

Lite Cluster资源开通
ModelArts Lite Cluster是华为云ModelArts平台中的一种专属资源池,面向k8s资源型用户,提供托管式k8s集群,并预装主流AI开发插件以及自研的加速插件,以云原生方式直接向用户提供AI Native的资源、任务等能力。用户可以直接操作资源池中的节点和k8s集群,适合需要直接使用云原生资源的场景。
ModelArts Lite Cluster与ModelArts Standard资源池区别:
- ModelArts Lite资源池:用户可以直接操作节点和k8s集群,适合需要直接使用云原生资源的场景。
- ModelArts Standard资源池:提供训练、推理、开发环境等上层能力,适合一站式开发需求。
本章节主要介绍开通Lite Cluster资源池的详细操作。
计费影响
- 在开通Lite Cluster资源后,会产生计算资源的计费。Lite Cluster资源池仅支持包年/包月计费模式,具体内容如表1所示。
表1 计费项 计费项
计费项说明
适用的计费模式
计费公式
计算资源
专属资源池
使用计算资源的用量。
具体费用可参见ModelArts价格详情。
包年/包月
规格单价 * 计算节点个数 * 购买时长
- 购买Cluster资源池时,需要选择CCE集群,具体费用请参考CCE计费详情。
集群资源开通流程
开通集群资源过程中用户侧需要完成的任务流程如下图所示。

|
任务 |
说明 |
|---|---|
|
在开通资源前,请确保完成所有相关准备工作,包括申请开通所需的规格和进行权限配置。 |
|
|
在ModelArts控制台上购买Cluster资源。 |
Step2 基础权限开通
基础权限开通需要登录管理员账号,为子用户账号开通使用资源池所需的基础权限。
- 登录统一身份认证服务管理控制台。
- 单击目录左侧“用户组”,然后在页面右上角单击“创建用户组”。
- 填写“用户组名称”并单击“确定”,完成用户组创建。
用户组名称只能包含中文、大小写字母、数字、空格或特殊字符(-_)。
- 在操作列单击“用户组管理”,将需要配置权限的用户加入用户组中。
- 单击用户组名称,进入用户组详情页。
- 在权限管理页签下,单击“授权”。
图2 “配置权限”
- 在搜索栏输入“ModelArtsFullAccessPolicy”,并勾选“ModelArtsFullAccessPolicy”。
图3 ModelArtsFullAccessPolicy

以相同的方式,依次添加如下权限:
- ModelArts FullAccess
- CTS Administrator
- CCE Administrator
- BMS FullAccess
- IMS FullAccess
- DEW KeypairReadOnlyAccess
- VPC FullAccess
- ECS FullAccess
- SFS Turbo FullAccess
- OBS Administrator
- AOM FullAccess
- TMS FullAccess
- BSS Administrator
- 单击“下一步”,授权范围方案选择“所有资源”。
- 单击“确认”,完成基础权限开通。
设置权限完成后,单击用户组名称,进入用户组详情页,在授权记录页签下可以查看到已授予的权限。
Step3 在ModelArts上创建委托授权
- 新建委托
第一次使用ModelArts时需要创建委托授权,授权允许ModelArts代表用户去访问其他云服务。
进入到ModelArts管理控制台的“权限管理”页面,单击“添加授权”,根据提示进行操作,详情请见添加授权。
- 更新委托
如果之前给ModelArts创过委托授权,此处可以更新授权。
- 进入到ModelArts管理控制台的“资源管理>轻量算力集群(Lite Cluster) ”页面,查看是否存在授权缺失的提示。
图4 轻量算力集群(Lite Cluster)权限缺失提示

- 如果有授权缺失,根据提示,单击“此处”更新委托。根据提示选择“追加至已有授权”,单击“确定”,系统会提示权限更新成功。
图5 追加授权

- 进入到ModelArts管理控制台的“资源管理>轻量算力集群(Lite Cluster) ”页面,查看是否存在授权缺失的提示。
Step4 申请扩大资源配额
集群所需的ECS实例数、内存大小、CPU核数和EVS硬盘大小等资源会超出华为云默认提供的资源配额,因此需要申请扩大配额。具体的配额方案请通过工单系统提交申请来联系客户经理获取。
配额需大于要开通的资源,且在购买开通前完成配额提升,否则会导致资源开通失败。
由于AI机型规格相对较大,资源池所需的ECS实例数、内存大小、CPU核数和EVS硬盘大小很可能会超出华为云默认提供的资源配额,因此需要申请扩大配额。请先联系客户经理确认资源配额提升具体方案,再参考本章节申请扩大配额。
- 登录华为云管理控制台。
- 在顶部导航栏单击“资源 > 我的配额”,进入服务配额页面。
图6 我的配额

- 在服务配额页面,单击右上角的“申请扩大配额”,填写申请材料后提交工单。
申请扩大配额主要是申请弹性云服务器ECS实例数、核心数(CPU核数)、RAM容量(内存大小)和云硬盘EVS磁盘容量这4个资源配额。具体的配额数量请先联系客户经理获取。
图7 ECS资源类型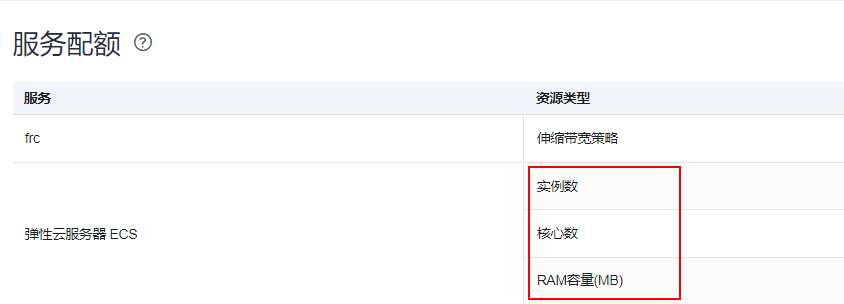 图8 云硬盘资源类型
图8 云硬盘资源类型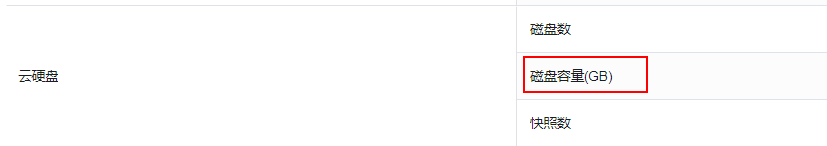
购买Lite Cluster资源池
- 登录ModelArts管理控制台,在左侧菜单栏中选择,进入“轻量算力集群 (Lite Cluster)”页面。
- 在“轻量算力集群 (Lite Cluster)”页面,单击“购买轻量算力集群”,进入购买轻量算力集群界面,参见下表填写参数。
表3 Lite Cluster资源池的参数说明 参数名称
子参数
说明
计费模式
包年/包月
包年/包月是预付费模式,按订单的购买周期计费,适用于可预估资源使用周期的场景,价格比按需计费模式更优惠。
Lite Cluster暂时只支持包年/包月计费模式。
集群规格
集群名称
系统默认提供一个名称,可以手动修改。
只能以小写字母开头,由小写字母、数字、中划线(-)组成,不能以中划线结尾。
选择CCE集群
在下拉列表中选择用户账户下已有的CCE集群。如果没有集群,单击右侧的“创建集群”,先去创建集群。集群配套版本请参考不同机型对应的软件配套版本。
创建Cluster资源池时,请确保CCE集群为“运行中”状态。
当前仅支持CCE集群1.23&1.25&1.28&1.31版本。CCE 1.28集群版本支持通过控制台、API方式创建,CCE 1.23和CCE 1.25版本支持通过API方式创建,CCE 1.31集群版本支持通过控制台、API方式创建。不同版本的CCE集群创建方式请见Kubernetes版本策略。
如果您已有CCE集群,但CCE集群版本低于1.23,则可参考升级集群的流程和方法,建议将集群升级至1.28版本。
节点池
节点池名称
为帮助您更好地管理Kubernetes集群内的节点,ModelArts支持通过节点池来管理节点。
新建节点池的名称,可自定义。
创建资源池后,暂不支持资源池中的存量节点池修改名称。
节点类型
- 普通节点:单一物理主机或虚拟主机,提供基础的独立计算、存储和网络资源。
- 超节点:融合架构节点,提供大规模计算资源池,支持灵活调配和高密度部署。超节点专门用于支持大规模的模型推理任务。这些服务器通常配备有多个计算卡(如昇腾NPU),能够提供强大的计算能力,以满足高负载的推理需求。超节点资源仅支持西南-贵阳一、华北三、华北-乌兰察布一和华东二区域。
- 整柜节点:整台物理机独占资源,提供极高隔离性、性能和资源确定性。
资源类型
可以根据需要选择“裸金属服务器”或“弹性云服务器”。
- 裸金属服务器:是一款兼具弹性云服务器和物理机性能的计算类服务器,为您和您的企业提供专属的云上物理服务器。
- 弹性云服务器:是一种可随时自助获取、可弹性伸缩的云服务器,可帮助您打造可靠、安全、灵活、高效的应用环境,确保服务持久稳定运行,提升运维效率。
CPU架构
CPU架构指的是中央处理器(CPU)的指令集和设计规范。支持X86和ARM64两种不同的CPU架构,同时支持X86和ARM64异构调度。请根据实际需要选择。
- X86:适用于大多数通用计算场景,支持广泛的软件生态。
- ARM64:适用于特定优化场景,如移动应用、嵌入式系统等,具有低功耗优势。
实例规格类型
支持CPU、GPU、Ascend三种芯片规格资源,根据实际需要选择。
- CPU:通用计算架构,适合通用任务,计算性能较低,适用于轻量级适合通用任务,计算性能较低。
- GPU:并行计算架构,适合并行任务,计算性能高,支持多卡分布式训练,适用于深度学习训练、图像处理等场景。
- Ascend:专用 AI 架构,适合 AI 任务,计算性能极高,支持多节点分布式部署,适用于AI 模型训练、推理加速等场景。
实例规格
选择需要使用的规格。平台分配的资源规格包含了一定的系统损耗,实际可用的资源量小于规格标称的资源。实际可用的资源量可在资源池创建成功后,在详情页的“节点”页签中查看。
可用区
根据实际情况选择“随机可用区”或“指定可用区”。可用区是在同一区域下,电力、网络隔离的物理区域。可用区之间内网互通,不同可用区之间物理隔离。
- 随机可用区:系统自动分配可用区。
- 指定可用区:指定资源池实例在哪个可用区域。考虑系统容灾时,推荐指定实例在同一个可用区。可设置可用区的实例数。
实例数
选择Lite Cluster资源池的实例个数(即节点个数),数量越多,计算性能越强。
当“可用区”选择“指定可用区”时,实例数量会根据可用区的数据自动计算,此处无需再次设置。
单次创建时,实例数建议不大于30,否则可能触发限流导致创建失败。
部分区域的部分规格支持整柜购买,此时实例数会显示为“数量*整柜”,购买的实例总数为两者的乘积。整柜购买可实现不同任务间的物理隔离,避免通信冲突,在任务规模增大的同时保证计算性能线性度不下降。整柜下的实例生命周期需保持一致,需要一起创建、一起删除。
超节点规格,即Snt9b23类型实例规格,支持自定义步长购买,此时实例数会显示为“数量*步长”,购买的实例总数为两者的乘积。步长为每次调整保障配额时的最小单位,在节点绑定场景下每个步长内的节点将作为一个整体,且属于同一批次。
存储配置
支持设置如下存储配置。
- 系统盘:显示系统盘的磁盘类型和大小。系统盘的磁盘类型支持本地盘和云硬盘(包括通用SSD、高IO和超高IO)。部分规格的系统盘仅支持本地盘。
- 容器盘:显示容器盘的存储类型、大小和数量。部分规格的容器盘存储类型支持手动设置,可以选择本地盘或云硬盘。
- 容器盘高级配置:支持设置“指定磁盘空间”、“容器引擎空间大小”、写入模式。
- 容器引擎空间大小:默认容器引擎空间大小为50GiB。可指定容器引擎空间大小和不限制空间大小。当选择“指定大小”时,默认值与最小值均为50GiB,不同规格的最大值不同,数值有效范围请参考界面提示。
- 写入模式:部分规格支持设置容器盘的写入模式为线性或条带化。线性逻辑卷是将一个或多个物理卷整合为一个逻辑卷,实际写入数据时会先往一个基本物理卷上写入,当存储空间占满时再往另一个基本物理卷写入。条带化是指创建逻辑卷时指定条带化,当实际写入数据时会将连续的数据分成大小相同的块,然后依次存储在多个物理卷上,实现数据的并发读写从而提高读写性能。条带化模式的存储池不支持扩容。
- 数据盘:部分规格支持“添加普通数据盘”,挂载多个数据盘到资源池中。支持设置数据盘的“磁盘类型”、“大小”和“数量”。
不同规格有不同的磁盘数量限制,比如:300I Duo节点仅支持挂载4个数据盘,具体请以界面提示为准。
- 数据盘高级配置:部分规格支持在数据盘高级配置参数中设置数据盘的挂载方式,具体如下:
- 默认:仅是将云硬盘挂载到资源池上,未对挂载的云硬盘做任何处理,比如分区等。
- 挂载到指定目录:支持设置“数据盘挂载到的指定路径”和“写入模式”,包括线性和条带化。
- 以本地持久卷挂载:支持“持久卷写入模式”设置,包括线性和条带化,此处设置的是所有数据盘的写入模式。
- 以临时存储卷挂载:支持“临时卷写入模式”设置,包括线性和条带化,此处设置的是所有数据盘的写入模式。
网络配置
勾选“网络配置”后,支持设置虚拟私有云为CCE集群网络。
- 虚拟私有云:默认为CCE集群所在VPC网络,不可修改。
- 节点子网:选择同一VPC网络下的子网作为节点子网,新创建的节点将会使用该子网资源。
- 关联安全组:用于指定节点池创建出来的节点使用的安全组。最多选择4个安全组。节点安全组需要放通一些端口以保障节点通信。如果不关联安全组将会使用集群中默认的节点安全组规则。
环境配置
勾选“环境配置”后,支持设置如下参数:
- 镜像配置:可以指定实例的操作系统。
- 预置镜像:ModelArts提供,支持多种操作系统,并且内置了AI场景相关驱动和软件,为用户提供了一个完整的AI开发环境,方便用户直接进行开发和训练,而无需额外配置。
- 私有镜像:非ModelArts官方提供,请您在测试环境中自行完成充分的测试验证,再应用于生产环境。请确保您的镜像与CCE集群目标运行环境(如操作系统类型、内核版本、容器运行时、驱动等)兼容性、稳定性和安全性,不兼容的镜像可能导致驱动安装失败、AI业务部署失败或运行异常。
- 容器引擎:容器引擎是Kubernetes最重要的组件之一,负责管理镜像和容器的生命周期。Kubelet通过Container Runtime Interface (CRI) 与容器引擎交互,以管理镜像和容器。此处支持选择Docker和Containerd。Containerd和Docker的详细差异对比请见容器引擎。
您可以在创建资源池时选择容器引擎,也可在资源池创建完成后,在扩缩容界面修改。
如果CCE集群版本低于1.23,仅支持选择Docker作为容器引擎。如果CCE集群版本大于等于1.27,仅支持选择Containerd作为容器引擎。其余CCE集群版本,支持选择Containerd或Docker作为容器引擎。
节点池标签管理
单击
 添加节点池标签。
添加节点池标签。- 资源标签:通过为资源添加标签,可以对资源进行自定义标记,实现资源分类。也可在资源池创建完成后,在资源池详情页的“标签”页面修改。
- K8S标签:设置附加到Kubernetes对象(比如Pod)上的键值对。最多可以添加20条标签。使用该标签可区分不同节点,可结合工作负载的亲和能力实现容器Pod调度到指定节点的功能。
- 污点:默认为空。支持给节点加污点来设置反亲和性,每个节点最多配置20条污点。
新增节点池
当您需要更多节点池时,可单击“新增节点池”创建多个节点池。根据业务设置各个节点池配置。
插件配置
选择插件
ModelArts提供多种类型的插件,通过添加插件选择性扩展资源池功能,以满足业务需求。
单击“选择插件”,在弹框中勾选需要配置的插件,单击“确定”。
单击各插件的“查看详情”,可查看对应插件的功能介绍、版本更新特性等具体信息。
默认添加如下插件:
- 节点故障检测(ModelArts Node Agent):ModelArts节点故障检测是一款监控集群节点异常事件的插件,以及对接第三方监控平台功能的组件。它是一个在每个节点上运行的守护程序,可从不同的守护进程中搜集节点问题。
- 指标监控插件(ModelArts Metrics Collector):默认内置插件,以节点守护程序运行,可采集节点及作业各类监控指标,并上报到AOM。
- AI套件-Ascend NPU(Modelarts Device Plugin):支持容器里使用huawei NPU设备的管理插件。
仅实例规格类型选择“Ascend”时自动安装。
- Volcano调度器(Volcano Scheduler):Volcano 是一个基于 Kubernetes 的批处理平台,提供了机器学习、深度学习、生物信息学、基因组学及其他大数据应用所需要而 Kubernetes 当下缺失的一系列特性。
资源调度与切分
GPU驱动/NPU驱动
打开“自定义驱动”开关,显示此参数,选择GPU/NPU驱动。如果规格类型为GPU则显示“GPU驱动”,如果规格类型为Ascend则显示“NPU驱动”。
gpu-driver配套版本请参考不同机型对应的软件配套版本。
高级配置
集群描述
自定义集群描述信息。
自定义节点前缀
开启后,可为节点名称添加前缀。
- 添加前缀后,节点名称由前缀+随机数组成。
- 输入长度范围为1到64个字符。
- 前缀必须以小写字母开头,并由小写字母和数字组成,以“-”分隔。例如:node-com。
标签
单击“添加新标签”,可以为Lite资源池配置标签信息,通过标签实现资源的分组管理。此处的标签信息可以同源标签管理服务TMS中预定义的标签信息。也可以在创建完成后的Lite资源池详情页面中通过“标签”页签设置标签信息。
管理
登录凭证
集群登录方式,可以设置密码登录,也可以设置密钥对登录。
- 密码登录:默认用户名为root,用户自己设置密码。
- 密钥对(KeyPair)登录:可以选择已有的密钥对,或者单击右侧的“创建密钥对”,先去创建一个密钥对。
购买时长
-
选择购买时长。只有选择“包年/包月”计费模式时才需填写。
自动续费默认关闭。勾选自动续费后,资源池到期后,会自动续期。自动续费时系统从可用余额扣款,详情请见自动续费。如果购买时是按月购买,则按照1个月周期自动续费。如果购买时是按年购买,则自动续费周期为1年。
- 单击“立即购买”确认规格。产品规格和协议许可确认无误后,单击“提交”,即可创建Lite资源池。
- 当资源池创建成功后,资源池的状态会变成“运行中”,当“节点个数”中的“可用节点”和“总数”值大于0时,资源池才能下发任务。
- 可以将鼠标放在“创建中”字样上,查看当前创建过程详情。如果单击查看详情,可跳转到“操作记录”中。
- 可以在Lite资源池列表右上角的“操作记录”中查看资源池的任务记录。
图9 操作记录
 图10 查看操作记录
图10 查看操作记录
当资源池创建成功后,资源池的状态会变成“运行中”。单击集群资源名称,进入资源详情页。确认购买的规格是否正确。图11 查看资源详情




