

NPU服务器上配置轻量算力节点资源软件环境
场景说明
本文旨在指导如何在基于NPU资源的轻量算力节点服务器上,进行磁盘合并挂载、安装Docker等环境配置。具体配置项如表1所示。
当前指导中很多配置在最新发放的轻量算力节点服务器中已经预置,无需用户再手动配置,用户在操作中如发现某个步骤已有预置配置可直接跳过该步骤。
配置注意事项
在配置前请注意如下事项:
- 首次装机时需要配置存储、固件、驱动、网络访问等基础内容,这部分配置尽量稳定减少变化。
- 裸机上的开发形式建议开发者启动独立的Docker容器作为个人开发环境。Snt9b的裸机包含8卡算力资源,一般来说多人可以共用这个裸机完成开发与调测工作。多人使用为了避免冲突,建议各自在自己的Docker容器中进行独立开发,并提前规划好每个人使用的具体卡号,避免相互影响。
- ModelArts提供了标准化基础容器镜像,在容器镜像中已经预置了基础MindSpore或PyTorch框架和开发调测工具链,推荐用户直接使用该镜像,用户也可以使用自己的业务镜像或AscendHub提供的镜像。如果镜像中预置的软件版本不是您期望的版本,可以自行安装替换。
- 开发形式推荐通过容器中暴露的SSH端口以远程开发的模式(VSCode SSH Remote、 Xshell)连接到容器中进行开发,可以在容器中挂载宿主机的个人存储目录,用于存放代码和数据。
服务器SSH连接超时参数
- SSH登录到轻量算力节点服务器后,查看机器配置的超时参数。
echo $TMOUT
- 如果该值为300,则代表默认空闲等待5分钟后会断开连接,可以增大该参数延长空闲等待时间;如果该值为0可跳过当前步骤。修改方法如下:
vim /etc/profile # 在文件最后修改TMOUT值,由300改为0,0表示不会空闲断开 export TMOUT=0
- 执行如下命令使其在当前terminal生效。
TMOUT=0
export TMOUT=0这个命令在SSH连接Linux服务器时的作用是设置会话的空闲超时时间为0,意味着不会因为空闲而自动断开连接。默认情况下,SSH连接可能会在一段时间没有操作后自动断开,这是为了安全考虑。但是,如果您正在进行需要长时间保持连接的任务,可以使用这个命令来防止连接因为空闲而断开。
您可以在当前的终端会话中直接执行TMOUT=0使设置立即生效,或者将export TMOUT=0添加到/etc/profile文件中,以确保所有用户的新会话都不会因为空闲而断开。
但是在生产环境或多人使用的公共服务器上,不建议设置TMOUT=0,关闭自动注销功能会带来一定的安全风险。
磁盘合并挂载
开通轻量算力节点资源后,服务器上可能会有多个未挂载的nvme磁盘。因此在首次配置环境前,需要完成磁盘合并挂载。此操作需要放在最开始完成,避免使用一段时间后再挂载会冲掉用户已存储的内容。
- 购买并使用云存储,定期进行数据与模型文件同步;
- 在训练或开发代码中加入定期Checkpoint或自动保存机制,及时保存模型参数和关键中间结果。
通过以上措施,可有效降低本地磁盘故障对任务稳定性和数据安全的影响。
以下介绍磁盘合并挂载具体操作步骤。
- 首先通过“lsblk”查看是否有3个7T的磁盘未挂载。 如图1所示nvme0n1、nvme1n1、nvme2n1为未挂载。如图2 磁盘已挂载所示,每个盘后已有MOUNTPOINT,则代表已经执行过挂载操作,可跳过此章节,只用直接在/home目录下创建自己的个人开发目录即可。
- 编辑磁盘挂载脚本create_disk_partitions.sh。该脚本将“/dev/nvme0n1”挂载在“/home”下供每个开发者创建自己的家目录,将nvme1n1、nvme2n1两个本地盘合并挂载到“/docker”下供容器使用(如果不单独给“/docker”分配较大空间,当多人共用同一台轻量算力节点并创建多个容器实例时容易将根目录占满)。
vim create_disk_partitions.sh
create_disk_partitions.sh脚本内容如下,可以直接使用,不需要修改。
# ============================================================================ # 将nvme0n1本地盘挂载到/home目录下, # 将nvme1n1、nvme2n1本地盘合并作为逻辑卷统一挂载到/docker目录下,并设置开机自动挂载。 # ============================================================================ set -e # 将nvme0n1挂载到用户目录 mkfs -t xfs /dev/nvme0n1 mkdir -p /tmp/home cp -r /home/* /tmp/home/ mount /dev/nvme0n1 /home mv /tmp/home/* /home/ rm -rf /tmp/home # 将nvme1n1、nvme2n1合并挂载到/docker目录 pvcreate /dev/nvme1n1 pvcreate /dev/nvme2n1 vgcreate nvme_group /dev/nvme1n1 /dev/nvme2n1 lvcreate -l 100%VG -n docker_data nvme_group mkfs -t xfs /dev/nvme_group/docker_data mkdir /docker mount /dev/nvme_group/docker_data /docker # 迁移docker文件到新的/docker目录 systemctl stop docker mv /var/lib/docker/* /docker sed -i '/"default-runtime"/i\ "data-root": "/docker",' /etc/docker/daemon.json systemctl start docker # 设置开机自动挂载 uuid=`blkid -o value -s UUID /dev/nvme_group/docker_data` && echo UUID=${uuid} /docker xfs defaults,nofail 0 0 >> /etc/fstab uuid=`blkid -o value -s UUID /dev/nvme0n1` && echo UUID=${uuid} /home xfs defaults,nofail 0 0 >> /etc/fstab mount -a df -h
- 执行自动化挂载脚本create_disk_partitions.sh。
sh create_disk_partitions.sh
- 配置完成后,执行“df -h”可以看到新挂载的磁盘信息。 图3 查看新挂载的磁盘

- 磁盘合并挂载后,即可在“/home”下创建自己的工作目录,以自己的名字命名。


安装驱动和固件
- 首先检查npu-smi工具是否可以正常使用,该工具必须能正常使用才能继续后面的固件驱动安装。执行以下命令,完整输出图4 检查npu-smi工具内容则为正常。
npu-smi info
如果命令未按照下图完整输出(比如命令报错或只输出了上半部分没有展示下面的进程信息),则需要先尝试恢复npu-smi工具(提交工单联系华为云技术支持),将npu-smi恢复后,再进行新版本的固件驱动安装。
- 查看环境信息。执行如下命令查看当前拿到的机器的固件和驱动版本。
npu-smi info -t board -i 1 | egrep -i "software|firmware"
图5 查看固件和驱动版本
其中firmware代表固件版本,software代表驱动版本。
如果机器上的版本不是所需的版本(例如需要换成社区最新调测版本),可以参考后续步骤进行操作。
- 查看机器操作系统版本,以及架构是aarch64还是x86_64,并从Ascend官网获取相关的固件驱动包。固件包名称为“Ascend-hdk-型号-npu-firmware_版本号.run”,驱动包名称为“Ascend-hdk-型号-npu-driver_版本号_linux-aarch64.run”,商用版权限受控,仅华为工程师和渠道用户有权限下载,下载地址请见固件驱动包下载链接。
arch cat /etc/os-release
图6 查看机器操作系统版本及架构
下文均以适配EulerOS 2.0(SP10)和aarch64架构的包为例来进行讲解。
- 安装驱动和固件。
 固件和驱动安装时,请注意安装顺序:
固件和驱动安装时,请注意安装顺序:- 首次安装场景:硬件设备刚出厂时未安装驱动,或者硬件设备前期安装过驱动固件但是当前已卸载,上述场景属于首次安装场景,需按照“驱动->固件”的顺序安装驱动固件。
- 覆盖安装场景:硬件设备前期安装过驱动固件且未卸载,当前要再次安装驱动固件,此场景属于覆盖安装场景,需按照“固件->驱动”的顺序安装固件驱动。
通常Snt9b或Snt9b23出厂机器有预装固件驱动,因此本案例中是“覆盖安装场景”,注意:
如果新装的固件驱动比环境上已有的版本低,只要npu-smi工具可用,也是直接装新软件包即可,不用先卸载环境上已有的版本。如果固件驱动安装失败,可先根据报错信息在开发者社区搜索解决方案。
具体安装命令如下:- 安装固件,安装完后需要reboot重启机器。
chmod 700 *.run # 注意替换成实际的包名 ./Ascend-hdk-型号-npu-firmware_版本号.run --full reboot
- 安装驱动,在提示处输入“y”。
# 注意替换成实际的包名 ./Ascend-hdk-型号-npu-driver_版本号_linux-aarch64.run --full --install-for-all
- (可选)根据系统提示信息决定是否重启系统,如果需要重启,请执行以下命令;否则,请跳过此步骤。
reboot
- 安装完成后,执行下述命令检查固件和驱动版本,正常输出代表安装成功。
npu-smi info -t board -i 1 | egrep -i "software|firmware"
图7 检查固件和驱动版本

安装Docker环境
ModelArts轻量算力节点提供的公共镜像中均已安装Docker环境,如果用户需要自行安装可以参考以下步骤。
- 先执行如下命令检查机器是否已安装Docker。如果已安装,则可跳过此步骤。图8表示已安装Docker。
docker -v
如果未安装Docker,执行如下命令安装Docker。yum install -y docker-engine.aarch64 docker-engine-selinux.noarch docker-runc.aarch64
安装完成后,再次使用docker -v检查是否安装成功。
- 配置IP转发,用于容器内的网络访问。 如果不为1,执行下述命令配置IP转发。
sed -i 's/net\.ipv4\.ip_forward=0/net\.ipv4\.ip_forward=1/g' /etc/sysctl.conf sysctl -p | grep net.ipv4.ip_forward
- 查看环境是否已安装并配置Ascend-docker-runtime。
docker info |grep Runtime
如果输出的runtime为“ascend”,则代表已安装配置好,可跳过此步骤。图9 Ascend-docker-runtime查询 如果未安装,参考Ascend Docker Runtime获取,该软件包是昇腾提供的Docker插件,在docker run时可以自动挂载Ascend驱动等路径到容器,无需在启动容器时手工指定--device参数。下载好后将包上传到轻量算力节点服务器并进行安装。
如果未安装,参考Ascend Docker Runtime获取,该软件包是昇腾提供的Docker插件,在docker run时可以自动挂载Ascend驱动等路径到容器,无需在启动容器时手工指定--device参数。下载好后将包上传到轻量算力节点服务器并进行安装。chmod 700 *.run ./Ascend-hdk-型号-npu-driver_版本号_linux-aarch64.run --install
- 将新挂载的盘设置为Docker容器使用路径。 增加如下两项配置,注意insecure-registries行末尾增加一个逗号,保持json格式正确。其中“data_root”代表Docker数据存储路径,“default-shm-size”代表容器启动默认分配的共享内容大小,不配置时默认为64M,可以根据需要改大,避免分布式训练时共享内存不足导致训练失败。图10 Docker配置
 保存后,执行如下命令重启Docker使配置生效。
保存后,执行如下命令重启Docker使配置生效。systemctl daemon-reload && systemctl restart docker

安装pip源
- 执行如下命令检查是否已安装pip且pip源正常访问,如果能正常执行,可跳过此章节。
pip install numpy
- 如果物理机上没有安装pip,可执行如下命令安装。
python -m ensurepip --upgrade ln -s /usr/bin/pip3 /usr/bin/pip
- 配置pip源。
mkdir -p ~/.pip vim ~/.pip/pip.conf
在“~/.pip/pip.conf”中写入如下内容。[global] index-url = http://mirrors.myhuaweicloud.com/pypi/web/simple format = columns [install] trusted-host=mirrors.myhuaweicloud.com
RoCE网络测试
以下RoCE网络测试操作步骤仅适用于Snt9b机型,Snt9b23机型的RoCE网络测试方法请参见轻量算力节点故障诊断。
- 安装cann-toolkit。 查看服务器是否已安装CANN Toolkit,如果显示有版本号则表示已安装。
cat /usr/local/Ascend/ascend-toolkit/latest/aarch64-linux/ascend_toolkit_install.info
如果未安装,则需要从官网下载相关软件包,此处以Ascend-cann-toolkit_8.0.1_linux-aarch64.run为例。
安装CANN Toolkit,注意替换包名。chmod 700 *.run ./Ascend-cann-toolkit_8.0.1_linux-aarch64.run --full --install-for-all
- 安装mpich-3.2.1.tar.gz。 单击此处下载,并执行以下命令安装。
mkdir -p /home/mpich mv /root/mpich-3.2.1.tar.gz /home/ cd /home/;tar -zxvf mpich-3.2.1.tar.gz cd /home/mpich-3.2.1 ./configure --prefix=/home/mpich --disable-fortran make && make install
- 设置环境变量和编译hccl算子。
export PATH=/home/mpich/bin:$PATH cd /usr/local/Ascend/ascend-toolkit/latest/tools/hccl_test export LD_LIBRARY_PATH=/home/mpich/lib/:/usr/local/Ascend/ascend-toolkit/latest/lib64:$LD_LIBRARY_PATH make MPI_HOME=/home/mpich ASCEND_DIR=/usr/local/Ascend/ascend-toolkit/latest
算子编译完成后显示内容如下:图11 算子编译完成
- 单机场景下进行all_reduce_test。 如果是单机单卡,则执行下述命令。
mpirun -n 1 ./bin/all_reduce_test -b 8 -e 1024M -f 2 -p 8
如果是单机多卡,则执行下述命令。mpirun -n 8 ./bin/all_reduce_test -b 8 -e 1024M -f 2 -p 8
图12 all_reduce_test
- 多机RoCE网卡带宽测试。
- 执行以下命令查看昇腾的RoCE IP。
cat /etc/hccn.conf
图13 查看昇腾的RoCE IP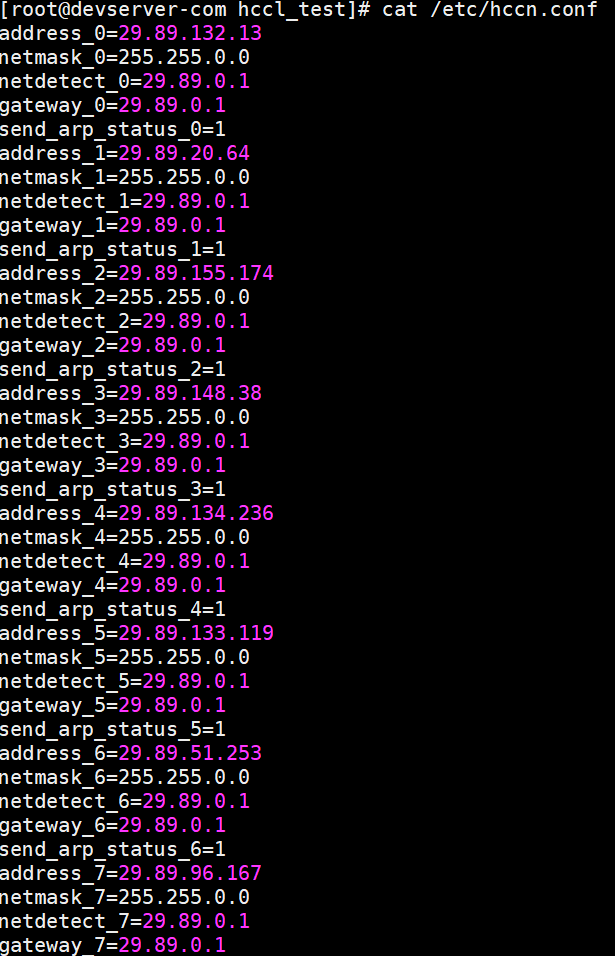
- RoCE测试。
hccn_tool -i 7 -roce_test reset hccn_tool -i 7 -roce_test ib_send_bw -s 4096000 -n 1000 -tcp
在Session2:在发送端执行-i卡id,后面的ip为上一步接收端卡的ip。
cd /usr/local/Ascend/ascend-toolkit/latest/tools/hccl_test hccn_tool -i 0 -roce_test reset hccn_tool -i 0 -roce_test ib_send_bw -s 4096000 -n 1000 address 192.168.100.18 -tcp
RoCE测试结果如图:
图14 RoCE测试结果(接收端) 图15 RoCE测试结果(服务端)
图15 RoCE测试结果(服务端)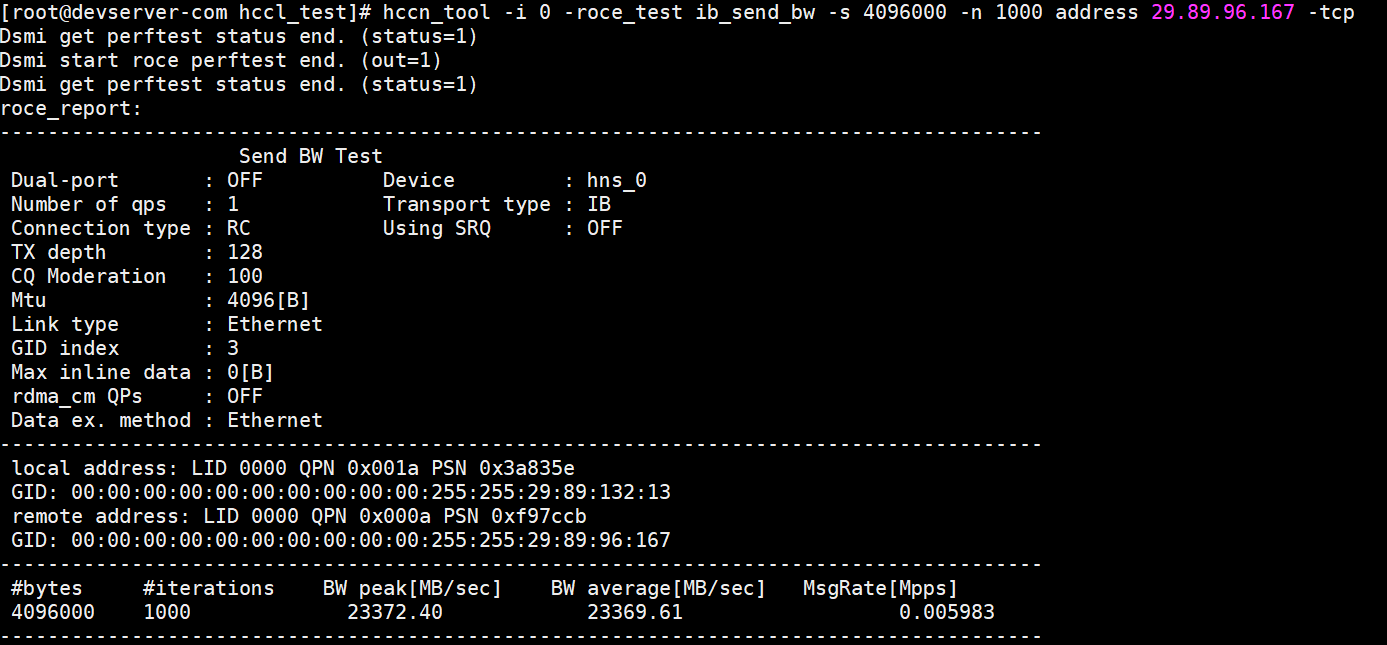
- 执行以下命令查看昇腾的RoCE IP。
- 当某网卡已经开始RoCE带宽测试时,再次启动任务会有如下报错: 图16 报错信息

需要执行下述命令后关闭roce_test任务后再启动任务。
hccn_tool -i 7 -roce_test reset
可执行如下命令查看网卡状态。for i in {0..7};do hccn_tool -i ${i} -link -g;done可执行如下命令查看普通节点内网卡IP连通性。for i in $(seq 0 7);do hccn_tool -i $i -net_health -g;done
容器化个人调测环境搭建
当前推荐的开发模式是在物理机上启动自己的Docker容器进行开发。容器镜像可以使用自己的实际业务镜像,也可以使用ModelArts提供的基础镜像,ModelArts提供两种基础镜像:Ascend+PyTorch镜像、Ascend+MindSpore镜像。
- 准备业务基础镜像。
- 根据所需要的环境拉取Ascend+PyTorch或Ascend+MindSpore镜像,镜像地址详见ModelArts产品发布说明中的基础镜像章节:
# 配套Snt9b的容器镜像,示例如下: docker pull swr.<region-code>.myhuaweicloud.com/atelier/<image-name>:<image-tag>
- 启动容器镜像,注意多人多容器共用机器时,需要将卡号做好预先分配,不能使用其他容器已使用的卡号。
# 启动容器,请注意指定容器名称、镜像信息。ASCEND_VISIBLE_DEVICES指定容器要用的卡,0-1,3代表0 1 3这3块卡,-用于指定范围 # -v /home:/home_host是指将宿主机的home目录挂载到容器内的home_host目录,建议在容器中使用该挂载目录进行代码和数据的存储,以便持久化保存数据 docker run -itd --cap-add=SYS_PTRACE -e ASCEND_VISIBLE_DEVICES=0 -v /home:/home_host -p 51234:22 -u=0 --name 自定义容器名称 上一步拉取的镜像SWR地址 /bin/bash
- 执行下述命令进入容器。
docker exec -ti 上一命令中的自定义容器名称 bash
- 执行下述命令进入conda环境。
source /home/ma-user/.bashrc cd ~
- 查看容器中可以使用的卡信息。
npu-smi info
如果命令报如下错误,则代表容器启动时指定的“ASCEND_VISIBLE_DEVICES”卡号已被其他容器占用,此时需要重新选择卡号并重新启动新的容器。图17 报错信息
- npu-smi info检测正常后,可以执行一段命令进行简单的容器环境测试,能正常输出运算结果代表容器环境正常可用。
- PyTorch镜像测试:
python3 -c "import torch;import torch_npu; a = torch.randn(3, 4).npu(); print(a + a);"
- mindspore镜像测试:
# 由于mindspore的run_check程序当前未适配Snt9b,需要先设置2个环境变量才能测试 unset MS_GE_TRAIN unset MS_ENABLE_GE python -c "import mindspore;mindspore.set_context(device_target='Ascend');mindspore.run_check()" # 测试完需要恢复环境变量,实际跑训练业务的时候需要用到 export MS_GE_TRAIN=1 export MS_ENABLE_GE=1
图18 进入conda环境并进行测试
- PyTorch镜像测试:
- 根据所需要的环境拉取Ascend+PyTorch或Ascend+MindSpore镜像,镜像地址详见ModelArts产品发布说明中的基础镜像章节:
- (可选)配置容器SSH可访问。
如果在开发时,需要使用VS Code或SSH工具直接连接到容器中进行开发,需要进行以下配置。
- 进入容器后,执行SSH启动命令来启动SSH服务:
ssh-keygen -A /usr/sbin/sshd # 查看ssh进程已启动 ps -ef |grep ssh
- 设置容器root密码,根据提示输入新密码:
passwd
图19 设置root密码
- 执行exit命令退出容器,在宿主机上执行ssh测试:
ssh root@宿主机IP -p 51234(映射的端口号)
图20 执行ssh测试
如果在宿主机执行ssh容器测试时报错Host key verification failed,可删除宿主机上的文件~/.ssh/known_host后再重试。
- 使用VS Code SSH连接容器环境。
如果之前未使用过VS Code SSH功能,可参考Step1 添加Remote-SSH插件进行VSCode环境安装和Remote-SSH插件安装。
打开VSCode Terminal,执行如下命令在本地计算机生成密钥对,如果您已经有一个密钥对,则可以跳过此步骤:ssh-keygen -t rsa
将公钥添加到远程服务器的授权文件中,注意替换服务器IP以及容器的端口号:cat ~/.ssh/id_rsa.pub | ssh root@服务器IP -p 容器端口号 "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys"
打开VSCode的Remote-SSH配置文件,添加SSH配置项,注意替换服务器IP以及容器的端口号:Host Snt9b-dev HostName 服务器IP User root port 容器SSH端口号 identityFile ~\.ssh\id_rsa StrictHostKeyChecking no UserKnownHostsFile /dev/null ForwardAgent yes注意:这里是使用密钥登录,如果需要使用密码登录,请去掉identityFile配置,并在连接过程中根据提示多次输入密码。
连接成功后安装python插件,请参考安装Python插件。
- 进入容器后,执行SSH启动命令来启动SSH服务:
- (可选)安装CANN Toolkit。
当前ModelArts提供的预置镜像中已安装CANN Toolkit,如果需要替换版本或者使用自己的未预置CANN Toolkit的镜像,可参考如下章节进行安装。
- 查看容器内是否已安装CANN Toolkit,如果显示有版本号则已安装:
cat /usr/local/Ascend/ascend-toolkit/latest/aarch64-linux/ascend_toolkit_install.info
- 如果未安装或需要升级版本,则需要从官网下载相关软件包,此处以Ascend-cann-toolkit_8.0.1_linux-aarch64.run为例。 安装CANN Toolkit,注意替换包名。
chmod 700 *.run ./Ascend-cann-toolkit_8.0.1_linux-aarch64.run --full --install-for-all
- 如果已安装,但需要升级版本,注意替换包名:
chmod 700 *.run ./Ascend-cann-toolkit_6.3.RC2_linux-aarch64.run --upgrade --install-for-all
- 查看容器内是否已安装CANN Toolkit,如果显示有版本号则已安装:
- (可选)安装MindSpore Lite。
当前预置镜像中已安装MindSpore Lite,如果需要替换版本或者使用自己的未预置MindSpore Lite的镜像,可参考如下章节进行安装。
- 查看容器中是否已安装MindSpore Lite,如果已经显示出mindspore-lite软件信息和版本号,则是已经安装好的:
pip show mindspore-lite
- 如果未安装,则从官网下载包(下载链接),下载whl包和tar.gz包并执行安装,注意替换包名:
pip install mindspore_lite-2.1.0-cp37-cp37m-linux_aarch64.whl mkdir -p /usr/local/mindspore-lite tar -zxvf mindspore-lite-2.1.0-linux-aarch64.tar.gz -C /usr/local/mindspore-lite --strip-components 1
- 查看容器中是否已安装MindSpore Lite,如果已经显示出mindspore-lite软件信息和版本号,则是已经安装好的:
- 配置pip源。
使用ModelArts提供的预置镜像中pip源已经直接配置好可用,如果用户使用自己的业务镜像,可参考安装pip源进行配置。
- 配置yum源。
- 华为EulerOS系统下配置yum源
#在/etc/yum.repos.d/目录下,创建文件EulerOS.repo, cd /etc/yum.repos.d/ mv EulerOS.repo EulerOS.repo.bak vim EulerOS.repo #根据EulerOS版本及系统架构选择配置EulerOS.repo文件内容,此处以EulerOS 2.10为例,请根据实际情况调整。 [base] name=EulerOS-2.0SP10 base baseurl=https://mirrors.huaweicloud.com/euler/2.10/os/aarch64/ enabled=1 gpgcheck=1 gpgkey=https://mirrors.huaweicloud.com/euler/2.10/os/RPM-GPG-KEY-EulerOS #清除原有yum缓存 yum clean all #生成新的yum缓存 yum makecache # 测试 yum update --allowerasing --skip-broken --nobest
- HCE OS系统下配置yum源
#下载新的hce.repo文件到/etc/yum.repos.d/目录下 wget -O /etc/yum.repos.d/hce.repo https://mirrors.huaweicloud.com/artifactory/os-conf/hce/hce.repo #清除原有yum缓存 yum clean all #生成新的yum缓存 yum makecache # 测试 yum update --allowerasing --skip-broken --nobest
- 华为EulerOS系统下配置yum源
-
git clone和git-lfs下载大模型可以参考如下操作。
- 由于欧拉源上没有git-lfs包,所以需要从压缩包中解压使用,在浏览器中输入如下地址下载git-lfs压缩包并上传到服务器的/home目录下,该目录在容器启动时挂载到容器/home_host目录下,这样在容器中可以直接使用。
https://github.com/git-lfs/git-lfs/releases/download/v3.2.0/git-lfs-linux-arm64-v3.2.0.tar.gz
- 进入容器,执行安装git-lfs命令。
cd /home_host tar -zxvf git-lfs-linux-arm64-v3.2.0.tar.gz cd git-lfs-3.2.0 sh install.sh
- 设置git配置去掉ssl校验。
git config --global http.sslVerify false
- git clone代码仓,以diffusers为例(注意替换用户个人开发目录)。
# git clone diffusers源码,-b参数可指定分支,注意替换用户个人开发目录 cd /home_host/用户个人目录 mkdir sd cd sd git clone https://github.com/huggingface/diffusers.git -b v0.11.1-patch
git clone HuggingFace上的模型,以SD模型为例。
下载时如果出现“SSL_ERROR_SYSCALL”报错,多重试几次即可。另外由于网络限制以及文件较大,下载可能很慢需要数个小时,如果重试多次还是失败,建议直接从网站下载大文件后上传到服务器/home目录的个人开发目录中。如果下载时需要跳过大文件,可以设置GIT_LFS_SKIP_SMUDGE=1。git lfs install git clone https://huggingface.co/runwayml/stable-diffusion-v1-5 -b onnx图21 代码下载成功
- 由于欧拉源上没有git-lfs包,所以需要从压缩包中解压使用,在浏览器中输入如下地址下载git-lfs压缩包并上传到服务器的/home目录下,该目录在容器启动时挂载到容器/home_host目录下,这样在容器中可以直接使用。
- 当容器需要提供服务给多个用户,或者多个用户共享使用该容器时,应限制容器访问OpenStack的管理地址(169.254.169.254),以防止容器获取宿主机的元数据。具体操作请参见禁止容器获取宿主机元数据。
- 容器环境保存镜像。
配置好环境后可以进行业务代码的开发调试。通常为了避免机器重启后环境丢失,建议将已经配好的环境保存成新的镜像,命令如下:
# 查看需要保存为镜像的容器ID docker ps # 保存镜像 docker commit 容器ID 自定义镜像名:自定义镜像tag # 查看已保存的镜像 docker images # 如果需要将镜像分享给其他人在其他环境使用,可将镜像保存为本地tar文件(该命令耗时较久),保存完后使用ls命令即可查看到该文件 docker save -o 自定义名称.tar 镜像名:镜像tag # 其他机器上使用时加载文件,加载好后docker images即可查看到该镜像 docker load --input 自定义名称.tar
到此环境配置就结束了,后续可以根据相关的迁移指导书做业务迁移到昇腾的开发调测工作。




