

创建算法
机器学习从有限的观测数据中学习一般性的规律,并利用这些规律对未知的数据进行预测。为了获取更准确的预测结果,用户需要选择一个合适的算法来训练模型。针对不同的场景,ModelArts提供大量的算法样例。以下章节提供了关于业务场景、算法学习方式、算法实现方式的指导。
选择算法的实现方式
ModelArts提供如下方式实现模型训练前的算法准备。
- 使用订阅算法
- 使用预置框架
如果您需要使用自己开发的算法,可以选择使用ModelArts预置框架。ModelArts支持了大多数主流的AI引擎,详细请参见预置训练引擎。这些预置引擎预加载了一些额外的python包,例如numpy等;也支持您通过在代码目录中使用“requirements.txt”文件安装依赖包。使用预置框架创建训练作业请参考开发用于预置框架训练的代码指导。
- 使用预置框架 + 自定义镜像:
如果先前基于预置框架且通过指定代码目录和启动文件的方式来创建的算法;但是随着业务逻辑的逐渐复杂,您期望可以基于预置框架修改或增加一些软件依赖的时候,此时您可以使用预置框架 + 自定义镜像的功能,即选择预置框架名称后,在预置框架版本下拉列表中选择“自定义”。
此功能与直接基于预置框架创建算法的区别仅在于,镜像是由用户自行选择的。用户可以基于预置框架制作自定义镜像。基于预置框架制作自定义镜像代码可参考使用预置镜像制作自定义镜像用于训练模型章节。
- 完全自定义镜像:
订阅算法和预置框架涵盖了大部分的训练场景。针对特殊场景,ModelArts支持用户构建自定义镜像用于模型训练。用户遵循ModelArts镜像的规范要求制作镜像,选择自己的镜像,并且通过指定代码目录(可选)和启动命令的方式来创建的训练作业。
自定义镜像需上传至容器镜像服务(SWR),才能用于ModelArts上训练,请参考使用自定义镜像训练模型。由于自定义镜像的制作要求用户对容器相关知识有比较深刻的了解,除非订阅算法和预置引擎无法满足需求,否则不推荐使用。

当使用完全自定义镜像创建训练作业时,“启动命令”必须在“/home/ma-user”目录下执行,否则训练作业可能会运行异常。
创建算法
您在本地或使用其他工具开发的算法,支持上传至ModelArts中统一管理。
- 创建算法的准备工作。
- 完成数据准备:已在ModelArts中创建可用的数据集,或者您已将用于训练的数据集上传至OBS目录。
- 准备训练脚本,并上传至OBS目录。训练脚本开发指导参见开发用于预置框架训练的代码或开发用于自定义镜像训练的代码。
- 在OBS创建至少1个空的文件夹,用于存储训练输出的内容。
- 确保您使用的OBS目录与ModelArts在同一区域。
- 进入算法创建页面。
- 登录ModelArts管理控制台,单击左侧菜单栏的。
- 在“我的算法”管理页面,单击“创建”,进入“创建算法”页面。填写算法的基本信息,包含“名称”和“描述”。
- 设置算法启动方式,有以下三种方式可以选择。
- 设置算法启动方式(预置框架) 图1 使用预置框架创建算法
 需根据实际算法代码情况设置“代码目录”和“启动文件”。选择的预置框架和编写算法代码时选择的框架必须一致。例如编写算法代码使用的是TensorFlow,则在创建算法时也要选择TensorFlow。
需根据实际算法代码情况设置“代码目录”和“启动文件”。选择的预置框架和编写算法代码时选择的框架必须一致。例如编写算法代码使用的是TensorFlow,则在创建算法时也要选择TensorFlow。表1 使用预置框架创建算法 参数
说明
“启动方式”
选择“预置框架”。
选择算法使用的预置框架引擎和引擎版本。
“代码目录”
算法代码存储的OBS路径。训练代码、依赖安装包或者预生成模型等训练所需文件上传至该代码目录下。
请注意不要将训练数据放在代码目录路径下。训练数据比较大,训练代码目录在训练作业启动后会下载至后台,可能会有下载失败的风险。
训练作业创建完成后,ModelArts会将代码目录及其子目录下载至训练后台容器中。
例如:OBS路径“obs://obs-bucket/training-test/demo-code”作为代码目录,OBS路径下的内容会被自动下载至训练容器的“${MA_JOB_DIR}/demo-code”目录中,demo-code为OBS存放代码路径的最后一级目录,用户可以根据实际修改。
说明:- 编程语言不限。
- 文件数(含文件、文件夹数量)小于或等于1000个。
- 文件总大小小于或等于5GB。
“启动文件”
必须为“代码目录”下的文件,且以“.py”结尾,即ModelArts目前只支持使用Python语言编写的启动文件。
代码目录路径中的启动文件为训练启动的入口。
- 设置算法启动方式(预置框架+自定义) 图2 使用预置框架+自定义镜像创建算法
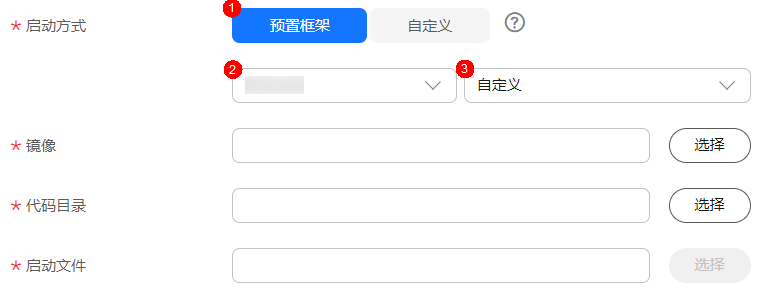 需根据实际算法代码情况设置“镜像”、“代码目录”和“启动文件”。选择的预置框架和编写算法代码时选择的框架必须一致。例如编写算法代码使用的是TensorFlow,则在创建算法时也要选择TensorFlow。
需根据实际算法代码情况设置“镜像”、“代码目录”和“启动文件”。选择的预置框架和编写算法代码时选择的框架必须一致。例如编写算法代码使用的是TensorFlow,则在创建算法时也要选择TensorFlow。表2 使用预置框架+自定义镜像创建算法 参数
说明
“启动方式”
选择“预置框架”。
预置框架的引擎版本选择“自定义”。
“镜像”
用户制作的镜像需要提前上传到SWR,才可以在这里选择。制作镜像的方式请参见训练作业的自定义镜像制作流程。
“代码目录”
算法代码存储的OBS路径。训练代码、依赖安装包或者预生成模型等训练所需文件上传至该代码目录下。
请注意不要将训练数据放在代码目录路径下。训练数据比较大,训练代码目录在训练作业启动后会下载至后台,可能会有下载失败的风险。
训练作业启动时,ModelArts会将训练代码目录及其子目录下载至训练后台容器中。
例如:OBS路径“obs://obs-bucket/training-test/demo-code”作为代码目录,OBS路径下的内容会被自动下载至训练容器的“${MA_JOB_DIR}/demo-code”目录中,demo-code为OBS存放代码路径的最后一级目录,用户可以根据实际修改。
说明:- 训练代码编程语言不限。训练启动文件必须为Python语言。
- 文件数(含文件、文件夹数量)小于或等于1000个。
- 文件总大小要小于或等于5GB。
- 文件深度要小于或等于32
“启动文件”
必须为“代码目录”下的文件,且以“.py”结尾,即ModelArts目前只支持使用Python语言编写的启动文件。
代码目录路径中的启动文件为训练启动的入口。
选择预置框架+自定义时,该功能的后台行为与直接基于预置框架运行训练作业相同,例如:- 系统将会自动注入一系列环境变量。
PATH=${MA_HOME}/anaconda/bin:${PATH} LD_LIBRARY_PATH=${MA_HOME}/anaconda/lib:${LD_LIBRARY_PATH} PYTHONPATH=${MA_JOB_DIR}:${PYTHONPATH} - 您选择的启动文件将会被系统自动以python命令直接启动,因此请确保镜像中的Python命令为您预期的Python环境。注意到系统自动注入的PATH环境变量,您可以参考下述命令确认训练作业最终使用的Python版本:
export MA_HOME=/home/ma-user; docker run --rm {image} ${MA_HOME}/anaconda/bin/python -V docker run --rm {image} $(which python) -V - 系统将会自动添加预置框架关联的超参。
- 设置算法启动方式(自定义) 图3 完全使用自定义镜像创建算法

表3 完全使用自定义镜像创建算法 参数
说明
“启动方式”
选择“自定义”。
“镜像”
用户制作的镜像需要提前上传到SWR,才可以在这里选择。制作镜像的方式请参见训练作业的自定义镜像制作流程。
“代码目录”
算法代码存储的OBS路径。训练代码、依赖安装包或者预生成模型等训练所需文件上传至该代码目录下。如果自定义镜像中不含训练代码则需要配置该参数,如果自定义镜像中已包含训练代码则不需要配置。
请注意不要将训练数据放在代码目录路径下。训练数据比较大,训练代码目录在训练作业启动后会下载至后台,可能会有下载失败的风险。
训练作业启动时,ModelArts会将训练代码目录及其子目录下载至训练后台容器中。
例如:OBS路径“obs://obs-bucket/training-test/demo-code”作为代码目录,OBS路径下的内容会被自动下载至训练容器的“${MA_JOB_DIR}/demo-code”目录中,demo-code为OBS存放代码路径的最后一级目录,用户可以根据实际修改。
说明:- 训练代码编程语言不限。训练启动文件必须为Python语言。
- 文件数(含文件、文件夹数量)小于或等于1000个。
- 文件总大小要小于或等于5GB。
- 文件深度要小于或等于32
“启动命令”
必填,镜像的启动命令。
运行训练作业时,当“代码目录”下载完成后,“启动命令”会被自动执行。- 如果训练启动脚本用的是py文件,例如“train.py”,则启动命令如下所示。
python ${MA_JOB_DIR}/demo-code/train.py - 如果训练启动脚本用的是sh文件,例如“main.sh”,则启动命令如下所示。
bash ${MA_JOB_DIR}/demo-code/main.sh
启动命令支持使用“;”和“&&”拼接多条命令,命令中的“demo-code”为存放代码目录的最后一级OBS目录,以实际情况为准。
当存在输入管道、输出管道、或是超参的情况下,请保证启动命令的最后一条命令是运行训练脚本。
原因:系统会将输入管道、输出管道、以及超参添加到启动命令的末尾,如果最后一条命令不是运行训练脚本则会报错。
例如:启动命令的最后一条是python train.py,且存在--data_url超参,系统正常运行会执行python train.py --data_url=/input。但是当启动命令python train.py后面有其他命令时,如下所示:
python train.py pwd #反例,启动命令的最后一条命令不是运行训练脚本,而是pwd
此时,如果拼接了输入管道、输出管道、以及超参,系统运行实际执行的是python train.py pwd --data_url=/input,就会报错。
训练支持的自定义镜像使用说明请参考自定义镜像的启动命令规范。
- 设置算法启动方式(预置框架)
- 输入输出管道设置。
训练过程中,算法需要从OBS桶或者数据集中获取数据进行模型训练,训练产生的输出结果也需要存储至OBS桶中。用户的算法代码中需解析输入输出参数实现ModelArts后台与OBS的数据交互,用户可以参考准备模型训练代码完成适配ModelArts训练的代码开发。
- 输入配置
表4 输入配置 参数
参数说明
参数名称
根据实际代码中的输入数据参数定义此处的名称。此处设置的代码路径参数必须与算法代码中解析的训练输入数据参数保持一致,否则您的算法代码无法获取正确的输入数据。
例如,算法代码中使用argparse解析的data_url作为输入数据的参数,那么创建算法时就需要配置输入数据的参数名称为“data_url”。
描述
输入参数的说明,用户可以自定义描述。
获取方式
输入参数的获取方式,默认使用“超参”,也可以选择“环境变量”。
输入约束
开启后,用户可以根据实际情况限制数据输入来源。输入来源可以选择“数据存储位置”或者“ModelArts数据集”。
添加
用户可以根据实际算法添加多个输入数据来源。
- 输出配置
- 输入配置
- 定义超参。
创建算法时,ModelArts支持用户自定义超参,方便用户查阅或修改。定义超参后会体现在启动命令中,以命令行参数的形式传入您的启动文件中。
- 编辑超参。
为保证数据安全,请勿输入敏感信息,例如明文密码。
表6 编辑超参数 参数
说明
名称
填入超参名称。
超参名称支持64个以内字符,仅支持大小写字母、数字、下划线和中划线。
类型
填入超参的数据类型。支持String、Integer、Float和Boolean。
默认值
填入超参的默认值。创建训练作业时,默认使用该值进行训练。
约束
单击“约束”。在弹出对话框中,支持用户设置默认值的取值范围或者枚举值范围。
必须
选择是或否。
- 选择否,则在使用该算法创建训练作业时,支持在创建训练作业页面删除该超参。
- 选择是,则在使用该算法创建训练作业时,不支持在创建训练作业页面删除该超参。
描述
填入超参的描述说明。
超参描述支持大小写字母、中文、数字、空格、中划线、下划线、中英文逗号和中英文句号。
- 支持的策略。
ModelArts支持用户使用自动化搜索功能。自动化搜索功能在零代码修改的前提下,自动找到最合适的超参,有助于提高模型精度和收敛速度。详细的参数配置请参考创建自动模型优化的训练作业。
自动搜索目前仅支持“tensorflow_2.1.0-cuda_10.1-py_3.7-ubuntu_18.04-x86_64”和“pytorch_1.8.0-cuda_10.2-py_3.7-ubuntu_18.04-x86_64”镜像
- 添加训练约束。
- 资源类型:选择适用的资源类型,支持多选。
- 多卡训练:选择是否支持多卡训练。
- 分布式训练:选择是否支持分布式训练。
- 当创建算法的参数配置完成后,单击“提交”,返回算法管理列表。
运行环境预览
创建算法时,可以打开创建页面右下方的运行环境预览窗口 ,辅助您了解代码目录、启动文件、输入输出等数据配置在训练容器中的路径。
,辅助您了解代码目录、启动文件、输入输出等数据配置在训练容器中的路径。
发布算法到AI gallery
发布算法:创建完成的算法,支持发布到AI Gallery,并分享给其他用户使用。
- 如果首次发布算法,则“发布方式”选择“创建新资产”,填写“资产标题”、选择发布区域等信息。
- 如果是为了更新已发布的算法版本,则“发布方式”选择“添加资产版本”,在“资产标题”下拉框中选择已有资产标题,填写“资产版本”。
如果是首次在AI Gallery发布资产则此处会出现勾选“我已阅读并同意《华为云AI Gallery百模千态社区服务声明》和《华为云AI Gallery服务协议》”选项,需要阅读并勾选同意才能正常发布资产。
提交资产发布申请后,AI Gallery侧会自动托管上架,可以前往AI Gallery查看资产上架情况。
删除算法

删除后,创建的算法资产会被删除,且无法恢复,请谨慎操作。
删除我的算法:在页面,“删除”运行结束的训练作业。您可以单击“操作”列的“删除”,在弹出的提示框中,输入DELETE,单击“确定”,删除对应的算法。
删除订阅算法:前往AI Gallery,在“我的资产 > 算法”中,单击我的订阅,对需要删除的算法单击“取消订阅”,在弹出的提示框中单击“确定”即可。




