

使用CES监控轻量算力节点NPU资源
场景描述
轻量算力节点的监控能力依赖于CES云监控服务。本文主要介绍如何对接CES云监控服务,对轻量算力节点上的资源和事件进行监控。
约束限制
- 监控需要用到CES Agent插件,Agent有严格的资源占用限制,当资源占用超过阈值后出现Agent熔断情况,详细的资源占用说明请参考CES产品文档相关章节:CES Agent性能说明。
- 通过Ascend-dmi执行NPU压测命令可能会导致丢失部分NPU指标数据。
- 监控Agent已在轻量算力节点提供的公共镜像中经过充分测试,如果您使用自己的镜像,建议测试后再部署到生产环境,防止信息错误。
前提条件
轻量算力节点中已经安装CES Agent插件,判断是否安装CES Agent插件及安装方式请参见安装CES Agent监控插件。
轻量算力节点监控方案介绍
详细监控方案介绍请参考BMS主机监控概述。除文档所列支持的镜像之外,目前还支持Ubuntu20.04。
监控指标采样周期为1分钟,请勿修改,否则可能导致功能不正常。当前监控指标项已经包含CPU、内存、磁盘、网络。在主机上安装加速卡驱动后,可以自动采集相关指标。
NPU相关指标采集功能运行依赖Linux系统工具lspci,部分事件依赖blkid、grub2-editenv系统工具,请确保这些工具功能正常。
| 工具名称 | 检查方法 | 安装方法 |
|---|---|---|
| lspci | 在shell环境中执行lspci,能够正常查询系统中的PCI设备,示例如下: $ sudo lspci 00:00.0 PCI bridge: Huawei Technologies Co., Ltd. HiSilicon PCIe Root Port with Gen4 (rev 21) 00:08.0 PCI bridge: Huawei Technologies Co., Ltd. HiSilicon PCIe Root Port with Gen4 (rev 21) 00:10.0 PCI bridge: Huawei Technologies Co., Ltd. HiSilicon PCIe Root Port with Gen4 (rev 21) | lspci是用于显示PCI设备信息的工具,通常包含在pciutils软件包中。大多数Linux发行版默认安装了这个软件包,所以lspci通常是预装的。如果lspci未安装,可以使用包管理器安装pciutils。 在Debian/Ubuntu系统中: sudo apt-get update sudo apt-get install pciutils 在Red Hat/CentOS/EulerOS系统中: sudo yum install pciutils |
| blkid | 在shell环境中执行blkid,能够查询系统中的块设备信息,示例如下: $ sudo blkid /dev/sda1: UUID="123e4567-e89b-12d3-a456-426614174000" TYPE="vfat" PARTUUID="56789abc-def0-1234-5678-9abcd3f2c0a1" /dev/sda2: UUID="a1b2c3d4-e5f6-789a-bcde-f0123456789a" TYPE="swap" PARTUUID="edcba98-7654-3210-fedc-ba9876543210" /dev/sda3: UUID="01234567-89ab-cdef-0123-456789abcdef" TYPE="ext4" PARTUUID="fedcba09-8765-4321-fedc-ba0987654321" | blkid是Linux系统中用于显示块设备属性的工具,通常包含在util-linux软件包中。大多数Linux发行版默认安装了这个软件包,所以blkid通常是预装的。如果blkid未安装,可以使用包管理器安装util-linux。 在Debian/Ubuntu系统中: sudo apt-get update sudo apt-get install util-linux 在Red Hat/CentOS/EulerOS系统中: sudo yum install util-linux |
| grub2-editenv(仅Red Hat、CentOS、EulerOS发行版需要) | 在shell环境中执行blkid,能够查询系统中的块设备信息,示例如下: 1 2 3 4 $ sudo grub2-editenv list timeout=5default=0saved_entry=Red Hat Enterprise Linux Server, with Linux 4.18.0-305.el8.x86_64 | grub2-editenv是GRUB2的一部分,用于管理GRUB环境变量。大多数Linux发行版默认安装了GRUB2,所以grub2-editenv通常是预装的。如果grub2-editenv未安装,可以使用包管理器安装grub2-editenv: 在Debian/Ubuntu系统中: sudo apt-get update sudo apt-get install grub2 在Red Hat/CentOS/EulerOS系统中: sudo yum install grub2 |
安装CES Agent监控插件
通过在轻量算力节点(ECS或BMS)中安装CES Agent插件,可以为用户提供服务器的系统级、主动式、细颗粒度监控服务。
轻量算力节点预置的操作系统中会默认安装CES Agent插件,此时在CES界面可以查看Agent插件状态和版本。
如果未安装CES Agent或者CES Agent版本不符合要求可以参考以下两种方式处理。
方式一:参考安装/升级轻量算力节点中的CES Agent插件,通过控制台安装。
方式二:手动安装CES Agent插件,具体步骤如下:
- 当前账户需要给CES授权委托,请参考创建用户并授权使用云监控服务。如果在表1时,开启了“CES主机监控授权”,此处无需重复执行授权操作。
- 当前暂不支持在CES界面直接一键安装监控,需要登录到服务器上执行以下命令安装配置Agent。其它region的安装请参考单台主机下安装Agent。
cd /usr/local && curl -k -O https://obs.cn-north-4.myhuaweicloud.com/uniagent-cn-north-4/script/agent_install.sh && bash agent_install.sh
安装成功的标志如下:
图1 安装成功提示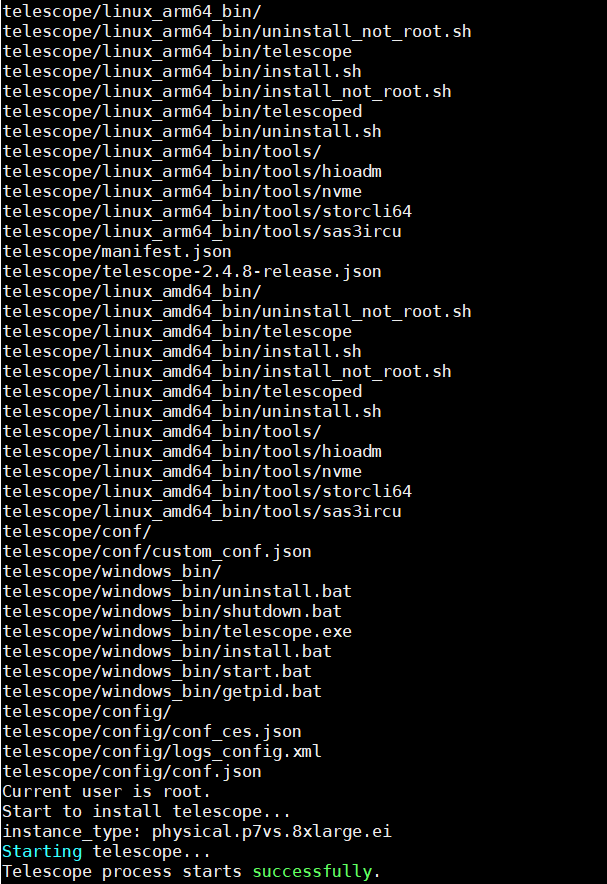
- 在CES界面查看具体的监控项,加速卡类的监控项必须在主机安装加速卡驱动后才会有相关指标。 图2 监控界面
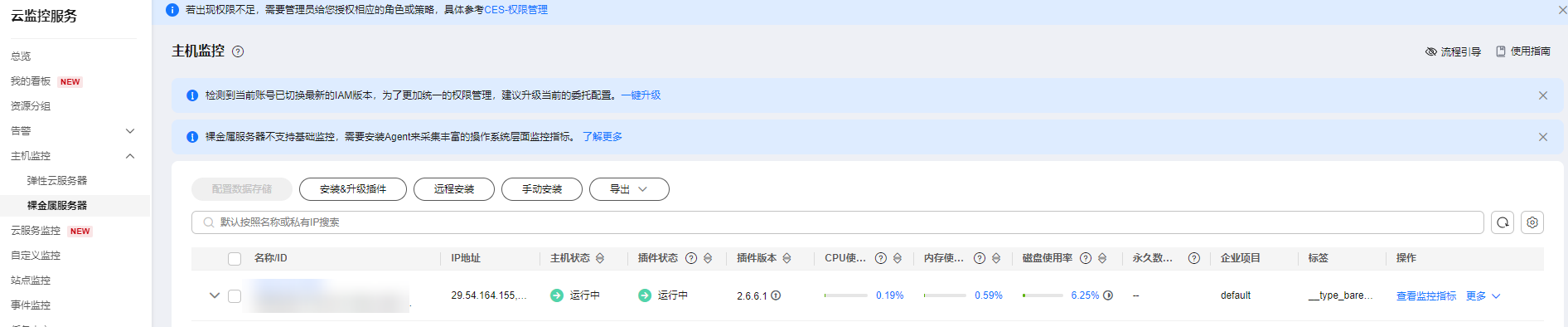
至此,监控插件已经安装完成,相关指标的采集可以在UI界面直接查看或者根据指标值配置相关告警。
监控指标的命名空间
AGT.ECS和SERVICE.BMS
训练推理重点查看指标
在轻量算力节点服务器中开展训练或推理任务时重点需要关注的指标如表2所示。
| 序号 | 分类 | 指标名称 | 显示名 | 说明 | 单位 | 进制 | 取值范围 | 适用机型 |
|---|---|---|---|---|---|---|---|---|
| 1 | 整体 | npu_device_health | NPU健康状况 | NPU卡的健康状况 | - | 不涉及 | 0:正常 1:一般告警 2:重要告警 3:紧急告警 | Snt3P 300IDuo Snt9b Snt9b23 |
| 2 | npu_util_rate_general | NPU整体利用率 | NPU整体利用率,包括对AI Core和Vector Core的整体统计。 | % | 不涉及 | 0~100% | Snt9b Snt9b23 | |
| 3 | DDR | npu_util_rate_mem | NPU显存使用率 | NPU卡的显存使用率 | % | 不涉及 | 0~100% | Snt3P 300IDuo |
| 4 | npu_util_rate_mem_bandwidth | NPU显存带宽使用率 | NPU卡的显存带宽使用率 | % | 不涉及 | 0~100% | ||
| 5 | HBM | npu_hbm_bandwidth_util | HBM带宽利用率 | NPU卡HBM带宽利用率(旧版指标) | % | 不涉及 | 0~100% | Snt9b Snt9b23 |
| 6 | npu_util_rate_hbm_bw | HBM带宽利用率 | NPU卡HBM带宽利用率(新版指标) | % | 不涉及 | 0~100% | Snt9b Snt9b23 | |
| 7 | AI Core | npu_util_rate_ai_core | NPU卡AI核心使用率 | NPU卡的AI核心使用率 | % | 不涉及 | 0~100% | Snt3P 300IDuo Snt9b Snt9b23 |
| 8 | AI Vector | npu_util_rate_vector_core | NPU卡Vector核心使用率 | NPU卡Vector核心使用率 | % | 不涉及 | 0~100% | Snt3P 300IDuo Snt9b Snt9b23 |
轻量算力节点监控指标(NPU整体)
此处仅展示NPU相关指标,具体如下表所示。其他指标项请参考CES Agent支持的指标列表。
| 序号 | 指标名称 | 显示名 | 说明 | 单位 | 进制 | 取值范围 | 维度 | 支持机型 | 支持CES Agent版本 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | npu_device_health | NPU健康状况 | NPU卡的健康状况 | - | 不涉及 | 0:正常 1:一般告警 2:重要告警 3:紧急告警 | instance_id,npu | Snt3P 300IDuo Snt9b Snt9b23 | telescope: 2.7.4.3 2.7.5.3 2.7.5.4 2.7.5.9及之后版本 |
| 2 | npu_driver_health | NPU驱动健康状况 | NPU卡的驱动的健康状况 | - | 不涉及 | 0:正常 3:紧急告警 | instance_id,npu | ||
| 3 | npu_power | NPU功率 | NPU卡功率 | W | 不涉及 | >0 | instance_id,npu | ||
| 4 | npu_temperature | NPU温度 | NPU卡温度 | °C | 不涉及 | 自然数 | instance_id,npu | ||
| 5 | npu_voltage | NPU电压 | 该指标描述NPU的电压 | V | 不涉及 | 自然数 | instance_id,npu | ||
| 6 | npu_util_rate_general | NPU整体利用率 | NPU整体利用率,包括对AI Core和Vector Core的整体统计。 | % | 不涉及 | 0~100% | instance_id,npu | Snt9b Snt9b23 |
轻量算力节点监控指标(HBM)
| 序号 | 指标名称 | 显示名 | 说明 | 单位 | 进制 | 取值范围 | 维度 | 支持机型 | 支持CES Agent版本 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | npu_util_rate_hbm | NPU的HBM占用率 | 该指标描述NPU的HBM占用率 | % | 不涉及 | 0~100% | instance_id,npu | Snt9b Snt9b23 | telescope: 2.7.4.3 2.7.5.3 2.7.5.4 2.7.5.9及之后版本 |
| 2 | npu_hbm_freq | HBM频率 | NPU卡HBM频率 (旧版指标) | MHz | 不涉及 | >0 | instance_id,npu | ||
| 3 | npu_freq_hbm | HBM频率 | NPU卡HBM频率(新版指标) | MHz | 不涉及 | >0 | instance_id,npu | ||
| 4 | npu_hbm_usage | HBM使用量 | NPU卡HBM使用量 | MB | 不涉及 | ≥0 | instance_id,npu | ||
| 5 | npu_hbm_temperature | HBM温度 | NPU卡HBM温度 | °C | 不涉及 | 自然数 | instance_id,npu | ||
| 6 | npu_hbm_bandwidth_util | HBM带宽利用率 | NPU卡HBM带宽利用率(旧版指标) | % | 不涉及 | 0~100% | instance_id,npu | ||
| 7 | npu_util_rate_hbm_bw | HBM带宽利用率 | NPU卡HBM带宽利用率(新版指标) | % | 不涉及 | 0~100% | instance_id,npu | ||
| 8 | npu_hbm_mem_capacity | NPU的HBM内存容量 | 该指标描述NPU的HBM内存容量 | MB | 不涉及 | ≥0 | instance_id,npu | ||
| 9 | npu_hbm_ecc_enable | HBM ECC开关状态 | NPU卡HBM ECC开关状态 | - | 不涉及 | 0:ecc检测未使能 1:ecc检测使能 | instance_id,npu | ||
| 10 | npu_hbm_single_bit_error_cnt | HBM当前单bit错误数量 | NPU卡HBM当前单bit错误数量 | count | 不涉及 | ≥0 | instance_id,npu | ||
| 11 | npu_hbm_double_bit_error_cnt | HBM当前双bit错误数量 | NPU卡HBM当前双bit错误数量 | count | 不涉及 | ≥0 | instance_id,npu | ||
| 12 | npu_hbm_total_single_bit_error_cnt | HBM生命周期内单bit错误数量 | NPU卡HBM生命周期内单bit错误数量 | count | 不涉及 | ≥0 | instance_id,npu | ||
| 13 | npu_hbm_total_double_bit_error_cnt | HBM生命周期内双bit错误数量 | NPU卡HBM生命周期内双bit错误数量 | count | 不涉及 | ≥0 | instance_id,npu | ||
| 14 | npu_hbm_single_bit_isolated_pages_cnt | HBM单比特错误隔离内存页数量 | NPU卡HBM单比特错误隔离内存页数量 | count | 不涉及 | ≥0 | instance_id,npu | ||
| 15 | npu_hbm_double_bit_isolated_pages_cnt | HBM多比特错误隔离内存页数量 | NPU卡HBM多比特错误隔离内存页数量 | count | 不涉及 | ≥0 | instance_id,npu |
轻量算力节点监控指标(DDR)
| 序号 | 指标名称 | 显示名 | 说明 | 单位 | 进制 | 取值范围 | 维度 | 支持机型 | 支持CES Agent版本 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | npu_usage_mem | NPU显存使用量 | NPU卡的显存使用量 | MB | 不涉及 | ≥0 | instance_id,npu | Snt3P 300IDuo | telescope: 2.7.4.3 2.7.5.3 2.7.5.4 2.7.5.9及之后版本 |
| 2 | npu_util_rate_mem | NPU显存使用率 | NPU卡的显存使用率 | % | 不涉及 | 0~100% | instance_id,npu | ||
| 3 | npu_freq_mem | NPU显存频率 | NPU卡的显存频率 | MHz | 不涉及 | >0 | instance_id,npu | ||
| 4 | npu_util_rate_mem_bandwidth | NPU显存带宽使用率 | NPU卡的显存带宽使用率 | % | 不涉及 | 0~100% | instance_id,npu | ||
| 5 | npu_sbe | NPU单bit错误数量 | NPU卡单比特错误数量 | count | 不涉及 | ≥0 | instance_id,npu | ||
| 6 | npu_dbe | NPU双bit错误数量 | NPU卡双比特错误数量 | count | 不涉及 | ≥0 | instance_id,npu |
轻量算力节点监控指标(AI Core)
| 序号 | 指标名称 | 显示名 | 说明 | 单位 | 进制 | 取值范围 | 维度 | 支持机型 | 支持CES Agent版本 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | npu_freq_ai_core | NPU卡AI核心频率 | NPU卡的AI核心时钟频率 | MHz | 不涉及 | >0 | instance_id,npu | Snt3P 300IDuo Snt9b Snt9b23 | telescope: 2.7.4.3 2.7.5.3 2.7.5.4 2.7.5.9及之后版本 |
| 2 | npu_freq_ai_core_rated | NPU的AI核心额定频率 | 该指标描述NPU的AI核心额定频率 | MHz | 不涉及 | >0 | instance_id,npu | ||
| 3 | npu_util_rate_ai_core | NPU卡AI核心使用率 | NPU卡的AI核心使用率 | % | 不涉及 | 0~100% | instance_id,npu |
轻量算力节点监控指标(AI Vector)
| 序号 | 指标名称 | 显示名 | 说明 | 单位 | 进制 | 取值范围 | 维度 | 支持机型 | 支持CES Agent版本 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | npu_util_rate_vector_core | NPU卡Vector核心使用率 | NPU卡Vector核心使用率 | % | 不涉及 | 0~100% | instance_id,npu | Snt3P 300IDuo Snt9b Snt9b23 | telescope: 2.7.5.9及之后版本 |
轻量算力节点监控指标(AI CPU)
| 序号 | 指标名称 | 显示名 | 说明 | 单位 | 进制 | 取值范围 | 维度 | 支持机型 | 支持CES Agent版本 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | npu_aicpu_num | NPU的AI CPU 数量 | 该指标描述NPU的AI CPU数量 | count | 不涉及 | ≥0 | instance_id,npu | Snt3P 300IDuo Snt9b Snt9b23 | telescope: 2.7.4.3 2.7.5.3 2.7.5.4 2.7.5.9及之后版本 |
| 2 | npu_util_rate_ai_cpu | NPU卡AI CPU使用率 | NPU卡的AI CPU使用率 | % | 不涉及 | 0~100% | instance_id,npu | ||
| 3 | npu_aicpu_avg_util_rate | NPU的AI CPU平均使用率 | 该指标描述NPU的AI CPU平均使用率 | % | 不涉及 | 0~100% | instance_id,npu | ||
| 4 | npu_aicpu_max_freq | NPU的AI CPU最大频率 | 该指标描述NPU的AI CPU最大频率 | MHz | 不涉及 | >0 | instance_id,npu | ||
| 5 | npu_aicpu_cur_freq | NPU的AI CPU频率 | 该指标描述NPU的AI CPU频率 | MHz | 不涉及 | >0 | instance_id,npu |
轻量算力节点监控指标(CTRL CPU)
| 序号 | 指标名称 | 显示名 | 说明 | 单位 | 进制 | 取值范围 | 维度 | 支持机型 | 支持CES Agent版本 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | npu_util_rate_ctrl_cpu | NPU控制CPU使用率 | 该指标描述NPU卡的控制CPU使用率 | % | 不涉及 | 0~100% | instance_id,npu | Snt3P 300IDuo Snt9b Snt9b23 | telescope: 2.7.4.3 2.7.5.3 2.7.5.4 2.7.5.9及之后版本 |
| 2 | npu_freq_ctrl_cpu | NPU的控制CPU频率 | 该指标描述NPU的控制CPU频率 | MHz | 不涉及 | >0 | instance_id,npu |
轻量算力节点监控指标(PCIE链路)
| 序号 | 指标名称 | 显示名 | 说明 | 单位 | 进制 | 取值范围 | 维度 | 支持机型 | 支持CES Agent版本 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | npu_link_cap_speed | NPU链路最大传输速度 | 该指标描述NPU设备支持的最大传输速度 | GT/s | 不涉及 | ≥0 | instance_id,npu | 310P 300IDuo Snt9b Snt9b23 | telescope: 2.7.4.3 2.7.5.3 2.7.5.4 2.7.5.9及之后版本 |
| 2 | npu_link_cap_width | NPU链路最大传输宽度 | 该指标描述NPU设备支持的最大传输宽度 | count | 不涉及 | ≥0 | instance_id,npu | ||
| 3 | npu_link_status_speed | NPU链路当前传输速度 | 该指标描述NPU设备链路的实际传输速度 | GT/s | 不涉及 | ≥0 | instance_id,npu | ||
| 4 | npu_link_status_width | NPU链路当前传输宽度 | 该指标描述NPU设备链路的实际传输宽度 | count | 不涉及 | ≥0 | instance_id,npu |
轻量算力节点监控指标(RoCE网络)
| 序号 | 指标名称 | 显示名 | 说明 | 单位 | 进制 | 取值范围 | 维度 | 支持机型 | 支持CES Agent版本 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | npu_device_network_health | NPU网络健康情况 | NPU卡的RoCE网卡的IP地址连通情况 | - | 不涉及 | 0:网络健康状态正常 非0:网络状态异常 | instance_id,npu | Snt9b Snt9b23 | telescope: 2.7.4.3 2.7.5.3 2.7.5.4 2.7.5.9及之后版本 |
| 2 | npu_network_port_link_status | NPU网口link状态 | NPU卡的对应网口link状态 | - | 不涉及 | 0:UP 1:DOWN | instance_id,npu | ||
| 3 | npu_roce_tx_rate | NPU网卡上行速率 | NPU卡内网卡的上行速率 | MB/s | 不涉及 | ≥0 | instance_id,npu | ||
| 4 | npu_roce_rx_rate | NPU网卡下行速率 | NPU卡内网卡的下行速率 | MB/s | 不涉及 | ≥0 | instance_id,npu | ||
| 5 | npu_mac_tx_mac_pause_num | MAC发送pause帧总数 | NPU卡对应MAC地址发送的pause帧总报文数 | count | 不涉及 | ≥0 | instance_id,npu | ||
| 6 | npu_mac_rx_mac_pause_num | MAC接收pause帧总数 | NPU卡对应MAC地址接收的pause帧总报文数 | count | 不涉及 | ≥0 | instance_id,npu | ||
| 7 | npu_mac_tx_pfc_pkt_num | MAC发送pfc帧总数 | NPU卡对应MAC地址发送的PFC帧总报文数 | count | 不涉及 | ≥0 | instance_id,npu | ||
| 8 | npu_mac_rx_pfc_pkt_num | MAC接收pfc帧总数 | NPU卡对应MAC地址接收的PFC帧总报文数 | count | 不涉及 | ≥0 | instance_id,npu | ||
| 9 | npu_mac_tx_bad_pkt_num | MAC发送坏包总数 | NPU卡对应MAC地址发送的坏包总数 | count | 不涉及 | ≥0 | instance_id,npu | ||
| 10 | npu_mac_rx_bad_pkt_num | MAC接收坏包总数 | NPU卡对应MAC地址接收的坏包总数 | count | 不涉及 | ≥0 | instance_id,npu | ||
| 11 | npu_roce_tx_err_pkt_num | RoCE发送坏包总数 | NPU卡内RoCE网卡发送的坏包总数 | count | 不涉及 | ≥0 | instance_id,npu | ||
| 12 | npu_roce_rx_err_pkt_num | RoCE接收坏包总数 | NPU卡内RoCE网卡接收的坏包总数 | count | 不涉及 | ≥0 | instance_id,npu | ||
| 13 | npu_roce_tx_all_pkt_num | NPU RoCE发送总报文数 | 该指标描述NPU RoCE发送的总报文数 | count | 不涉及 | ≥0 | instance_id,npu | telescope: 2.7.5.9及之后版本 | |
| 14 | npu_roce_rx_all_pkt_num | NPU RoCE接收总报文数 | 该指标描述NPU RoCE接收的总报文数 | count | 不涉及 | ≥0 | instance_id,npu | ||
| 15 | npu_roce_new_pkt_rty_num | NPU RoCE的重传报文数 | 该指标描述NPU RoCE发送的重传的报文数量统计 | count | 不涉及 | ≥0 | instance_id,npu | ||
| 16 | npu_roce_out_of_order_num | NPU RoCE接收的PSN异常报文数 | 该指标描述NPU RoCE接收的PSN大于预期PSN的报文,或重复PSN报文数。乱序或丢包,会触发重传 | count | 不涉及 | ≥0 | instance_id,npu | ||
| 17 | npu_roce_rx_cnp_pkt_num | NPU RoCE接收的CNP类型报文数 | 该指标描述NPU RoCE接收的CNP类型报文数 | count | 不涉及 | ≥0 | instance_id,npu | ||
| 18 | npu_roce_tx_cnp_pkt_num | NPU RoCE发送的CNP类型报文数 | 该指标描述NPU RoCE发送的CNP类型报文数 | count | 不涉及 | ≥0 | instance_id,npu |
轻量算力节点监控指标(RoCE光模块)
| 序号 | 指标名称 | 显示名 | 说明 | 单位 | 进制 | 取值范围 | 维度 | 支持机型 | 支持CES Agent版本 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | npu_opt_temperature | NPU光模块壳温 | 该指标描述NPU光模块壳温 | °C | 不涉及 | 自然数 | instance_id,npu | Snt9b Snt9b23 | telescope: 2.7.4.3 2.7.5.3 2.7.5.4 2.7.5.9及之后版本 |
| 2 | npu_opt_temperature_high_thres | NPU光模块壳温上限 | 该指标描述NPU光模块壳温上限 | °C | 不涉及 | 自然数 | instance_id,npu | ||
| 3 | npu_opt_temperature_low_thres | NPU光模块壳温下限 | 该指标描述NPU光模块壳温下限 | °C | 不涉及 | 自然数 | instance_id,npu | ||
| 4 | npu_opt_voltage | NPU光模块供电电压 | 该指标描述NPU光模块供电电压 | mV | 不涉及 | ≥0 | instance_id,npu | ||
| 5 | npu_opt_voltage_high_thres | NPU光模块供电电压上限 | 该指标描述NPU光模块供电电压上限 | mV | 不涉及 | ≥0 | instance_id,npu | ||
| 6 | npu_opt_voltage_low_thres | NPU光模块供电电压下限 | 该指标描述NPU光模块供电电压下限 | mV | 不涉及 | ≥0 | instance_id,npu | ||
| 7 | npu_opt_tx_power_lane0 | NPU光模块通道0发送功率 | 该指标描述NPU光模块通道0发送功率 | mW | 不涉及 | ≥0 | instance_id,npu | ||
| 8 | npu_opt_tx_power_lane1 | NPU光模块通道1发送功率 | 该指标描述NPU光模块通道1发送功率 | mW | 不涉及 | ≥0 | instance_id,npu | ||
| 9 | npu_opt_tx_power_lane2 | NPU光模块通道2发送功率 | 该指标描述NPU光模块通道2发送功率 | mW | 不涉及 | ≥0 | instance_id,npu | ||
| 10 | npu_opt_tx_power_lane3 | NPU光模块通道3发送功率 | 该指标描述NPU光模块通道3发送功率 | mW | 不涉及 | ≥0 | instance_id,npu | ||
| 11 | npu_opt_rx_power_lane0 | NPU光模块通道0接收功率 | 该指标描述NPU光模块通道0接收功率 | mW | 不涉及 | ≥0 | instance_id,npu | ||
| 12 | npu_opt_rx_power_lane1 | NPU光模块通道1接收功率 | 该指标描述NPU光模块通道1接收功率 | mW | 不涉及 | ≥0 | instance_id,npu | ||
| 13 | npu_opt_rx_power_lane2 | NPU光模块通道2接收功率 | 该指标描述NPU光模块通道2接收功率 | mW | 不涉及 | ≥0 | instance_id,npu | ||
| 14 | npu_opt_rx_power_lane3 | NPU光模块通道3接收功率 | 该指标描述NPU光模块通道3接收功率 | mW | 不涉及 | ≥0 | instance_id,npu | ||
| 15 | npu_opt_tx_bias_lane0 | NPU光模块通道0发射偏置电流 | 该指标描述NPU光模块通道0发射偏置电流 | mA | 不涉及 | ≥0 | instance_id,npu | ||
| 16 | npu_opt_tx_bias_lane1 | NPU光模块通道1发射偏置电流 | 该指标描述NPU光模块通道1发射偏置电流 | mA | 不涉及 | ≥0 | instance_id,npu | ||
| 17 | npu_opt_tx_bias_lane2 | NPU光模块通道2发射偏置电流 | 该指标描述NPU光模块通道2发射偏置电流 | mA | 不涉及 | ≥0 | instance_id,npu | ||
| 18 | npu_opt_tx_bias_lane3 | NPU光模块通道3发射偏置电流 | 该指标描述NPU光模块通道3发射偏置电流 | mA | 不涉及 | ≥0 | instance_id,npu | ||
| 19 | npu_opt_tx_los | NPU光模块TX Los | 该指标描述NPU光模块TX Los flag | count | 不涉及 | ≥0 | instance_id,npu | ||
| 20 | npu_opt_rx_los | NPU光模块RX Los | 该指标描述NPU光模块RX Los flag | count | 不涉及 | ≥0 | instance_id,npu | ||
| 21 | npu_opt_media_snr_lane0 | NPU光模块通道0光侧信噪比 | 该指标描述NPU光模块通道0的media侧(光侧)的信噪比 | dB | 不涉及 | ≥0 | instance_id,npu | telescope: 2.7.5.9及之后版本 | |
| 22 | npu_opt_media_snr_lane1 | NPU光模块通道1光侧信噪比 | 该指标描述NPU光模块通道1的media侧(光侧)的信噪比 | dB | 不涉及 | ≥0 | instance_id,npu | ||
| 23 | npu_opt_media_snr_lane2 | NPU光模块通道2光侧信噪比 | 该指标描述NPU光模块通道2的media侧(光侧)的信噪比 | dB | 不涉及 | ≥0 | instance_id,npu | ||
| 24 | npu_opt_media_snr_lane3 | NPU光模块通道3光侧信噪比 | 该指标描述NPU光模块通道3的media侧(光侧)的信噪比 | dB | 不涉及 | ≥0 | instance_id,npu |
在轻量算力节点中执行如下命令查询vendor name是否为HUAWEI,vendor name非HUAWEI时,不支持上报RoCE光模块的npu_opt_host_snr_lanex相关指标。
#查询NPU卡ID npu-smi info -l

#基于NPU卡ID查询vendor name hccn_tool -i <NPU卡ID> -optical -g

轻量算力节点监控指标(HCCS Serdes SNR)
| 序号 | 指标名称 | 显示名 | 说明 | 单位 | 进制 | 取值范围 | 维度 | 支持机型 | 支持CES Agent版本 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | npu_macro1_serdes_lane0_snr | NPU Macro1 Serdes Lane0的信噪比 | 该指标描述NPU Macro1 Serdes Lane0的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | Snt9b Snt9b23 | telescope: 2.7.5.9及之后版本 |
| 2 | npu_macro1_serdes_lane1_snr | NPU Macro1 Serdes Lane1的信噪比 | 该指标描述NPU Macro1 Serdes Lane1的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 3 | npu_macro1_serdes_lane2_snr | NPU Macro1 Serdes Lane2的信噪比 | 该指标描述NPU Macro1 Serdes Lane2的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 4 | npu_macro1_serdes_lane3_snr | NPU Macro1 Serdes Lane3的信噪比 | 该指标描述NPU Macro1 Serdes Lane3的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 5 | npu_macro2_serdes_lane0_snr | NPU Macro2 Serdes Lane0的信噪比 | 该指标描述NPU Macro2 Serdes Lane0的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 6 | npu_macro2_serdes_lane1_snr | NPU Macro2 Serdes Lane1的信噪比 | 该指标描述NPU Macro2 Serdes Lane1的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 7 | npu_macro2_serdes_lane2_snr | NPU Macro2 Serdes Lane2的信噪比 | 该指标描述NPU Macro2 Serdes Lane2的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 8 | npu_macro2_serdes_lane3_snr | NPU Macro2 Serdes Lane3的信噪比 | 该指标描述NPU Macro2 Serdes Lane3的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 9 | npu_macro3_serdes_lane0_snr | NPU Macro3 Serdes Lane0的信噪比 | 该指标描述NPU Macro3 Serdes Lane0的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 10 | npu_macro3_serdes_lane1_snr | NPU Macro3 Serdes Lane1的信噪比 | 该指标描述NPU Macro3 Serdes Lane1的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 11 | npu_macro3_serdes_lane2_snr | NPU Macro3 Serdes Lane2的信噪比 | 该指标描述NPU Macro3 Serdes Lane2的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 12 | npu_macro3_serdes_lane3_snr | NPU Macro3 Serdes Lane3的信噪比 | 该指标描述NPU Macro3 Serdes Lane3的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 13 | npu_macro4_serdes_lane0_snr | NPU Macro4 Serdes Lane0的信噪比 | 该指标描述NPU Macro4 Serdes Lane0的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 14 | npu_macro4_serdes_lane1_snr | NPU Macro4 Serdes Lane1的信噪比 | 该指标描述NPU Macro4 Serdes Lane1的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 15 | npu_macro4_serdes_lane2_snr | NPU Macro4 Serdes Lane2的信噪比 | 该指标描述NPU Macro4 Serdes Lane2的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 16 | npu_macro4_serdes_lane3_snr | NPU Macro4 Serdes Lane3的信噪比 | 该指标描述NPU Macro4 Serdes Lane3的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 17 | npu_macro5_serdes_lane0_snr | NPU Macro5 Serdes Lane0的信噪比 | 该指标描述NPU Macro5 Serdes Lane0的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 18 | npu_macro5_serdes_lane1_snr | NPU Macro5 Serdes Lane1的信噪比 | 该指标描述NPU Macro5 Serdes Lane1的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 19 | npu_macro5_serdes_lane2_snr | NPU Macro5 Serdes Lane2的信噪比 | 该指标描述NPU Macro5 Serdes Lane2的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 20 | npu_macro5_serdes_lane3_snr | NPU Macro5 Serdes Lane3的信噪比 | 该指标描述NPU Macro5 Serdes Lane3的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 21 | npu_macro6_serdes_lane0_snr | NPU Macro6 Serdes Lane0的信噪比 | 该指标描述NPU Macro6 Serdes Lane0的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 22 | npu_macro6_serdes_lane1_snr | NPU Macro6 Serdes Lane1的信噪比 | 该指标描述NPU Macro6 Serdes Lane1的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 23 | npu_macro6_serdes_lane2_snr | NPU Macro6 Serdes Lane2的信噪比 | 该指标描述NPU Macro6 Serdes Lane2的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 24 | npu_macro6_serdes_lane3_snr | NPU Macro6 Serdes Lane3的信噪比 | 该指标描述NPU Macro6 Serdes Lane3的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 25 | npu_macro7_serdes_lane0_snr | NPU Macro7 Serdes Lane0的信噪比 | 该指标描述NPU Macro7 Serdes Lane0的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 26 | npu_macro7_serdes_lane1_snr | NPU Macro7 Serdes Lane1的信噪比 | 该指标描述NPU Macro7 Serdes Lane1的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 27 | npu_macro7_serdes_lane2_snr | NPU Macro7 Serdes Lane2的信噪比 | 该指标描述NPU Macro7 Serdes Lane2的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu | ||
| 28 | npu_macro7_serdes_lane3_snr | NPU Macro7 Serdes Lane3的信噪比 | 该指标描述NPU Macro7 Serdes Lane3的信噪比 | dB | 不涉及 | 自然数 | instance_id,npu |




