导(6.3.907)
- 主流开源大模型基于Lite Server适配PyTorch NPU训练指导(6.3.906)
- 主流开源大模型基于Lite Server适配PyTorch NPU推理指导(6.3.906)
- 主流开源大模型基于Standard适配PyTorch NPU训练指导(6.3.906)
- 主流开源大模型基于Standard适配PyTorch NPU推理指导(6.3.906)
- 主流开源大模型基于Lite Server适配PyTorch NPU训练指导(6.3.905)
- 主流开源大模型基于LIte Server适配PyTorch NPU推理指导(6.3.905)
- 主流开源大模型基于Standard适配PyTorch NPU训练指导(6.3.905)
- 主流开源大模型基于Standard适配PyTorch NPU推理指导(6.3.905)
-
MLLM多模态模型训练推理
- Bunny-Llama-3-8B-V基于Lite Server适配PyTorch NPU的训练指导(6.5.901)
- Qwen-VL基于Standard+OBS+SFS适配PyTorch NPU训练指导(6.3.912)
- Qwen-VL模型基于Standard+OBS适配PyTorch NPU训练指导(6.3.912)
- Qwen-VL基于Lite Server适配PyTorch NPU的Finetune训练指导(6.3.912)
- Qwen-VL基于Lite Server适配PyTorch NPU的推理指导(6.3.909)
- MiniCPM-V2.6基于Lite Server适配PyTorch NPU训练指导(6.3.912)
- MiniCPM-V2.0推理及LoRA微调基于Lite Server适配PyTorch NPU指导(6.3.910)
- InternVL2&2.5系列模型基于Lite Server适配PyTorch NPU训练指导(6.5.901)
- InternVL2基于LIte Server适配PyTorch NPU训练指导(6.3.912)
- LLaVA-NeXT基于Lite Server适配PyTorch NPU训练微调指导(6.3.912)
- LLaVA模型基于Lite Server适配PyTorch NPU预训练指导(6.3.912)
- LLaVA模型基于Lite Server适配PyTorch NPU推理指导(6.3.906)
- Llama 3.2-Vision基于Lite Server适配Pytorch NPU训练微调指导(6.3.912)
- LLaMA-VID基于Lite Server适配PyTorch NPU推理指导(6.3.910)
- moondream2基于Lite Server适配PyTorch NPU推理指导
-
文生图模型训练推理
- FlUX.1基于Lite Server适配PyTorch NPU推理指导(6.3.912)
- FLUX.1基于DevSever适配PyTorch NPU Finetune&Lora训练指导(6.3.911)
- Hunyuan-DiT基于Lite Server部署适配PyTorch NPU推理指导(6.3.909)
- SD 3.5基于Lite Server适配PyTorch NPU的训练指导(6.5.901)
- SD3.5基于Lite Server适配PyTorch NPU的推理指导(6.3.912)
- SD3基于Lite Server适配PyTorch NPU的训练指导(6.3.912)
- SD3 Diffusers框架基于Lite Server适配PyTorch NPU推理指导(6.3.912)
- SD1.5&SDXL Diffusers框架基于Lite Server适配PyTorch NPU训练指导(6.3.908)
- SD1.5&SDXL Kohya框架基于DevServer适配PyTorch NPU训练指导(6.3.908)
- SDXL基于Standard适配PyTorch NPU的LoRA训练指导(6.3.908)
- SD3 Diffusers框架基于Lite Server适配PyTorch NPU推理指导(6.3.907)
- SDXL&SD1.5 ComfyUI基于Lite Cluster适配NPU推理指导(6.3.906)
- SDXL基于Standard适配PyTorch NPU的Finetune训练指导(6.3.905)
- SDXL基于Lite Server适配PyTorch NPU的Finetune训练指导(6.3.905)
- SDXL基于Lite Server适配PyTorch NPU的LoRA训练指导(6.3.905)
- SD1.5基于Lite Server适配PyTorch NPU Finetune训练指导(6.3.904)
- Open-Clip基于Lite Server适配PyTorch NPU训练指导
- AIGC工具tailor使用指导
-
文生视频模型训练推理
- CogVideoX1.5 5b 和 CogVideoX 5b模型基于Lite Server全量8卡序列并行推理指导(6.5.901)
- CogVideoX1.5 5b模型基于Lite Server适配PyTorch NPU全量训练指导(6.5.901)
- CogVideoX1.5 5b模型基于Lite Server适配PyTorch NPU全量训练指导(6.3.912)
- CogVideoX模型基于Lite Server适配PyTorch NPU全量训练指导(6.3.911)
- Open-Sora1.2基于Lite Server适配PyTorch NPU训练推理指导(6.3.910)
- Open-Sora-Plan1.0基于Lite Server适配PyTorch NPU训练推理指导(6.3.907)
- Open-Sora 1.0基于Lite Server适配PyTorch NPU训练指导(6.3.905)
- 数字人模型训练推理
- 内容审核模型训练推理
- GPU业务迁移至昇腾训练推理
- Standard权限管理
- Standard自动学习
- Standard开发环境
- Standard模型训练
- Standard推理部署
- 历史待下线案例
-
API参考
- 使用前必读
- API概览
- 如何调用API
-
Workflow工作流管理
- 获取Workflow工作流列表
- 新建Workflow工作流
- 删除Workflow工作流
- 查询Workflow工作流
- 修改Workflow工作流
- 总览Workflow工作流
- 查询Workflow待办事项
- 在线服务鉴权
- 创建在线服务包
- 获取Execution列表
- 新建Workflow Execution
- 删除Workflow Execution
- 查询Workflow Execution
- 更新Workflow Execution
- 管理Workflow Execution
- 管理Workflow StepExecution
- 获取Workflow工作流节点度量信息
- 新建消息订阅Subscription
- 删除消息订阅Subscription
- 查询消息订阅Subscription详情
- 更新消息订阅Subscription
- 创建工作流定时调度
- 查询工作流定时调度详情
- 删除工作流定时调度信息
- 更新工作流定时调度信息
-
开发环境管理
- 创建Notebook实例
- 查询Notebook实例列表
- 查询所有Notebook实例列表
- 查询Notebook实例详情
- 更新Notebook实例
- 删除Notebook实例
- 通过运行的实例保存成容器镜像
- 查询Notebook支持的有效规格列表
- 查询Notebook支持的可切换规格列表
- 查询运行中的Notebook可用时长
- Notebook时长续约
- 启动Notebook实例
- 停止Notebook实例
- 获取动态挂载OBS实例信息列表
- 动态挂载OBS
- 获取动态挂载OBS实例详情
- 动态卸载OBS
- 添加资源标签
- 删除资源标签
- 查询Notebook资源类型下的标签
- 查询支持的镜像列表
- 注册自定义镜像
- 查询用户镜像组列表
- 查询镜像详情
- 删除镜像
-
训练管理
- 创建算法
- 查询算法列表
- 查询算法详情
- 更新算法
- 删除算法
- 获取支持的超参搜索算法
- 创建训练实验
- 创建训练作业
- 查询训练作业详情
- 更新训练作业描述
- 删除训练作业
- 终止训练作业
- 查询训练作业指定任务的日志(预览)
- 查询训练作业指定任务的日志(OBS链接)
- 查询训练作业指定任务的运行指标
- 查询训练作业列表
- 查询超参搜索所有trial的结果
- 查询超参搜索某个trial的结果
- 获取超参敏感度分析结果
- 获取某个超参敏感度分析图像的路径
- 提前终止自动化搜索作业的某个trial
- 获取自动化搜索作业yaml模板的信息
- 获取自动化搜索作业yaml模板的内容
- 创建训练作业标签
- 删除训练作业标签
- 查询训练作业标签
- 获取训练作业事件列表
- 创建训练作业镜像保存任务
- 查询训练作业镜像保存任务
- 获取训练作业支持的公共规格
- 获取训练作业支持的AI预置框架
- AI应用管理
- APP认证管理
- 服务管理
- 资源管理
- DevServer管理
- 授权管理
- 工作空间管理
- 配额管理
- 资源标签管理
- 节点池管理
- 应用示例
- 权限策略和授权项
- 公共参数
-
历史API
-
数据管理(旧版)
- 查询数据集列表
- 创建数据集
- 查询数据集详情
- 更新数据集
- 删除数据集
- 查询数据集的统计信息
- 查询数据集监控数据
- 查询数据集的版本列表
- 创建数据集标注版本
- 查询数据集版本详情
- 删除数据集标注版本
- 查询样本列表
- 批量添加样本
- 批量删除样本
- 查询单个样本信息
- 获取样本搜索条件
- 分页查询团队标注任务下的样本列表
- 查询团队标注的样本信息
- 查询数据集标签列表
- 创建数据集标签
- 批量修改标签
- 批量删除标签
- 按标签名称更新单个标签
- 按标签名称删除标签及仅包含此标签的文件
- 批量更新样本标签
- 查询数据集的团队标注任务列表
- 创建团队标注任务
- 查询团队标注任务详情
- 启动团队标注任务
- 更新团队标注任务
- 删除团队标注任务
- 创建团队标注验收任务
- 查询团队标注验收任务报告
- 更新团队标注验收任务状态
- 查询团队标注任务统计信息
- 查询团队标注任务成员的进度信息
- 团队成员查询团队标注任务列表
- 提交验收任务的样本评审意见
- 团队标注审核
- 批量更新团队标注样本的标签
- 查询标注团队列表
- 创建标注团队
- 查询标注团队详情
- 更新标注团队
- 删除标注团队
- 向标注成员发送邮件
- 查询所有团队的标注成员列表
- 查询标注团队的成员列表
- 创建标注团队的成员
- 批量删除标注团队成员
- 查询标注团队成员详情
- 更新标注团队成员
- 删除标注团队成员
- 查询数据集导入任务列表
- 创建导入任务
- 查询数据集导入任务的详情
- 查询数据集导出任务列表
- 创建数据集导出任务
- 查询数据集导出任务的状态
- 同步数据集
- 查询数据集同步任务的状态
- 查询智能标注的样本列表
- 查询单个智能标注样本的信息
- 分页查询智能任务列表
- 启动智能任务
- 获取智能任务的信息
- 停止智能任务
- 查询处理任务列表
- 创建处理任务
- 查询数据处理的算法类别
- 查询处理任务详情
- 更新处理任务
- 删除处理任务
- 查询数据处理任务的版本列表
- 创建数据处理任务版本
- 查询数据处理任务的版本详情
- 删除数据处理任务的版本
- 查询数据处理任务版本的结果展示
- 停止数据处理任务的版本
- 开发环境(旧版)
- 训练管理(旧版)
-
数据管理(旧版)
- SDK参考
- 场景代码示例
-
故障排除
- 通用问题
- 自动学习
-
开发环境
- 环境配置故障
- 实例故障
- 代码运行故障
- JupyterLab插件故障
-
VS Code连接开发环境失败故障处理
- 在ModelArts控制台界面上单击VS Code接入并在新界面单击打开,未弹出VS Code窗口
- 在ModelArts控制台界面上单击VS Code接入并在新界面单击打开,VS Code打开后未进行远程连接
- VS Code连接开发环境失败时的排查方法
- 远程连接出现弹窗报错:Could not establish connection to xxx
- 连接远端开发环境时,一直处于"Setting up SSH Host xxx: Downloading VS Code Server locally"超过10分钟以上,如何解决?
- 连接远端开发环境时,一直处于"Setting up SSH Host xxx: Copying VS Code Server to host with scp"超过10分钟以上,如何解决?
- 连接远端开发环境时,一直处于"ModelArts Remote Connect: Connecting to instance xxx..."超过10分钟以上,如何解决?
- 远程连接处于retry状态如何解决?
- 报错“The VS Code Server failed to start”如何解决?
- 报错“Permissions for 'x:/xxx.pem' are too open”如何解决?
- 报错“Bad owner or permissions on C:\Users\Administrator/.ssh/config”如何解决?
- 报错“Connection permission denied (publickey)”如何解决
- 报错“ssh: connect to host xxx.pem port xxxxx: Connection refused”如何解决?
- 报错"ssh: connect to host ModelArts-xxx port xxx: Connection timed out"如何解决?
- 报错“Load key "C:/Users/xx/test1/xxx.pem": invalid format”如何解决?
- 报错“An SSH installation couldn't be found”或者“Could not establish connection to instance xxx: 'ssh' ...”如何解决?
- 报错“no such identity: C:/Users/xx /test.pem: No such file or directory”如何解决?
- 报错“Host key verification failed.'或者'Port forwarding is disabled.”如何解决?
- 报错“Failed to install the VS Code Server.”或“tar: Error is not recoverable: exiting now.”如何解决?
- VS Code连接远端Notebook时报错“XHR failed”
- VS Code连接后长时间未操作,连接自动断开
- VS Code自动升级后,导致远程连接时间过长
- 使用SSH连接,报错“Connection reset”如何解决?
- 使用MobaXterm工具SSH连接Notebook后,经常断开或卡顿,如何解决?
- VS Code连接开发环境时报错Missing GLIBC,Missing required dependencies
- 使用VSCode-huawei,报错:卸载了‘ms-vscode-remote.remot-sdh’,它被报告存在问题
- 使用VS Code连接实例时,发现VS Code端的实例目录和云上目录不匹配
- VSCode远程连接时卡顿,或Python调试插件无法使用如何处理?
-
自定义镜像故障
- Notebook自定义镜像故障基础排查
- 镜像保存时报错“there are processes in 'D' status, please check process status using 'ps -aux' and kill all the 'D' status processes”或“Buildimge,False,Error response from daemon,Cannot pause container xxx”如何解决?
- 镜像保存时报错“container size %dG is greater than threshold %dG”如何解决?
- 保存镜像时报错“too many layers in your image”如何解决?
- 镜像保存时报错“The container size (xG) is greater than the threshold (25G)”如何解决?
- 镜像保存时报错“BuildImage,True,Commit successfully|PushImage,False,Task is running.”
- 使用自定义镜像创建Notebook后打开没有kernel
- 用户自定义镜像自建的conda环境会查到一些额外的包,影响用户程序,如何解决?
- 用户使用ma-cli制作自定义镜像失败,报错文件不存在(not found)
- 用户使用torch报错Unexpected error from cudaGetDeviceCount
- 其他故障
-
训练作业
- OBS操作相关故障
-
云上迁移适配故障
- 无法导入模块
- 训练作业日志中提示“No module named .*”
- 如何安装第三方包,安装报错的处理方法
- 下载代码目录失败
- 训练作业日志中提示“No such file or directory”
- 训练过程中无法找到so文件
- ModelArts训练作业无法解析参数,日志报错
- 训练输出路径被其他作业使用
- PyTorch1.0引擎提示“RuntimeError: std:exception”
- MindSpore日志提示“ retCode=0x91, [the model stream execute failed]”
- 使用moxing适配OBS路径,pandas读取文件报错
- 日志提示“Please upgrade numpy to >= xxx to use this pandas version”
- 重装的包与镜像装CUDA版本不匹配
- 创建训练作业提示错误码ModelArts.2763
- 训练作业日志中提示 “AttributeError: module '***' has no attribute '***'”
- 系统容器异常退出
- 硬盘限制故障
- 外网访问限制
- 权限问题
- GPU相关问题
-
业务代码问题
- 日志提示“pandas.errors.ParserError: Error tokenizing data. C error: Expected .* fields”
- 日志提示“max_pool2d_with_indices_out_cuda_frame failed with error code 0”
- 训练作业失败,返回错误码139
- 训练作业失败,如何使用开发环境调试训练代码?
- 日志提示“ '(slice(0, 13184, None), slice(None, None, None))' is an invalid key”
- 日志报错“DataFrame.dtypes for data must be int, float or bool”
- 日志提示“CUDNN_STATUS_NOT_SUPPORTED. ”
- 日志提示“Out of bounds nanosecond timestamp”
- 日志提示“Unexpected keyword argument passed to optimizer”
- 日志提示“no socket interface found”
- 日志提示“Runtimeerror: Dataloader worker (pid 46212 ) is killed by signal: Killed BP”
- 日志提示“AttributeError: 'NoneType' object has no attribute 'dtype'”
- 日志提示“No module name 'unidecode'”
- 分布式Tensorflow无法使用“tf.variable”
- MXNet创建kvstore时程序被阻塞,无报错
- 日志出现ECC错误,导致训练作业失败
- 超过最大递归深度导致训练作业失败
- 使用预置算法训练时,训练失败,报“bndbox”错误
- 训练作业状态显示“审核作业初始化”
- 训练作业进程异常退出
- 训练作业进程被kill
- 预置算法运行故障
- 训练作业卡死检测定位
- 训练作业运行失败
- 专属资源池创建训练作业
- 训练作业性能问题
- Ascend相关问题
-
推理部署
-
模型管理
- 创建模型失败,如何定位和处理问题?
- 导入模型提示该账号受限或者没有操作权限
- 用户创建模型时构建镜像或导入文件失败
- 创建模型时,OBS文件目录对应镜像里面的目录结构是什么样的?
- 通过OBS导入模型时,如何编写打印日志代码才能在ModelArts日志查询界面看到日志
- 通过OBS创建模型时,构建日志中提示pip下载包失败
- 通过自定义镜像创建模型失败
- 导入模型后部署服务,提示磁盘不足
- 创建模型成功后,部署服务报错,如何排查代码问题
- 自定义镜像导入配置运行时依赖无效
- 通过API接口查询模型详情,model_name返回值出现乱码
- 导入模型提示模型或镜像大小超过限制
- 导入模型提示单个模型文件超过5G限制
- 订阅的模型一直处于等待同步状态
- 创建模型失败,提示模型镜像构建任务超时,没有构建日志
-
服务部署
- 自定义镜像模型部署为在线服务时出现异常
- 部署的在线服务状态为告警
- 服务启动失败
- 服务部署、启动、升级和修改时,拉取镜像失败如何处理?
- 服务部署、启动、升级和修改时,镜像不断重启如何处理?
- 服务部署、启动、升级和修改时,容器健康检查失败如何处理?
- 服务部署、启动、升级和修改时,资源不足如何处理?
- 模型使用CV2包部署在线服务报错
- 服务状态一直处于“部署中”
- 服务启动后,状态断断续续处于“告警中”
- 服务部署失败,报错No Module named XXX
- IEF节点边缘服务部署失败
- 批量服务输入/输出obs目录不存在或者权限不足
- 部署在线服务出现报错No CUDA runtime is found
- 使用AI市场物体检测YOLOv3_Darknet53算法训练后部署在线服务报错
- 使用预置AI算法部署在线服务报错gunicorn:error:unrecorgized arguments
- 内存不足如何处理?
- 服务预测
-
模型管理
- MoXing
- API/SDK
- 资源池
-
Lite Server
- GPU裸金属服务器使用EulerOS内核误升级如何解决
- GPU A系列裸金属服务器没有任务但GPU被占用如何解决
- GPU A系列裸金属服务器无法获取显卡如何解决
- GPU裸金属服务器无法Ping通如何解决
- GPU A系列裸金属服务器RoCE带宽不足如何解决?
- GPU裸金属服务器更换NVIDIA驱动后执行nvidia-smi提示Failed to initialize NVML
- 训练速度突然下降以及执行nvidia-smi卡顿如何解决?
- GP Vnt1裸金属服务器用PyTorch报错CUDA initialization:CUDA unknown error
- 使用SFS盘出现报错rpc_check_timeout:939 callbacks suppressed
- 华为云CCE集群纳管GPU裸金属服务器由于CloudInit导致纳管失败的解决方案
- GPU A系列裸金属服务器使用CUDA cudaGetDeviceCount()提示CUDA initializat失败
- 裸金属服务器Euler OS升级NetworkManager-config-server导致SSH链接故障解决方案
- Lite Cluster
-
常见问题
- 权限相关
- 存储相关
- Standard自动学习
- Standard Workflow
-
Standard数据准备
- 在ModelArts数据集中添加图片对图片大小有限制吗?
- 如何将本地标注的数据导入ModelArts?
- 在ModelArts中数据标注完成后,标注结果存储在哪里?
- 在ModelArts中如何将标注结果下载至本地?
- 在ModelArts中进行团队标注时,为什么团队成员收不到邮件?
- ModelArts团队标注的数据分配机制是什么?
- 如何将两个ModelArts数据集合并?
- 在ModelArts中同一个账户,图片展示角度不同是为什么?
- 在ModelArts中智能标注完成后新加入数据需要重新训练吗?
- 在ModelArts中如何将图片划分到验证集或者训练集?
- 在ModelArts中物体检测标注时能否自定义标签?
- ModelArts数据集新建的版本找不到怎么办?
- 如何切分ModelArts数据集?
- 如何删除ModelArts数据集中的图片?
-
Standard Notebook
- ModelArts的Notebook是否支持Keras引擎?
- 如何在ModelArts的Notebook中上传下载OBS文件?
- ModelArts的Notebook实例upload后,数据会上传到哪里?
- 在ModelArts中如何将Notebook A的数据复制到Notebook B中?
- 在ModelArts的Notebook中如何对OBS的文件重命名?
- 在ModelArts的Notebook中如何使用pandas库处理OBS桶中的数据?
- 在ModelArts的Notebook中,如何访问其他账号的OBS桶?
- 在ModelArts的Notebook中JupyterLab默认工作路径是什么?
- 如何查看ModelArts的Notebook使用的cuda版本?
- 在ModelArts的Notebook中如何获取本机外网IP?
- ModelArts的Notebook有代理吗?如何关闭?
- 在ModelArts的Notebook中内置引擎不满足使用需要时,如何自定义引擎IPython Kernel?
- 在ModelArts的Notebook中如何将git clone的py文件变为ipynb文件?
- 在ModelArts的Notebook实例重启时,数据集会丢失吗?
- 在ModelArts的Notebook的Jupyterlab可以安装插件吗?
- 在ModelArts的Notebook的CodeLab中能否使用昇腾卡进行训练?
- 如何在ModelArts的Notebook的CodeLab上安装依赖?
- 在ModelArts的Notebook中安装远端插件时不稳定要怎么办?
- 在ModelArts的Notebook中实例重新启动后要怎么连接?
- 在ModelArts的Notebook中使用VS Code调试代码无法进入源码怎么办?
- 在ModelArts的Notebook中使用VS Code如何查看远端日志?
- 在ModelArts的Notebook中如何打开VS Code的配置文件settings.json?
- 在ModelArts的Notebook中如何设置VS Code背景色为豆沙绿?
- 在ModelArts的Notebook中如何设置VS Code远端默认安装的插件?
- 在ModelArts的VS Code中如何把本地插件安装到远端或把远端插件安装到本地?
- 在ModelArts的Notebook中,如何使用昇腾多卡进行调试?
- 在ModelArts的Notebook中使用不同的资源规格训练时为什么训练速度差不多?
- 在ModelArts的Notebook中使用MoXing时,如何进行增量训练?
- 在ModelArts的Notebook中如何查看GPU使用情况?
- 在ModelArts的Notebook中如何在代码中打印GPU使用信息?
- 在ModelArts的Notebook中JupyterLab的目录、Terminal的文件和OBS的文件之间的关系是什么?
- 如何在ModelArts的Notebook实例中使用ModelArts数据集?
- pip介绍及常用命令
- 在ModelArts的Notebook中不同规格资源/cache目录的大小是多少?
- 资源超分对在ModelArts的Notebook实例有什么影响?
- 如何在Notebook中安装外部库?
- 在ModelArts的Notebook中,访问外网速度不稳定怎么办?
- Notebook是否支持使用gdb工具?
-
Standard模型训练
- 在ModelArts训练得到的模型欠拟合怎么办?
- 在ModelArts中训练好后的模型如何获取?
- 在ModelArts上如何获得RANK_TABLE_FILE用于分布式训练?
- 在ModelArts上训练模型如何配置输入输出数据?
- 在ModelArts上如何提升训练效率并减少与OBS的交互?
- 在ModelArts中使用Moxing复制数据时如何定义路径变量?
- 在ModelArts上如何创建引用第三方依赖包的训练作业?
- 在ModelArts训练时如何安装C++的依赖库?
- 在ModelArts训练作业中如何判断文件夹是否复制完毕?
- 如何在ModelArts训练作业中加载部分训练好的参数?
- ModelArts训练时使用os.system('cd xxx')无法进入文件夹怎么办?
- 在ModelArts训练代码中,如何获取依赖文件所在的路径?
- 自如何获取ModelArts训练容器中的文件实际路径?
- ModelArts训练中不同规格资源“/cache”目录的大小是多少?
- ModelArts训练作业为什么存在/work和/ma-user两种超参目录?
- 如何查看ModelArts训练作业资源占用情况?
- 如何将在ModelArts中训练好的模型下载或迁移到其他账号?
-
Standard推理部署
- 如何将Keras的.h5格式的模型导入到ModelArts中?
- ModelArts导入模型时,如何编写模型配置文件中的安装包依赖参数?
- 在ModelArts中使用自定义镜像创建在线服务,如何修改端口?
- ModelArts平台是否支持多模型导入?
- 在ModelArts中导入模型对于镜像大小有什么限制?
- ModelArts在线服务和批量服务有什么区别?
- ModelArts在线服务和边缘服务有什么区别?
- 在ModelArts中部署模型时,为什么无法选择Ascend Snt3资源?
- ModelArts线上训练得到的模型是否支持离线部署在本地?
- ModelArts在线服务预测请求体大小限制是多少?
- ModelArts部署在线服务时,如何避免自定义预测脚本python依赖包出现冲突?
- ModelArts在线服务预测时,如何提高预测速度?
- 在ModelArts中调整模型后,部署新版本模型能否保持原API接口不变?
- ModelArts在线服务的API接口组成规则是什么?
- ModelArts在线服务处于运行中时,如何填写request header和request body?
-
Standard镜像相关
- 不在同一个主账号下,如何使用他人的自定义镜像创建Notebook?
- 如何登录并上传镜像到SWR?
- 在Dockerfile中如何给镜像设置环境变量?
- 如何通过docker镜像启动容器?
- 如何在ModelArts的Notebook中配置Conda源?
- ModelArts的自定义镜像软件版本匹配有哪些注意事项?
- 镜像在SWR上显示只有13G,安装少量的包,然后镜像保存过程会提示超过35G大小保存失败,为什么?
- 如何保证自定义镜像能不因为超过35G而保存失败?
- 如何减小本地或ECS构建镜像的目的镜像的大小?
- 镜像过大,卸载原来的包重新打包镜像,最终镜像会变小吗?
- 在ModelArts镜像管理注册镜像报错ModelArts.6787怎么处理?
- 用户如何设置默认的kernel?
- Standard专属资源池
- MaaS
- Edge
- API/SDK
- Lite Server
- Lite Cluster
- 历史文档待下线
- 视频帮助
- 文档下载
- 通用参考

链接复制成功!
在Notebook调试环境中部署推理服务
在ModelArts的开发环境Notebook中可以部署推理服务进行调试。
Step1 准备Notebook
参考准备Notebook完成Notebook的创建,并打开Notebook。
Step2 准备权重文件
import moxing as mox
obs_dir = "obs://${bucket_name}/${folder-name}"
local_dir = "/home/ma-user/work/qwen-14b"
mox.file.copy_parallel(obs_dir, local_dir)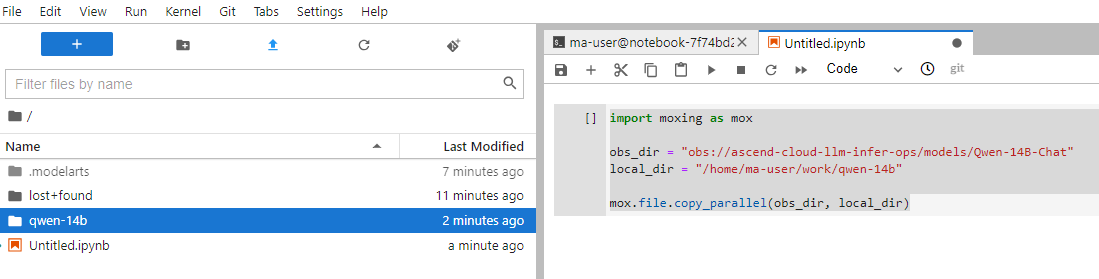
Step3 启动推理服务
- 配置需要使用的NPU卡为容器中的第几张卡。例如:实际使用的是容器中第1张卡,此处填写“0”。
export ASCEND_RT_VISIBLE_DEVICES=0
如果启动服务需要使用多张卡,则按容器中的卡号依次编排。例如:实际使用的是容器中第1张和第2张卡,此处填写为“0,1”,以此类推。
export ASCEND_RT_VISIBLE_DEVICES=0,1
 说明:
通过命令npu-smi info查询NPU卡为容器中的第几张卡。例如下图查询出两张卡,如果希望使用第一和第二张卡,则“export ASCEND_RT_VISIBLE_DEVICES=0,1”,注意编号不是填4、5。图2 查询结果
说明:
通过命令npu-smi info查询NPU卡为容器中的第几张卡。例如下图查询出两张卡,如果希望使用第一和第二张卡,则“export ASCEND_RT_VISIBLE_DEVICES=0,1”,注意编号不是填4、5。图2 查询结果
- 配置环境变量。
export USE_PFA_HIGH_PRECISION_MODE=1 # PFA算子(全量prefill阶段的flash-attention)是否使用高精度模式;默认值为1表示开启。针对Qwen2-7B模型和Qwen2-57b模型,必须开启此配置,否则精度会异常;其他模型不建议开启,会影响首token时延增加5%~10%。 export USE_IFA_HIGH_PRECISION_MODE=1 # IFA算子(增量decode阶段的flash-attention)是否使用高精度模式;默认值为0表示不开启。针对Qwen2-7B、Qwen2-57b、Qwen2-72B,在长序列下需要开启,否则会有概率性精度异常;其他模型不建议开启,会影响增量时延增加5%~10%。 export USE_PREFIX_HIGH_PRECISION_MODE=1 # 针对Qwen2-7B、Qwen2-72B模型,在开启prefix-caching时,需要同时使用带有prefix-caching的高精度attention算子避免精度异常。需要和prefix-caching特性一起使用,如果不使用prefix-caching特性则不配置该环境变量。
- 若要开启图模式,请配置以下5个环境变量,并且启动服务时不要添加enforce-eager参数。
export INFER_MODE=PTA # 开启PTA模式,若不使用图模式,请关闭该环境变量 export PTA_TORCHAIR_DECODE_GEAR_ENABLE=1 # 开启动态分档功能 export PTA_TORCHAIR_DECODE_GEAR_LIST=2,4,6,8,16,32 # 设置动态分档的档位,根据实际情况设置,另外请不要设置档位1(DeepSeek V2 236B W8A8 模型建议最大设置4个档位) export VLLM_ENGINE_ITERATION_TIMEOUT_S=1500 # 设置vllm请求超时时间(DeepSeek V2 236B W8A8 模型建议调大为6000) export HCCL_OP_EXPANSION_MODE=AIV #可选
设置动态分档位后,在PTA模式下不支持接收超过最大档的并发请求,超过后会导致推理服务终止。请将最大档(PTA_TORCHAIR_DECODE_GEAR_LIST参数的中设置的最大值)与模型启动时的max-num-seqs保持一致来进行规避。
在MoE模型和小模型上推荐使用图模式部署,包括mixtral-8x7B、qwen2-57B、deepseek-v2-lite-16B、deepseek-v2-236B-W8A8;和Qwen2-1.5B、Qwen2-0.5B。当前MoE模型图模式启动不支持multi step。
MoE模型依赖MindSpeed,当使用MoE模型推理时,需提前安装:
git clone https://gitee.com/ascend/MindSpeed.git cd MindSpeed git checkout a956b907ef3b0787d2a38577eb5b702f5b7e715d #推荐commit pip install -e .
开启图模式后,服务第一次响应请求时会有一个较长时间的图编译过程,并且会在当前目录下生成.torchair_cache文件夹来保存图编译的缓存文件。当服务第二次启动时,可通过缓存文件来快速完成图编译的过程,避免长时间的等待,并且基于图编译缓存文件来启动服务可获得更优的推理性能,因此请在有图编译缓存文件的前提下启动服务。另外,当启动服务时的模型或者参数发生改变时,请删除.torchair_cache文件夹,避免由于缓存文件与实际推理不匹配而报错。
- 若要使用eagle投机,配置环境变量,使eagle投机对齐实验室版本实现。目前默认开启此模式,若不开启,目前vllm0.6.0版本与实验室版本权重无法对齐,会导致小模型精度问题。
export EAGLE_USE_SAFE_AI_LAB_STYLE=1 # eagle投机对基于 https://github.com/SafeAILab/EAGLE/ 版本实现 export ENABLE_SPEC_METRIC=0 # 是否关闭投机推理的metric采集功能,关闭有助于提升投机推理性能,默认关闭
如果需要使用eagle投机推理功能,需要进入 lm_tools/spec_decode/EAGLE文件夹,使用convert_eagle_ckpt_to_vllm_compatible.py脚本进行权重转换。转换命令为python convert_eagle_ckpt_to_vllm_compatible.py --base-path 大模型权重地址 --draft-path 小模型权重地址 --base-weight-name 大模型包含lm_head的权重文件名 --draft-weight-name 小模型权重文件名
具体可参考 8 eagle 投机小模型训练 步骤五:训练生成权重转换成可以支持vLLM推理的格式
- 如果需要增加模型量化功能,启动推理服务前,先参考推理模型量化章节对模型做量化处理。
- 启动服务与请求。此处提供vLLM服务API接口启动和OpenAI服务API接口启动2种方式。详细启动服务与请求方式参考:https://docs.vllm.ai/en/latest/getting_started/quickstart.html。
说明:
以下服务启动介绍的是在线推理方式,离线推理请参见https://docs.vllm.ai/en/latest/getting_started/quickstart.html#offline-batched-inference。
- 方式一:通过OpenAI服务API接口启动服务
在llm_inference/ascend_vllm/目录下通OpenAI服务API接口启动服务,具体操作命令如下,可以根据参数说明修改配置。
(1)非多模态
python -m vllm.entrypoints.openai.api_server --model ${container_model_path} \ --max-num-seqs=256 \ --max-model-len=4096 \ --max-num-batched-tokens=4096 \ --tensor-parallel-size=1 \ --block-size=128 \ --host=${docker_ip} \ --port=8080 \ --gpu-memory-utilization=0.9 \ --num-scheduler-steps=8 \ --trust-remote-code(2)多模态
当前支持Llava、InternVL、MiniCPM-v2.6模型,具体模型和权重地址参见支持的模型列表和权重文件,推荐显卡数量参见表1。
export VLLM_IMAGE_FETCH_TIMEOUT=100 export VLLM_ENGINE_ITERATION_TIMEOUT_S=600 # PYTORCH_NPU_ALLOC_CONF优先设置为expandable_segments:True # 如果有涉及虚拟显存相关的报错,可设置为expandable_segments:False export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True python -m vllm.entrypoints.openai.api_server --model ${container_model_path} \ --max-num-seqs=256 \ --max-model-len=4096 \ --max-num-batched-tokens=4096 \ --tensor-parallel-size=1 \ --block-size=128 \ --chat-template ${chat_template_path} \ --dtype ${dtype} \ --host=${docker_ip} \ --port=${port} \ --gpu-memory-utilization=0.9 \ --trust-remote-code多模态推理服务启动模板参数说明如下:
- 方式二:通过vLLM服务API接口启动服务
在llm_inference/ascend_vllm/目录下通过vLLM服务API接口启动服务,具体操作命令如下,API Server的命令相关参数说明如下,可以根据参数说明修改配置。
python -m vllm.entrypoints.api_server --model ${container_model_path} \ --max-num-seqs=256 \ --max-model-len=4096 \ --max-num-batched-tokens=4096 \ --tensor-parallel-size=1 \ --block-size=128 \ --host=${docker_ip} \ --port=8080 \ --gpu-memory-utilization=0.9 \ --trust-remote-code
推理服务基础参数说明如下:- -model ${container_model_path}:模型地址,模型格式是HuggingFace的目录格式。即Step2 准备权重文件上传的HuggingFace权重文件存放目录。如果使用了量化功能,则使用推理模型量化章节转换后的权重。
- --max-num-seqs:最大同时处理的请求数,超过后拒绝访问。
- --max-model-len:推理时最大输入+最大输出tokens数量,输入超过该数量会直接返回。max-model-len的值必须小于config.json文件中的"seq_length"的值,否则推理预测会报错。config.json存在模型对应的路径下,例如:${container_work_dir}/chatglm3-6b/config.json。不同模型推理支持的max-model-len长度不同,具体差异请参见附录:基于vLLM不同模型推理支持最小卡数和最大序列说明。
- --max-num-batched-tokens:prefill阶段,最多会使用多少token,必须大于或等于--max-model-len,推荐使用4096或8192。
- --dtype:模型推理的数据类型。支持FP16和BF16数据类型推理。float16表示FP16,bfloat16表示BF16。
如果不指定,则根据输入数据自动匹配数据类型。使用不同的dtype会影响模型精度。如果使用开源权重,建议不指定dtype,使用开源权重默认的dtype。
- --tensor-parallel-size:模型并行数。取值需要和启动的NPU卡数保持一致,可以参考1。此处举例为1,表示使用单卡启动服务。
- --block-size:PagedAttention的block大小,推荐设置为128。
- --num-scheduler-steps: 默认为1,推荐设置为8。用于mult-step调度。每次调度生成多个token,可以降低时延。开启multi-step后,在流式返回中,会一次返回num-scheduler-steps个token。开启投机推理后无需配置该参数。
- --host=${docker_ip}:服务部署的IP,${docker_ip}替换为宿主机实际的IP地址。
- --port:服务部署的端口。
- --gpu-memory-utilization:NPU使用的显存比例,复用原vLLM的入参名称,默认为0.9。
- --trust-remote-code:是否相信远程代码。
- --distributed-executor-backend:多卡推理启动后端,可选值为"ray"或者"mp",其中"ray"表示使用ray进行启动多卡推理,"mp"表示使用python多进程进行启动多卡推理。默认使用"mp"后端启动多卡推理。
高阶参数说明:- --enable-prefix-caching:如果prompt的公共前缀较长或者多轮对话场景下推荐使用prefix-caching特性。在推理服务启动脚本中添加此参数表示使用prefix-caching特性,不添加表示不使用。开启该特性后,如果模型长度>8192,则需要在启动推理服务前添加如下环境变量降低显存占用;否则在长序列的推理中会触发Out of Memory,导致推理服务不可用。
export USE_PREFIX_HIGH_PRECISION_MODE=1
- 如果需要使用multi-lora特性;需要在推理服务启动命令中额外添加如下命令。
--enable-lora \ --lora-modules lora1=/path/to/lora/adapter1/ lora2=/path/to/lora/adapter2/ \ --max-lora-rank=16 \ --max-loras=32 \ --max-cpu-loras=32
--enable-lora表示开启lora挂载。
--lora-modules后面添加挂载的lora列表,要求lora地址权重是huggingface格式,当前支持QKV-proj、O-proj、gate_up_proj、down_proj模块的挂载。
--max-lora-rank表示挂载lora的最大rank数量,支持8、16、32、64。
--max-loras 表示支持的最大lora个数,最大32。
--max-cpu-loras要求配置和--max-loras相同。
发请求时model指定为lora1或者lora2即为LoRA推理。
- --quantization:推理量化参数。当使用量化功能,则在推理服务启动脚本中增加该参数,如果未使用量化功能,则无需配置。根据使用的量化方式配置,可选择awq或smoothquant方式。该参数可与投机推理配合使用,实现投机校验模型的量化功能。
- --speculative-model ${container_draft_model_path}:投机草稿模型地址,模型格式是HuggingFace的目录格式。即Step2 准备权重文件上传的HuggingFace权重文件存放目录。投机草稿模型为与--model入参同系列,但是权重参数远小于--model指定的模型。如果未使用投机推理功能,则无需配置。
- --speculative-draft-tensor-parallel-size: 投机模型使用tp数,因为投机模型较小,多卡并行时通信会降低性能,故此处需要设置为1。
- --num-speculative-tokens:投机推理草稿模型每次推理的token数。如果未使用投机推理功能,则无需配置。参数--num-speculative-tokens需要和--speculative-model ${container_draft_model_path}同时使用。
- --use-v2-block-manager:vllm启动时使用V2版本的BlockSpaceManger来管理KVCache索引,如果不使用该功能,则无需配置。注意:如果使用投机推理功能,必须开启此参数。
- --served-model-name:vllm服务后台id。
服务启动后,会打印如下类似信息。
server launch time cost: 15.443044185638428 s INFO: Started server process [2878] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
- 方式一:通过OpenAI服务API接口启动服务
Step4 请求推理服务
另外启动一个terminal,使用命令测试推理服务是否正常启动,端口请修改为启动服务时指定的端口。
使用命令测试推理服务是否正常启动。服务启动命令中的参数设置请参见表1。
- 方式一:通过OpenAI服务API接口启动服务使用以下推理测试命令。${docker_ip}替换为实际宿主机的IP地址。如果启动服务未添加served-model-name参数,${container_model_path}的值请与model参数的值保持一致,如果使用了served-model-name参数,${container_model_path}请替换为实际使用的模型名称。
curl -X POST http://localhost:8080/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "${container_model_path}", "messages": [ { "role": "user", "content": "hello" } ], "max_tokens": 100, "top_k": -1, "top_p": 1, "temperature": 0, "ignore_eos": false, "stream": false }' - 方式二:通过vLLM服务API接口启动服务使用以下推理测试命令。下面以Llama系列模型采样方式支持presence_penalty参数的发送请求为例。
curl -X POST http://localhost:8080/generate \ -H "Content-Type: application/json" \ -d '{ "prompt": "hello", "max_tokens": 100, "temperature": 0, "ignore_eos": false, "presence_penalty":2 }'下面以Llama系列模型采样方式支持length_penalty参数的发送请求为例。
curl -X POST http://localhost:8080/generate \ -H "Content-Type: application/json" \ -d '{ "prompt": "hello", "max_tokens": 100, "top_p": 1, "temperature": 0, "ignore_eos": false, "top_k": -1, "use_beam_search":true, "best_of":2, "length_penalty":2 }'
|
参数 |
是否必选 |
默认值 |
参数类型 |
描述 |
|---|---|---|---|---|
|
model |
是 |
无 |
Str |
通过OpenAI服务API接口启动服务时,推理请求必须填写此参数。取值必须和启动推理服务时的model ${model_path}参数保持一致。 通过vLLM服务API接口启动服务时,推理请求不涉及此参数。 |
|
prompt |
是 |
- |
Str |
请求输入的问题。 |
|
max_tokens |
否 |
16 |
Int |
每个输出序列要生成的最大tokens数量。 |
|
top_k |
否 |
-1 |
Int |
控制要考虑的前几个tokens的数量的整数。设置为-1表示考虑所有tokens。 适当降低该值可以减少采样时间。 |
|
top_p |
否 |
1.0 |
Float |
控制要考虑的前几个tokens的累积概率的浮点数。必须在 (0, 1] 范围内。设置为1表示考虑所有tokens。 |
|
temperature |
否 |
1.0 |
Float |
控制采样的随机性的浮点数。较低的值使模型更加确定性,较高的值使模型更加随机。0表示贪婪采样。 |
|
stop |
否 |
None |
None/Str/List |
用于停止生成的字符串列表。返回的输出将不包含停止字符串。 例如:["你","好"],生成文本时遇到"你"或者"好"将停止文本生成。 |
|
stream |
否 |
False |
Bool |
是否开启流式推理。默认为False,表示不开启流式推理。 |
|
n |
否 |
1 |
Int |
返回多条正常结果。 约束与限制: 不使用beam_search场景下,n取值建议为1≤n≤10。如果n>1时,必须确保不使用greedy_sample采样。也就是top_k > 1; temperature > 0。 使用beam_search场景下,n取值建议为1<n≤10。如果n=1,会导致推理请求失败。 说明:
n建议取值不超过10,n值过大会导致性能劣化,显存不足时,推理请求会失败。 |
|
use_beam_search |
否 |
False |
Bool |
是否使用beam_search替换采样。 约束与限制:使用该参数时,如下参数需按要求设置: n>1 top_p = 1.0 top_k = -1 temperature = 0.0 |
|
presence_penalty |
否 |
0.0 |
Float |
presence_penalty表示会根据当前生成的文本中新出现的词语进行奖惩。取值范围[-2.0,2.0]。 |
|
frequency_penalty |
否 |
0.0 |
Float |
frequency_penalty会根据当前生成的文本中各个词语的出现频率进行奖惩。取值范围[-2.0,2.0]。 |
|
length_penalty |
否 |
1.0 |
Float |
length_penalty表示在beam search过程中,对于较长的序列,模型会给予较大的惩罚。 如果要使用length_penalty,必须添加如下三个参数,并且需将use_beam_search参数设置为true,best_of参数设置大于1,top_k固定为-1。 "top_k": -1 "use_beam_search":true "best_of":2 |
|
ignore_eos |
否 |
False |
Bool |
ignore_eos表示是否忽略EOS并且继续生成token。 |
|
guided_json |
否 |
None |
Union[str, dict, BaseModel] |
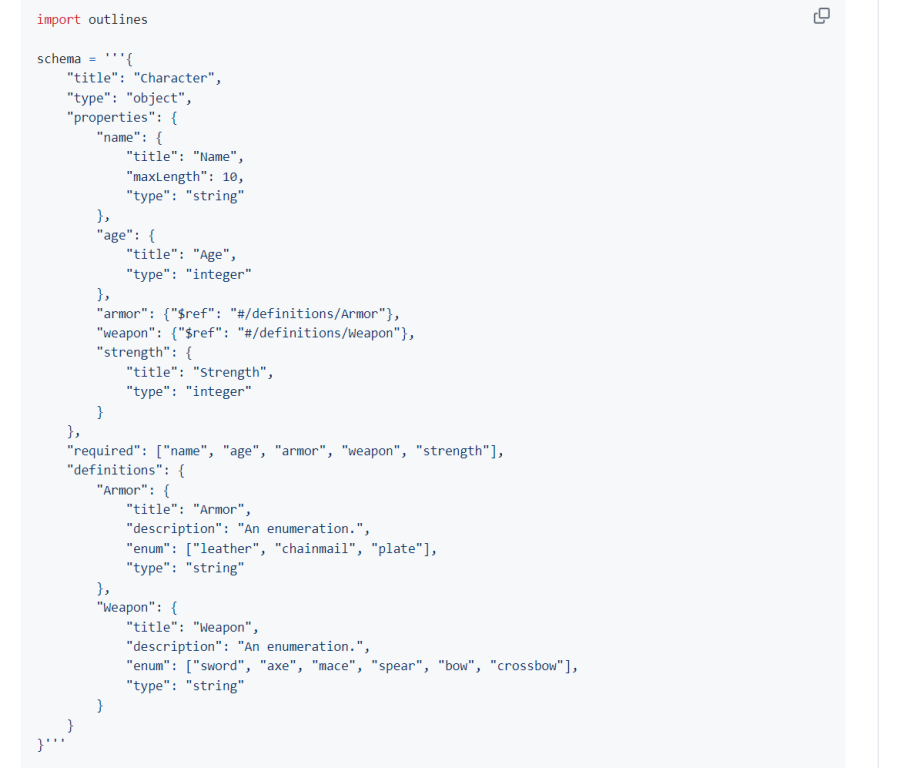
使用openai启动服务,如果需要使用JSON Schema时要配置guided_json参数。 JSON Schema使用专门的关键字来描述数据结构,例如标题title、 类型type、属性properties,必选属性required 、定义definitions等,JSON Schema通过定义对象属性、类型、格式的方式来引导模型生成一个包含用户信息的JSON对象。 如果希望使用JSON Schema,guided_json的写法可参考outlines: Structured Text Generation中的“Efficient JSON generation following a JSON Schema”样例,如下图所示。
图3 guided_json样例
如果想在发送的请求中包含上述guided_json架构,可参考以下代码。如果prompt未提供充足信息可能导致返回的json文件部分结果为空。
curl -X POST http://${docker_ip}:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "${container_model_path}",
"prompt": "Meet our valorous character, named Knight, who has reached the age of 32. Clad in impenetrable plate armor, Knight is well-prepared for any battle. Armed with a trusty sword and boasting a strength score of 90, this character stands as a formidable warrior on the field.Please provide details for this character, including their Name, Age, preferred Armor, Weapon, and Strength",
"max_tokens": 200,
"temperature": 0,
"guided_json": "{\"title\": \"Character\", \"type\": \"object\", \"properties\": {\"name\": {\"title\": \"Name\", \"maxLength\": 10, \"type\": \"string\"}, \"age\": {\"title\": \"Age\", \"type\": \"integer\"}, \"armor\": {\"$ref\": \"#/definitions/Armor\"}, \"weapon\": {\"$ref\": \"#/definitions/Weapon\"}, \"strength\": {\"title\": \"Strength\", \"type\": \"integer\"}}, \"required\": [\"name\", \"age\", \"armor\", \"weapon\", \"strength\"], \"definitions\": {\"Armor\": {\"title\": \"Armor\", \"description\": \"An enumeration.\", \"enum\": [\"leather\", \"chainmail\", \"plate\"], \"type\": \"string\"}, \"Weapon\": {\"title\": \"Weapon\", \"description\": \"An enumeration.\", \"enum\": [\"sword\", \"axe\", \"mace\", \"spear\", \"bow\", \"crossbow\"], \"type\": \"string\"}}}"
}' |
- 方式三 online_serving.py 发送请求(单图单轮对话)
由于多模态推理涉及图片的编解码,所以采用脚本方式调用服务API。脚本中需要配置的参数如表2脚本参数说明所示。
import base64
import requests
import argparse
# Function to encode the image
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def post_img(args):
# Path to your image
image_path = args.image_path
# Getting the base64 string
image_base64 = encode_image(image_path)
headers = {
"Content-Type": "application/json"
}
payload = {
"model": args.model_path,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": args.text
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{image_base64}"
}
}
]
}
],
"max_tokens": args.max_tokens,
"temperature": args.temperature,
"ignore_eos": args.ignore_eos,
"stream": args.stream,
"top_k": args.top_k,
"top_p": args.top_p
}
response = requests.post(f"http://{args.docker_ip}:{args.served_port}/v1/chat/completions", headers=headers, json=payload)
print(response.json())
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# 必填
parser.add_argument("--model-path", type=str, required=True)
parser.add_argument("--image-path", type=str, required=True)
parser.add_argument("--docker-ip", type=str, required=True)
parser.add_argument("--served-port", type=str, required=True)
parser.add_argument("--text", type=str, required=True)
# 选填
parser.add_argument("--temperature", type=float, default=0) # 输出结果的随机性。可选
parser.add_argument("--ignore-eos", type=bool, default=False) # 在生成过程中是否忽略结束符号,在生成EOS token后继续生成token。可选
parser.add_argument("--top-k", type=int, default=-1) # 参数控制着生成结果的多样性。其值越小,生成的文本就越独特,但可能缺乏连贯性。相反,其值越大,文本就越连贯,但多样性也会降低。可选
parser.add_argument("--top-p", type=int, default=1.0) # 参数的取值范围为0到1。值越小,生成的内容就越意外,但可能牺牲连贯性。值越大,内容就越连贯,但意外性也会减弱。可选
parser.add_argument("--stream", type=int, default=False) # 是否开启流式推理。默认为False,表示不开启流式推理。
parser.add_argument("--max_tokens", type=int, default=16) # 生成序列的最大长度。必选
args = parser.parse_args()
post_img(args)运行此脚本:
python online_serving.py --model-path ${container_model_path} --image-path ${image_path} --docker-ip ${docker_ip} --served-port ${port} --text 图片内容是什么|
参数 |
是否必须 |
参数类型 |
描述 |
|---|---|---|---|
|
image_path |
是 |
str |
传给模型的图片路径 |
|
payload |
是 |
json |
单图单轮对话的post请求json, 可参考表2.请求服务json参数说明 |
|
docker_ip |
是 |
str |
启动多模态openAI服务的主机ip |
|
served_port |
是 |
str |
启动多模态openAI服务的端口号 |
|
参数 |
是否必须 |
默认值 |
参数类型 |
描述 |
|---|---|---|---|---|
|
model |
是 |
无 |
Str |
通过OpenAI服务API接口启动服务时,推理请求必须填写此参数。取值必须和启动推理服务时的model ${container_model_path}参数保持一致。 |
|
messages |
是 |
- |
Dict |
请求输入的问题和图片。`role`: 表示消息的发送者,这里只能为用户。`content`: 表示消息的内容,类型为list。单图单轮对话content必须包含两个元素,第一个元素type字段取值为text,表示文本类型, text字段取值为输入问题的字符串。 第二个元素`type`字段取值为image_url, 表示图片类型,image_url字段取值为是输入图片的base64编码。 |
|
max_tokens |
否 |
16 |
Int |
每个输出序列要生成的最大tokens数量。 |
|
top_k |
否 |
-1 |
Int |
控制要考虑的前几个tokens的数量的整数。设置为-1表示考虑所有tokens。 适当降低该值可以减少采样时间。 |
|
top_p |
否 |
1.0 |
Float |
控制要考虑的前几个tokens的累积概率的浮点数。必须在 (0, 1] 范围内。设置为1表示考虑所有tokens。 |
|
temperature |
否 |
1.0 |
Float |
控制采样的随机性的浮点数。较低的值使模型更加确定性,较高的值使模型更加随机。0表示贪婪采样。 |
|
stream |
否 |
False |
Bool |
是否开启流式推理。默认为False,表示不开启流式推理。 |
|
ignore_eos |
否 |
False |
Bool |
ignore_eos表示是否忽略EOS并且继续生成token。 |




