- 最新动态
- 功能总览
- 服务公告
- 产品介绍
- 计费说明
- 快速入门
-
ModelArts用户指南(Standard)
- ModelArts Standard使用流程
- ModelArts Standard准备工作
- ModelArts Standard资源管理
- 使用自动学习实现零代码AI开发
- 使用Workflow实现低代码AI开发
- 使用Notebook进行AI开发调试
- 数据准备与处理
- 使用ModelArts Standard训练模型
- 使用ModelArts Standard部署模型并推理预测
- 制作自定义镜像用于ModelArts Standard
- ModelArts Standard资源监控
- 使用CTS审计ModelArts服务
- ModelArts用户指南(Studio)
- ModelArts用户指南(Lite Server)
- ModelArts用户指南(Lite Cluster)
- ModelArts用户指南(AI Gallery)
-
最佳实践
- ModelArts最佳实践案例列表
- 昇腾能力应用地图
- DeepSeek系列模型推理
-
LLM大语言模型训练推理
- 在ModelArts Studio基于Qwen2-7B模型实现新闻自动分类
- 主流开源大模型基于Lite Server适配Ascend-vLLM PyTorch NPU推理指导(6.3.912)
- 主流开源大模型基于Lite Server适配ModelLink PyTorch NPU训练指导(6.3.912)
- 主流开源大模型基于Lite Cluster适配ModelLink PyTorch NPU训练指导(6.3.912)
- 主流开源大模型基于Standard+OBS适配ModelLink PyTorch NPU训练指导(6.3.912)
- 主流开源大模型基于Standard+OBS+SFS适配ModelLink PyTorch NPU训练指导(6.3.912)
- 主流开源大模型基于Lite Server适配LlamaFactory PyTorch NPU训练指导(6.3.912)
- 主流开源大模型基于Lite Server适配PyTorch NPU推理指导(6.3.911)
- 主流开源大模型基于Standard适配PyTorch NPU推理指导(6.3.911)
- 主流开源大模型基于Lite Cluster适配PyTorch NPU推理指导(6.3.911)
- 主流开源大模型基于Lite Server适配ModelLink PyTorch NPU训练指导(6.3.911)
- 主流开源大模型基于Lite Server适配LlamaFactory PyTorch NPU训练指导(6.3.911)
- 主流开源大模型基于Standard+OBS适配ModelLink PyTorch NPU训练指导(6.3.911)
- 主流开源大模型基于Standard+OBS+SFS适配ModelLink PyTorch NPU训练指导(6.3.911)
- 主流开源大模型基于Lite Cluster适配ModelLink PyTorch NPU训练指导(6.3.911)
- 主流开源大模型基于Lite Server适配PyTorch NPU推理指导(6.3.910)
- 主流开源大模型基于Standard适配PyTorch NPU推理指导(6.3.910)
- 主流开源大模型基于Lite Cluster适配PyTorch NPU推理指导(6.3.910)
- 主流开源大模型基于Lite Server适配ModelLink PyTorch NPU训练指导(6.3.910)
- 主流开源大模型基于Lite Server适配LlamaFactory PyTorch NPU训练指导(6.3.910)
- 主流开源大模型基于Standard+OBS适配ModelLink PyTorch NPU训练指导(6.3.910)
- 主流开源大模型基于Standard+OBS+SFS适配ModelLink PyTorch NPU训练指导(6.3.910)
- 主流开源大模型基于Lite Cluster适配ModelLink PyTorch NPU训练指导(6.3.910)
- 主流开源大模型基于Lite Server适配PyTorch NPU推理指导(6.3.909)
- 主流开源大模型基于Standard适配PyTorch NPU推理指导(6.3.909)
- 主流开源大模型基于Lite Cluster适配PyTorch NPU推理指导(6.3.909)
- 主流开源大模型基于Lite Server适配ModelLink PyTorch NPU训练指导(6.3.909)
- 主流开源大模型基于Lite Server适配LlamaFactory PyTorch NPU训练指导(6.3.909)
- 主流开源大模型基于Standard+OBS适配ModelLink PyTorch NPU训练指导(6.3.909)
- 主流开源大模型基于Standard+OBS+SFS适配ModelLink PyTorch NPU训练指导(6.3.909)
- 主流开源大模型基于Lite Cluster适配ModelLink PyTorch NPU训练指导(6.3.909)
- 主流开源大模型基于Lite Server适配PyTorch NPU推理指导(6.3.908)
- 主流开源大模型基于Standard适配PyTorch NPU推理指导(6.3.908)
- 主流开源大模型基于Lite Server适配ModelLink PyTorch NPU训练指导(6.3.908)
- 主流开源大模型基于Lite Server适配LlamaFactory PyTorch NPU训练指导(6.3.908)
- 主流开源大模型基于Standard+OBS适配ModelLink PyTorch NPU训练指导(6.3.908)
- 主流开源大模型基于Standard+OBS+SFS适配ModelLink PyTorch NPU训练指导(6.3.908)
- 主流开源大模型基于Lite Server适配ModelLink PyTorch NPU训练指导(6.3.907)
- 主流开源大模型基于Lite Server适配LlamaFactory PyTorch NPU训练指导(6.3.907)
- 主流开源大模型基于Lite Server适配PyTorch NPU推理指导(6.3.907)
- 主流开源大模型基于Standard+OBS适配PyTorch NPU训练指导(6.3.907)
- 主流开源大模型基于Standard+OBS+SFS适配PyTorch NPU训练指导(6.3.907)
- 主流开源大模型基于Standard适配PyTorch NPU推理指导(6.3.907)
- 主流开源大模型基于Lite Server适配PyTorch NPU训练指导(6.3.906)
- 主流开源大模型基于Lite Server适配PyTorch NPU推理指导(6.3.906)
- 主流开源大模型基于Standard适配PyTorch NPU训练指导(6.3.906)
- 主流开源大模型基于Standard适配PyTorch NPU推理指导(6.3.906)
- 主流开源大模型基于Lite Server适配PyTorch NPU训练指导(6.3.905)
- 主流开源大模型基于LIte Server适配PyTorch NPU推理指导(6.3.905)
- 主流开源大模型基于Standard适配PyTorch NPU训练指导(6.3.905)
- 主流开源大模型基于Standard适配PyTorch NPU推理指导(6.3.905)
-
MLLM多模态模型训练推理
- Qwen-VL基于Standard+OBS+SFS适配PyTorch NPU训练指导(6.3.912)
- Qwen-VL模型基于Standard+OBS适配PyTorch NPU训练指导(6.3.912)
- Qwen-VL基于Lite Server适配PyTorch NPU的Finetune训练指导(6.3.912)
- Qwen-VL基于Lite Server适配PyTorch NPU的推理指导(6.3.909)
- MiniCPM-V2.6基于Lite Server适配PyTorch NPU训练指导(6.3.912)
- MiniCPM-V2.0推理及LoRA微调基于Lite Server适配PyTorch NPU指导(6.3.910)
- InternVL2基于LIte Server适配PyTorch NPU训练指导(6.3.912)
- LLaVA-NeXT基于Lite Server适配PyTorch NPU训练微调指导(6.3.912)
- LLaVA模型基于Lite Server适配PyTorch NPU预训练指导(6.3.912)
- LLaVA模型基于Lite Server适配PyTorch NPU推理指导(6.3.906)
- Llama 3.2-Vision基于Lite Server适配Pytorch NPU训练微调指导(6.3.912)
- LLaMA-VID基于Lite Server适配PyTorch NPU推理指导(6.3.910)
- moondream2基于Lite Server适配PyTorch NPU推理指导
-
文生图模型训练推理
- FlUX.1基于Lite Server适配PyTorch NPU推理指导(6.3.912)
- FLUX.1基于DevSever适配PyTorch NPU Finetune&Lora训练指导(6.3.911)
- Hunyuan-DiT基于Lite Server部署适配PyTorch NPU推理指导(6.3.909)
- SD3.5基于Lite Server适配PyTorch NPU的推理指导(6.3.912)
- SD3基于Lite Server适配PyTorch NPU的训练指导(6.3.912)
- SD3 Diffusers框架基于Lite Server适配PyTorch NPU推理指导(6.3.912)
- SD1.5&SDXL Diffusers框架基于Lite Server适配PyTorch NPU训练指导(6.3.908)
- SD1.5&SDXL Kohya框架基于DevServer适配PyTorch NPU训练指导(6.3.908)
- SDXL基于Standard适配PyTorch NPU的LoRA训练指导(6.3.908)
- SD3 Diffusers框架基于Lite Server适配PyTorch NPU推理指导(6.3.907)
- SDXL&SD1.5 ComfyUI基于Lite Cluster适配NPU推理指导(6.3.906)
- SDXL基于Standard适配PyTorch NPU的Finetune训练指导(6.3.905)
- SDXL基于Lite Server适配PyTorch NPU的Finetune训练指导(6.3.905)
- SDXL基于Lite Server适配PyTorch NPU的LoRA训练指导(6.3.905)
- SD1.5基于Lite Server适配PyTorch NPU Finetune训练指导(6.3.904)
- Open-Clip基于Lite Server适配PyTorch NPU训练指导
- AIGC工具tailor使用指导
- 文生视频模型训练推理
- 数字人模型训练推理
- 内容审核模型训练推理
- GPU业务迁移至昇腾训练推理
- Standard权限管理
- Standard自动学习
- Standard开发环境
- Standard模型训练
- Standard推理部署
- 历史待下线案例
-
API参考
- 使用前必读
- API概览
- 如何调用API
-
Workflow工作流管理
- 获取Workflow工作流列表
- 新建Workflow工作流
- 删除Workflow工作流
- 查询Workflow工作流
- 修改Workflow工作流
- 总览Workflow工作流
- 查询Workflow待办事项
- 在线服务鉴权
- 创建在线服务包
- 获取Execution列表
- 新建Workflow Execution
- 删除Workflow Execution
- 查询Workflow Execution
- 更新Workflow Execution
- 管理Workflow Execution
- 管理Workflow StepExecution
- 获取Workflow工作流节点度量信息
- 新建消息订阅Subscription
- 删除消息订阅Subscription
- 查询消息订阅Subscription详情
- 更新消息订阅Subscription
- 创建工作流定时调度
- 查询工作流定时调度详情
- 删除工作流定时调度信息
- 更新工作流定时调度信息
-
开发环境管理
- 创建Notebook实例
- 查询Notebook实例列表
- 查询所有Notebook实例列表
- 查询Notebook实例详情
- 更新Notebook实例
- 删除Notebook实例
- 通过运行的实例保存成容器镜像
- 查询Notebook支持的有效规格列表
- 查询Notebook支持的可切换规格列表
- 查询运行中的Notebook可用时长
- Notebook时长续约
- 启动Notebook实例
- 停止Notebook实例
- 获取动态挂载OBS实例信息列表
- 动态挂载OBS
- 获取动态挂载OBS实例详情
- 动态卸载OBS
- 添加资源标签
- 删除资源标签
- 查询Notebook资源类型下的标签
- 查询支持的镜像列表
- 注册自定义镜像
- 查询用户镜像组列表
- 查询镜像详情
- 删除镜像
-
训练管理
- 创建算法
- 查询算法列表
- 查询算法详情
- 更新算法
- 删除算法
- 获取支持的超参搜索算法
- 创建训练实验
- 创建训练作业
- 查询训练作业详情
- 更新训练作业描述
- 删除训练作业
- 终止训练作业
- 查询训练作业指定任务的日志(预览)
- 查询训练作业指定任务的日志(OBS链接)
- 查询训练作业指定任务的运行指标
- 查询训练作业列表
- 查询超参搜索所有trial的结果
- 查询超参搜索某个trial的结果
- 获取超参敏感度分析结果
- 获取某个超参敏感度分析图像的路径
- 提前终止自动化搜索作业的某个trial
- 获取自动化搜索作业yaml模板的信息
- 获取自动化搜索作业yaml模板的内容
- 创建训练作业标签
- 删除训练作业标签
- 查询训练作业标签
- 获取训练作业事件列表
- 创建训练作业镜像保存任务
- 查询训练作业镜像保存任务
- 获取训练作业支持的公共规格
- 获取训练作业支持的AI预置框架
- AI应用管理
- APP认证管理
- 服务管理
- 资源管理
- DevServer管理
- 授权管理
- 工作空间管理
- 配额管理
- 资源标签管理
- 节点池管理
- 应用示例
- 权限策略和授权项
- 公共参数
-
历史API
-
数据管理(旧版)
- 查询数据集列表
- 创建数据集
- 查询数据集详情
- 更新数据集
- 删除数据集
- 查询数据集的统计信息
- 查询数据集监控数据
- 查询数据集的版本列表
- 创建数据集标注版本
- 查询数据集版本详情
- 删除数据集标注版本
- 查询样本列表
- 批量添加样本
- 批量删除样本
- 查询单个样本信息
- 获取样本搜索条件
- 分页查询团队标注任务下的样本列表
- 查询团队标注的样本信息
- 查询数据集标签列表
- 创建数据集标签
- 批量修改标签
- 批量删除标签
- 按标签名称更新单个标签
- 按标签名称删除标签及仅包含此标签的文件
- 批量更新样本标签
- 查询数据集的团队标注任务列表
- 创建团队标注任务
- 查询团队标注任务详情
- 启动团队标注任务
- 更新团队标注任务
- 删除团队标注任务
- 创建团队标注验收任务
- 查询团队标注验收任务报告
- 更新团队标注验收任务状态
- 查询团队标注任务统计信息
- 查询团队标注任务成员的进度信息
- 团队成员查询团队标注任务列表
- 提交验收任务的样本评审意见
- 团队标注审核
- 批量更新团队标注样本的标签
- 查询标注团队列表
- 创建标注团队
- 查询标注团队详情
- 更新标注团队
- 删除标注团队
- 向标注成员发送邮件
- 查询所有团队的标注成员列表
- 查询标注团队的成员列表
- 创建标注团队的成员
- 批量删除标注团队成员
- 查询标注团队成员详情
- 更新标注团队成员
- 删除标注团队成员
- 查询数据集导入任务列表
- 创建导入任务
- 查询数据集导入任务的详情
- 查询数据集导出任务列表
- 创建数据集导出任务
- 查询数据集导出任务的状态
- 同步数据集
- 查询数据集同步任务的状态
- 查询智能标注的样本列表
- 查询单个智能标注样本的信息
- 分页查询智能任务列表
- 启动智能任务
- 获取智能任务的信息
- 停止智能任务
- 查询处理任务列表
- 创建处理任务
- 查询数据处理的算法类别
- 查询处理任务详情
- 更新处理任务
- 删除处理任务
- 查询数据处理任务的版本列表
- 创建数据处理任务版本
- 查询数据处理任务的版本详情
- 删除数据处理任务的版本
- 查询数据处理任务版本的结果展示
- 停止数据处理任务的版本
- 开发环境(旧版)
- 训练管理(旧版)
-
数据管理(旧版)
- SDK参考
- 场景代码示例
-
故障排除
- 通用问题
- 自动学习
-
开发环境
- 环境配置故障
- 实例故障
- 代码运行故障
- JupyterLab插件故障
-
VS Code连接开发环境失败故障处理
- 在ModelArts控制台界面上单击VS Code接入并在新界面单击打开,未弹出VS Code窗口
- 在ModelArts控制台界面上单击VS Code接入并在新界面单击打开,VS Code打开后未进行远程连接
- VS Code连接开发环境失败时的排查方法
- 远程连接出现弹窗报错:Could not establish connection to xxx
- 连接远端开发环境时,一直处于"Setting up SSH Host xxx: Downloading VS Code Server locally"超过10分钟以上,如何解决?
- 连接远端开发环境时,一直处于"Setting up SSH Host xxx: Copying VS Code Server to host with scp"超过10分钟以上,如何解决?
- 远程连接处于retry状态如何解决?
- 报错“The VS Code Server failed to start”如何解决?
- 报错“Permissions for 'x:/xxx.pem' are too open”如何解决?
- 报错“Bad owner or permissions on C:\Users\Administrator/.ssh/config”如何解决?
- 报错“Connection permission denied (publickey)”如何解决
- 报错“ssh: connect to host xxx.pem port xxxxx: Connection refused”如何解决?
- 报错"ssh: connect to host ModelArts-xxx port xxx: Connection timed out"如何解决?
- 报错“Load key "C:/Users/xx/test1/xxx.pem": invalid format”如何解决?
- 报错“An SSH installation couldn't be found”或者“Could not establish connection to instance xxx: 'ssh' ...”如何解决?
- 报错“no such identity: C:/Users/xx /test.pem: No such file or directory”如何解决?
- 报错“Host key verification failed.'或者'Port forwarding is disabled.”如何解决?
- 报错“Failed to install the VS Code Server.”或“tar: Error is not recoverable: exiting now.”如何解决?
- VS Code连接远端Notebook时报错“XHR failed”
- VS Code连接后长时间未操作,连接自动断开
- VS Code自动升级后,导致远程连接时间过长
- 使用SSH连接,报错“Connection reset”如何解决?
- 使用MobaXterm工具SSH连接Notebook后,经常断开或卡顿,如何解决?
- VS Code连接开发环境时报错Missing GLIBC,Missing required dependencies
- 使用VSCode-huawei,报错:卸载了‘ms-vscode-remote.remot-sdh’,它被报告存在问题
- 使用VS Code连接实例时,发现VS Code端的实例目录和云上目录不匹配
- VSCode远程连接时卡顿,或Python调试插件无法使用如何处理?
-
自定义镜像故障
- Notebook自定义镜像故障基础排查
- 镜像保存时报错“there are processes in 'D' status, please check process status using 'ps -aux' and kill all the 'D' status processes”或“Buildimge,False,Error response from daemon,Cannot pause container xxx”如何解决?
- 镜像保存时报错“container size %dG is greater than threshold %dG”如何解决?
- 保存镜像时报错“too many layers in your image”如何解决?
- 镜像保存时报错“The container size (xG) is greater than the threshold (25G)”如何解决?
- 镜像保存时报错“BuildImage,True,Commit successfully|PushImage,False,Task is running.”
- 使用自定义镜像创建Notebook后打开没有kernel
- 用户自定义镜像自建的conda环境会查到一些额外的包,影响用户程序,如何解决?
- 用户使用ma-cli制作自定义镜像失败,报错文件不存在(not found)
- 用户使用torch报错Unexpected error from cudaGetDeviceCount
- 其他故障
-
训练作业
- OBS操作相关故障
-
云上迁移适配故障
- 无法导入模块
- 训练作业日志中提示“No module named .*”
- 如何安装第三方包,安装报错的处理方法
- 下载代码目录失败
- 训练作业日志中提示“No such file or directory”
- 训练过程中无法找到so文件
- ModelArts训练作业无法解析参数,日志报错
- 训练输出路径被其他作业使用
- PyTorch1.0引擎提示“RuntimeError: std:exception”
- MindSpore日志提示“ retCode=0x91, [the model stream execute failed]”
- 使用moxing适配OBS路径,pandas读取文件报错
- 日志提示“Please upgrade numpy to >= xxx to use this pandas version”
- 重装的包与镜像装CUDA版本不匹配
- 创建训练作业提示错误码ModelArts.2763
- 训练作业日志中提示 “AttributeError: module '***' has no attribute '***'”
- 系统容器异常退出
- 硬盘限制故障
- 外网访问限制
- 权限问题
- GPU相关问题
-
业务代码问题
- 日志提示“pandas.errors.ParserError: Error tokenizing data. C error: Expected .* fields”
- 日志提示“max_pool2d_with_indices_out_cuda_frame failed with error code 0”
- 训练作业失败,返回错误码139
- 训练作业失败,如何使用开发环境调试训练代码?
- 日志提示“ '(slice(0, 13184, None), slice(None, None, None))' is an invalid key”
- 日志报错“DataFrame.dtypes for data must be int, float or bool”
- 日志提示“CUDNN_STATUS_NOT_SUPPORTED. ”
- 日志提示“Out of bounds nanosecond timestamp”
- 日志提示“Unexpected keyword argument passed to optimizer”
- 日志提示“no socket interface found”
- 日志提示“Runtimeerror: Dataloader worker (pid 46212 ) is killed by signal: Killed BP”
- 日志提示“AttributeError: 'NoneType' object has no attribute 'dtype'”
- 日志提示“No module name 'unidecode'”
- 分布式Tensorflow无法使用“tf.variable”
- MXNet创建kvstore时程序被阻塞,无报错
- 日志出现ECC错误,导致训练作业失败
- 超过最大递归深度导致训练作业失败
- 使用预置算法训练时,训练失败,报“bndbox”错误
- 训练作业进程异常退出
- 训练作业进程被kill
- 预置算法运行故障
- 训练作业运行失败
- 专属资源池创建训练作业
- 训练作业性能问题
- Ascend相关问题
-
推理部署
-
模型管理
- 创建模型失败,如何定位和处理问题?
- 导入模型提示该账号受限或者没有操作权限
- 用户创建模型时构建镜像或导入文件失败
- 创建模型时,OBS文件目录对应镜像里面的目录结构是什么样的?
- 通过OBS导入模型时,如何编写打印日志代码才能在ModelArts日志查询界面看到日志
- 通过OBS创建模型时,构建日志中提示pip下载包失败
- 通过自定义镜像创建模型失败
- 导入模型后部署服务,提示磁盘不足
- 创建模型成功后,部署服务报错,如何排查代码问题
- 自定义镜像导入配置运行时依赖无效
- 通过API接口查询模型详情,model_name返回值出现乱码
- 导入模型提示模型或镜像大小超过限制
- 导入模型提示单个模型文件超过5G限制
- 订阅的模型一直处于等待同步状态
- 创建模型失败,提示模型镜像构建任务超时,没有构建日志
-
服务部署
- 自定义镜像模型部署为在线服务时出现异常
- 部署的在线服务状态为告警
- 服务启动失败
- 服务部署、启动、升级和修改时,拉取镜像失败如何处理?
- 服务部署、启动、升级和修改时,镜像不断重启如何处理?
- 服务部署、启动、升级和修改时,容器健康检查失败如何处理?
- 服务部署、启动、升级和修改时,资源不足如何处理?
- 模型使用CV2包部署在线服务报错
- 服务状态一直处于“部署中”
- 服务启动后,状态断断续续处于“告警中”
- 服务部署失败,报错No Module named XXX
- IEF节点边缘服务部署失败
- 批量服务输入/输出obs目录不存在或者权限不足
- 部署在线服务出现报错No CUDA runtime is found
- 使用AI市场物体检测YOLOv3_Darknet53算法训练后部署在线服务报错
- 使用预置AI算法部署在线服务报错gunicorn:error:unrecorgized arguments
- 内存不足如何处理?
- 服务预测
-
模型管理
- MoXing
- API/SDK
- 资源池
-
Lite Server
- GPU裸金属服务器使用EulerOS内核误升级如何解决
- GPU A系列裸金属服务器无法获取显卡如何解决
- GPU裸金属服务器无法Ping通如何解决
- GPU A系列裸金属服务器RoCE带宽不足如何解决?
- GPU裸金属服务器更换NVIDIA驱动后执行nvidia-smi提示Failed to initialize NVML
- 训练速度突然下降以及执行nvidia-smi卡顿如何解决?
- GP Vnt1裸金属服务器用PyTorch报错CUDA initialization:CUDA unknown error
- 使用SFS盘出现报错rpc_check_timeout:939 callbacks suppressed
- 华为云CCE集群纳管GPU裸金属服务器由于CloudInit导致纳管失败的解决方案
- GPU A系列裸金属服务器使用CUDA cudaGetDeviceCount()提示CUDA initializat失败
- 裸金属服务器Euler OS升级NetworkManager-config-server导致SSH链接故障解决方案
- Lite Cluster
-
常见问题
- 权限相关
- 存储相关
- Standard自动学习
- Standard Workflow
-
Standard数据准备
- 在ModelArts数据集中添加图片对图片大小有限制吗?
- 如何将本地标注的数据导入ModelArts?
- 在ModelArts中数据标注完成后,标注结果存储在哪里?
- 在ModelArts中如何将标注结果下载至本地?
- 在ModelArts中进行团队标注时,为什么团队成员收不到邮件?
- ModelArts团队标注的数据分配机制是什么?
- 如何将两个ModelArts数据集合并?
- 在ModelArts中同一个账户,图片展示角度不同是为什么?
- 在ModelArts中智能标注完成后新加入数据需要重新训练吗?
- 在ModelArts中如何将图片划分到验证集或者训练集?
- 在ModelArts中物体检测标注时能否自定义标签?
- ModelArts数据集新建的版本找不到怎么办?
- 如何切分ModelArts数据集?
- 如何删除ModelArts数据集中的图片?
-
Standard Notebook
- ModelArts的Notebook是否支持Keras引擎?
- 如何在ModelArts的Notebook中上传下载OBS文件?
- ModelArts的Notebook实例upload后,数据会上传到哪里?
- 在ModelArts中如何将Notebook A的数据复制到Notebook B中?
- 在ModelArts的Notebook中如何对OBS的文件重命名?
- 在ModelArts的Notebook中如何使用pandas库处理OBS桶中的数据?
- 在ModelArts的Notebook中,如何访问其他账号的OBS桶?
- 在ModelArts的Notebook中JupyterLab默认工作路径是什么?
- 如何查看ModelArts的Notebook使用的cuda版本?
- 在ModelArts的Notebook中如何获取本机外网IP?
- ModelArts的Notebook有代理吗?如何关闭?
- 在ModelArts的Notebook中内置引擎不满足使用需要时,如何自定义引擎IPython Kernel?
- 在ModelArts的Notebook中如何将git clone的py文件变为ipynb文件?
- 在ModelArts的Notebook实例重启时,数据集会丢失吗?
- 在ModelArts的Notebook的Jupyterlab可以安装插件吗?
- 在ModelArts的Notebook的CodeLab中能否使用昇腾卡进行训练?
- 如何在ModelArts的Notebook的CodeLab上安装依赖?
- 在ModelArts的Notebook中安装远端插件时不稳定要怎么办?
- 在ModelArts的Notebook中实例重新启动后要怎么连接?
- 在ModelArts的Notebook中使用VS Code调试代码无法进入源码怎么办?
- 在ModelArts的Notebook中使用VS Code如何查看远端日志?
- 在ModelArts的Notebook中如何打开VS Code的配置文件settings.json?
- 在ModelArts的Notebook中如何设置VS Code背景色为豆沙绿?
- 在ModelArts的Notebook中如何设置VS Code远端默认安装的插件?
- 在ModelArts的VS Code中如何把本地插件安装到远端或把远端插件安装到本地?
- 在ModelArts的Notebook中,如何使用昇腾多卡进行调试?
- 在ModelArts的Notebook中使用不同的资源规格训练时为什么训练速度差不多?
- 在ModelArts的Notebook中使用MoXing时,如何进行增量训练?
- 在ModelArts的Notebook中如何查看GPU使用情况?
- 在ModelArts的Notebook中如何在代码中打印GPU使用信息?
- 在ModelArts的Notebook中JupyterLab的目录、Terminal的文件和OBS的文件之间的关系是什么?
- 如何在ModelArts的Notebook实例中使用ModelArts数据集?
- pip介绍及常用命令
- 在ModelArts的Notebook中不同规格资源/cache目录的大小是多少?
- 资源超分对在ModelArts的Notebook实例有什么影响?
- 如何在Notebook中安装外部库?
- 在ModelArts的Notebook中,访问外网速度不稳定怎么办?
-
Standard模型训练
- 在ModelArts训练得到的模型欠拟合怎么办?
- 在ModelArts中训练好后的模型如何获取?
- 在ModelArts上如何获得RANK_TABLE_FILE用于分布式训练?
- 在ModelArts上训练模型如何配置输入输出数据?
- 在ModelArts上如何提升训练效率并减少与OBS的交互?
- 在ModelArts中使用Moxing复制数据时如何定义路径变量?
- 在ModelArts上如何创建引用第三方依赖包的训练作业?
- 在ModelArts训练时如何安装C++的依赖库?
- 在ModelArts训练作业中如何判断文件夹是否复制完毕?
- 如何在ModelArts训练作业中加载部分训练好的参数?
- ModelArts训练时使用os.system('cd xxx')无法进入文件夹怎么办?
- 在ModelArts训练代码中,如何获取依赖文件所在的路径?
- 自如何获取ModelArts训练容器中的文件实际路径?
- ModelArts训练中不同规格资源“/cache”目录的大小是多少?
- ModelArts训练作业为什么存在/work和/ma-user两种超参目录?
- 如何查看ModelArts训练作业资源占用情况?
- 如何将在ModelArts中训练好的模型下载或迁移到其他账号?
-
Standard推理部署
- 如何将Keras的.h5格式的模型导入到ModelArts中?
- ModelArts导入模型时,如何编写模型配置文件中的安装包依赖参数?
- 在ModelArts中使用自定义镜像创建在线服务,如何修改端口?
- ModelArts平台是否支持多模型导入?
- 在ModelArts中导入模型对于镜像大小有什么限制?
- ModelArts在线服务和批量服务有什么区别?
- ModelArts在线服务和边缘服务有什么区别?
- 在ModelArts中部署模型时,为什么无法选择Ascend Snt3资源?
- ModelArts线上训练得到的模型是否支持离线部署在本地?
- ModelArts在线服务预测请求体大小限制是多少?
- ModelArts部署在线服务时,如何避免自定义预测脚本python依赖包出现冲突?
- ModelArts在线服务预测时,如何提高预测速度?
- 在ModelArts中调整模型后,部署新版本模型能否保持原API接口不变?
- ModelArts在线服务的API接口组成规则是什么?
- ModelArts在线服务处于运行中时,如何填写request header和request body?
-
Standard镜像相关
- 不在同一个主账号下,如何使用他人的自定义镜像创建Notebook?
- 如何登录并上传镜像到SWR?
- 在Dockerfile中如何给镜像设置环境变量?
- 如何通过docker镜像启动容器?
- 如何在ModelArts的Notebook中配置Conda源?
- ModelArts的自定义镜像软件版本匹配有哪些注意事项?
- 镜像在SWR上显示只有13G,安装少量的包,然后镜像保存过程会提示超过35G大小保存失败,为什么?
- 如何保证自定义镜像能不因为超过35G而保存失败?
- 如何减小本地或ECS构建镜像的目的镜像的大小?
- 镜像过大,卸载原来的包重新打包镜像,最终镜像会变小吗?
- 在ModelArts镜像管理注册镜像报错ModelArts.6787怎么处理?
- 用户如何设置默认的kernel?
- Standard专属资源池
- Studio
- Edge
- API/SDK
- Lite Server
- Lite Cluster
- 历史文档待下线
- 视频帮助
- 文档下载
- 通用参考

链接复制成功!
准备镜像环境
准备训练模型适用的容器镜像,包括获取镜像地址,了解镜像中包含的各类固件版本,配置物理机环境操作。
镜像地址
本教程中用到的训练和推理的基础镜像地址和配套版本关系如下表所示,请提前了解。
|
镜像用途 |
镜像地址 |
|---|---|
|
基础镜像 |
swr.cn-southwest-2.myhuaweicloud.com/atelier/pytorch_2_1_ascend:pytorch_2.1.0-cann_8.0.rc3-py_3.9-hce_2.0.2409-aarch64-snt9b-20241112192643-c45ac6b |
|
模型 |
版本 |
|---|---|
|
CANN |
cann_8.0.rc3 |
|
驱动 |
23.0.6 |
|
PyTorch |
2.1.0 |
步骤一 检查环境
- SSH登录机器后,检查NPU设备检查。运行如下命令,返回NPU设备信息。
npu-smi info # 在每个实例节点上运行此命令可以看到NPU卡状态 npu-smi info -l | grep Total # 在每个实例节点上运行此命令可以看到总卡数
如出现错误,可能是机器上的NPU设备没有正常安装,或者NPU镜像被其他容器挂载。请先正常安装NPU设备和驱动,或释放被挂载的NPU。
- 检查containerd是否安装。
containerd -v # 检查containerd是否安装
在创建CCE集群时,会选择containerd作为容器引擎,并默认给机器安装。如尚未安装,说明机器操作系统安装错误。需要重新纳管机器,重新安装操作系统。
- 安装nerdctl工具。nerdctl是containerd的一个客户端命令行工具,使用方式和docker命令基本一致,可用于后续镜像构建步骤中。
# 下载 nerdctl 工具,注意使用的是1.7.6 arm64版本 wget https://github.com/containerd/nerdctl/releases/download/v1.7.6/nerdctl-1.7.6-linux-arm64.tar.gz # 将程序解压至运行目录中 tar -zxf nerdctl-1.7.6-linux-arm64.tar.gz -C /usr/bin/ # 查看是否安装成功 nerdctl -v
- 安装buildkit工具。buildkit是从Docker从公司开源出来的下一代镜像构建工具,支持OCI标准的镜像构建,nerdctl需要结合buildkit一起使用。buildkit由两部分组成:
buildkitd(服务端):负责镜像构建,目前支持runc和containerd作为镜像构建环境,默认是runc。
buildkitctl(客户端):负责解析Dockerfile文件,并向服务端buildkitd发出构建请求。
- 下载并解压buildkit程序。
# 下载 buildkit 工具,注意使用的是0.15.1 arm64版本 wget https://github.com/moby/buildkit/releases/download/v0.15.1/buildkit-v0.15.1.linux-arm64.tar.gz # 创建解压的目录 mkdir /usr/local/buildkit # 解压到指定的目录 tar -zxf buildkit-v0.15.1.linux-arm64.tar.gz -C /usr/local/buildkit # 授予权限 chmod -R 777 /usr/local/buildkit
- 添加环境变量
echo 'export PATH=/usr/local/buildkit/bin:$PATH' >> /etc/profile # 注意这里的echo 要使用单引号,单引号会原样输出,双引号会解析变量 source /etc/profile # 使刚才配置生效
- 创建buildkitd的启动服务。其中都是buildkitd.service的内容。复制以下全部命令并运行即可。
cat <<EOF > /usr/lib/systemd/system/buildkitd.service [Unit] Description=buildkitd After=network.target [Service] ExecStart=/usr/local/buildkit/bin/buildkitd [Install] WantedBy=multi-user.target EOF
- 启动buildkitd的服务
# 重新加载Unit file systemctl daemon-reload # 启动服务 systemctl start buildkitd # 开机自启动 systemctl enable buildkitd # 查看状态 systemctl status buildkitd
- 若buildkitd的服务运行状态如下图所示,则表示服务运行成功。使用Ctrl+C即可退出查看状态。
- 下载并解压buildkit程序。

步骤二 获取训练镜像
建议使用官方提供的镜像部署训练服务。镜像地址{image_url}参见镜像地址获取。
containerd 容器引擎有命名空间的概念。Kubernetes 下使用的 containerd 默认命名空间是 k8s.io。所以在导入镜像时需要指定命令空间为 k8s.io,否则使用 crictl images 无法查询到。以下命令可选其一进行镜像拉取:
- 使用 containerd 自带的工具 ctr 进行镜像拉取。
ctr -n k8s.io pull {image_url} - 使用nerdctl工具拉取镜像。
nerdctl --namespace k8s.io pull {image_url}
 注意:
注意:
集群有多个节点,要确保每个节点都拥有镜像。
# ctr 工具查看 ctr -n k8s.io image list # 或 crictl image # nerdctl 工具查看 nerdctl --namespace k8s.io image list
步骤三 构建ModelArts Lite训练镜像
获取模型软件包,并上传到机器SFS Turbo的目录下(可自定义路径),获取地址参考表1。
- 解压AscendCloud压缩包及该目录下的训练代码AscendCloud-LLM-6.3.908-xxx.zip,并直接进入到llm_train/AscendSpeed文件夹下面
unzip AscendCloud-*.zip -d ./AscendCloud && unzip ./AscendCloud/AscendCloud-LLM-*.zip -d ./AscendCloud/AscendCloud-LLM && cd ./AscendCloud/AscendCloud-LLM/llm_train/AscendSpeed
- 编辑llm_train/AscendSpeed中的Dockerfile文件第一行镜像地址,修改为本文档中的基础镜像地址。
FROM {image_url} - (选填)编辑llm_train/AscendSpeed中的Dockerfile文件,修改git命令,填写自己的git账户信息。
git config --global user.email "you@example.com" && \ git config --global user.name "Your Name" && \
注意:
若要对ChatCLMv3、GLMv4系列模型进行训练时,需要修改 Dockerfile 中的 transformers 的版本。
由默认 transformers==4.45.0 修改为:transformers==4.44.2
- 执行以下命令制作训练镜像。安装过程需要连接互联网git clone,请确保机器可以访问公网。
nerdctl --namespace k8s.io build -t <镜像名称>:<版本名称> .
nerdctl build 会去镜像仓库拉取镜像,不会直接使用本地镜像。构建前可以 nerdctl pull 拉取测试以下镜像是否能拉取成功。- <镜像名称>:<版本名称>:定义镜像名称。示例:pytorch_2_1_ascend:20240606。
- 记住使用Dockerfile创建的新镜像名称, 后续使用 ${dockerfile_image_name} 进行表示。
步骤四 在节点机器中Docker登录
在SWR中单击右上角的“登录指令”,然后在跳出的登录指定窗口,单击复制临时登录指令。

# docker login 替换为: nerdctl login
步骤五 修改并上传镜像
1. 在机器中输入Step4登录指令后,使用下列示例命令将镜像上传至SWR:
nerdctl --namespace k8s.io tag ${dockerfile_image_name} <镜像仓库地址>/<组织名称>/<镜像名称>:<版本名称>参数说明:
- ${dockerfile_image_name}:在步骤三 构建ModelArts Lite训练镜像中使用Dockerfile创建的新镜像名称。
- <镜像仓库地址>:可在SWR控制台上查询,容器镜像服务中登录指令末尾的域名即为镜像仓库地址。
- <组织名称>:Step3中自己创建的组织名称。示例:GROUP_NAME
- <镜像名称>:<版本名称>:定义镜像名称。示例:pytorch_2_1_ascend:20240606
示例:
nerdctl --namespace k8s.io tag ${dockerfile_image_name} swr.cn-southwest-2.myhuaweicloud.com/GPOUP_NAME/pytorch_2_1_ascend:20240606
2. 上传镜像至镜像仓库。
nerdctl --namespace k8s.io push <镜像仓库地址>/<组织名称>/<镜像名称>:<版本名称>
示例:
nerdctl --namespace k8s.io push swr.cn-southwest-2.myhuaweicloud.com/GPOUP_NAME/pytorch_2_1_ascend:20240606
步骤六 编写Config.yaml文件
k8s有两种方式来管理对象:
- 命令式,即通过Kubectl指令直接操作对象。
- 声明式,通过定义资源YAML格式的文件来操作对象。
apiVersion: v1
kind: ConfigMap
metadata:
name: configmap1980-vcjob # 前缀使用“configmap1980-”不变,后接vcjob的名字
namespace: default # 命名空间自选,需要和下边的vcjob处在同一命名空间
labels:
ring-controller.cce: ascend-1980 # 保持不动
data: # data内容保持不动,初始化完成,会被volcano插件自动修改
jobstart_hccl.json: |
{
"status":"initializing"
}
---
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: vcjob # job名字,需要和configmap中名字保持联系
namespace: default # 和configmap保持一致
labels:
ring-controller.cce: ascend-1980 # 保持不动
fault-scheduling: "force"
spec:
minAvailable: 1
schedulerName: volcano # 保持不动
policies:
- event: PodEvicted
action: RestartJob
plugins:
configmap1980:
- --rank-table-version=v2 # 保持不动,生成v2版本ranktablefile
env: []
svc:
- --publish-not-ready-addresses=true
maxRetry: 5
queue: default
tasks:
- name: main
replicas: 1
template:
metadata:
name: training
labels:
app: ascendspeed
ring-controller.cce: ascend-1980 # 保持不动
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: volcano.sh/job-name
operator: In
values:
- vcjob
topologyKey: kubernetes.io/hostname
hostNetwork: true # 采用宿主机网络模式
containers:
- image: ${image_name} # 镜像地址
imagePullPolicy: IfNotPresent # IfNotPresent:默认值,镜像在宿主机上不存在时才拉取;Always:每次创建Pod都会重新拉取一次镜像;Never:Pod永远不会主动拉取这个镜像
name: ${container_name}
securityContext: # 容器内 root 权限
allowPrivilegeEscalation: false
runAsUser: 0
env:
- name: name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: ip
valueFrom:
fieldRef:
fieldPath: status.hostIP
- name: framework
value: "PyTorch"
command: ["/bin/sh", "-c"]
args:
- ${command}
resources:
requests:
huawei.com/ascend-1980: "8" # 需求卡数,key保持不变.
memory: ${requests_memory} # 容器请求的最小内存
cpu: ${requests_cpu} # 容器请求的最小 CPU
limits:
huawei.com/ascend-1980: "8" # 限制卡数,key保持不变。
memory: ${limits_memory} # 容器可使用的最大内存
cpu: ${limits_cpu} # 容器可使用的最大 CPU
volumeMounts: # 容器内部映射路径
- name: shared-memory-volume
mountPath: /dev/shm
- name: ascend-driver # 驱动挂载,保持不动
mountPath: /usr/local/Ascend/driver
- name: ascend-add-ons # 驱动挂载,保持不动
mountPath: /usr/local/Ascend/add-ons
- name: localtime
mountPath: /etc/localtime
- name: hccn # 驱动hccn配置,保持不动
mountPath: /etc/hccn.conf
- name: npu-smi # npu-smi
mountPath: /usr/local/sbin/npu-smi
- name: ascend-install
mountPath: /etc/ascend_install.info
- name: log
mountPath: /var/log/npu/
- name: sfs-volume
mountPath: /mnt/sfs_turbo
nodeSelector:
accelerator/huawei-npu: ascend-1980
volumes: # 物理机外部路径
- name: shared-memory-volume # 共享内存
emptyDir:
medium: Memory
sizeLimit: "200Gi"
- name: ascend-driver
hostPath:
path: /usr/local/Ascend/driver
- name: ascend-add-ons
hostPath:
path: /usr/local/Ascend/add-ons
- name: localtime
hostPath:
path: /etc/localtime
- name: hccn
hostPath:
path: /etc/hccn.conf
- name: npu-smi
hostPath:
path: /usr/local/sbin/npu-smi
- name: ascend-install
hostPath:
path: /etc/ascend_install.info
- name: log
hostPath:
path: /usr/slog
- name: sfs-volume
persistentVolumeClaim:
claimName: ${pvc_name} #已创建的PVC名称
restartPolicy: OnFailure双个节点训练的config.yaml文件模板,用于实现双机分布式训练。
apiVersion: v1
kind: ConfigMap
metadata:
name: configmap1980-vcjob # 前缀使用“configmap1980-”不变,后接vcjob的名字
namespace: default # 命名空间自选,需要和下边的vcjob处在同一命名空间
labels:
ring-controller.cce: ascend-1980 # 保持不动
data: #data内容保持不动,初始化完成,会被volcano插件自动修改
jobstart_hccl.json: |
{
"status":"initializing"
}
---
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: vcjob # job名字,需要和configmap中名字保持联系
namespace: default # 和configmap保持一致
labels:
ring-controller.cce: ascend-1980 # 保持不动
fault-scheduling: "force"
spec:
minAvailable: 1
schedulerName: volcano # 保持不动
policies:
- event: PodEvicted
action: RestartJob
plugins:
configmap1980:
- --rank-table-version=v2 # 保持不动,生成v2版本ranktablefile
env: []
svc:
- --publish-not-ready-addresses=true
maxRetry: 5
queue: default
tasks:
- name: main
replicas: 1
template:
metadata:
name: training
labels:
app: ascendspeed
ring-controller.cce: ascend-1980 # 保持不动
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: volcano.sh/job-name
operator: In
values:
- vcjob
topologyKey: kubernetes.io/hostname
hostNetwork: true # 采用宿主机网络模式
containers:
- image: ${image_name} # 镜像地址
imagePullPolicy: IfNotPresent # IfNotPresent:默认值,镜像在宿主机上不存在时才拉取;Always:每次创建Pod都会重新拉取一次镜像;Never:Pod永远不会主动拉取这个镜像
name: ${container_name}
securityContext: # 容器内 root 权限
allowPrivilegeEscalation: false
runAsUser: 0
env:
- name: name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: ip
valueFrom:
fieldRef:
fieldPath: status.hostIP
- name: framework
value: "PyTorch"
command: ["/bin/sh", "-c"]
args:
- ${command}
resources:
requests:
huawei.com/ascend-1980: "8" # 需求卡数,key保持不变.
memory: ${requests_memory} # 容器请求的最小内存
cpu: ${requests_cpu} # 容器请求的最小 CPU
limits:
huawei.com/ascend-1980: "8" # 限制卡数,key保持不变。
memory: ${limits_memory} # 容器可使用的最大内存
cpu: ${limits_cpu} # 容器可使用的最大 CPU
volumeMounts: # 容器内部映射路径
- name: shared-memory-volume
mountPath: /dev/shm
- name: ascend-driver # 驱动挂载,保持不动
mountPath: /usr/local/Ascend/driver
- name: ascend-add-ons # 驱动挂载,保持不动
mountPath: /usr/local/Ascend/add-ons
- name: localtime
mountPath: /etc/localtime
- name: hccn # 驱动hccn配置,保持不动
mountPath: /etc/hccn.conf
- name: npu-smi # npu-smi
mountPath: /usr/local/sbin/npu-smi
- name: ascend-install
mountPath: /etc/ascend_install.info
- name: log
mountPath: /var/log/npu/
- name: sfs-volume
mountPath: /mnt/sfs_turbo
nodeSelector:
accelerator/huawei-npu: ascend-1980
volumes: # 物理机外部路径
- name: shared-memory-volume # 共享内存
emptyDir:
medium: Memory
sizeLimit: "200Gi"
- name: ascend-driver
hostPath:
path: /usr/local/Ascend/driver
- name: ascend-add-ons
hostPath:
path: /usr/local/Ascend/add-ons
- name: localtime
hostPath:
path: /etc/localtime
- name: hccn
hostPath:
path: /etc/hccn.conf
- name: npu-smi
hostPath:
path: /usr/local/sbin/npu-smi
- name: ascend-install
hostPath:
path: /etc/ascend_install.info
- name: log
hostPath:
path: /usr/slog
- name: sfs-volume
persistentVolumeClaim:
claimName: ${pvc_name} #已创建的PVC名称
restartPolicy: OnFailure
- name: work
replicas: 1
template:
metadata:
name: training
labels:
app: ascendspeed
ring-controller.cce: ascend-1980 # 保持不动
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: volcano.sh/job-name
operator: In
values:
- vcjob
topologyKey: kubernetes.io/hostname
hostNetwork: true # 采用宿主机网络模式
containers:
- image: ${image_name} # 镜像地址
imagePullPolicy: IfNotPresent # IfNotPresent:默认值,镜像在宿主机上不存在时才拉取;Always:每次创建Pod都会重新拉取一次镜像;Never:Pod永远不会主动拉取这个镜像
name: ${container_name}
securityContext: # 容器内 root 权限
allowPrivilegeEscalation: false
runAsUser: 0
env:
- name: name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: ip
valueFrom:
fieldRef:
fieldPath: status.hostIP
- name: framework
value: "PyTorch"
command: ["/bin/sh", "-c"]
args:
- ${command}
resources:
requests:
huawei.com/ascend-1980: "8" # 需求卡数,key保持不变.
memory: ${requests_memory} # 容器请求的最小内存
cpu: ${requests_cpu} # 容器请求的最小 CPU
limits:
huawei.com/ascend-1980: "8" # 限制卡数,key保持不变。
memory: ${limits_memory} # 容器可使用的最大内存
cpu: ${limits_cpu} # 容器可使用的最大 CPU
volumeMounts: # 容器内部映射路径
- name: shared-memory-volume
mountPath: /dev/shm
- name: ascend-driver # 驱动挂载,保持不动
mountPath: /usr/local/Ascend/driver
- name: ascend-add-ons # 驱动挂载,保持不动
mountPath: /usr/local/Ascend/add-ons
- name: localtime
mountPath: /etc/localtime
- name: hccn # 驱动hccn配置,保持不动
mountPath: /etc/hccn.conf
- name: npu-smi # npu-smi
mountPath: /usr/local/sbin/npu-smi
- name: ascend-install
mountPath: /etc/ascend_install.info
- name: log
mountPath: /var/log/npu/
- name: sfs-volume
mountPath: /mnt/sfs_turbo
nodeSelector:
accelerator/huawei-npu: ascend-1980
volumes: # 物理机外部路径
- name: shared-memory-volume # 共享内存
emptyDir:
medium: Memory
sizeLimit: "200Gi"
- name: ascend-driver
hostPath:
path: /usr/local/Ascend/driver
- name: ascend-add-ons
hostPath:
path: /usr/local/Ascend/add-ons
- name: localtime
hostPath:
path: /etc/localtime
- name: hccn
hostPath:
path: /etc/hccn.conf
- name: npu-smi
hostPath:
path: /usr/local/sbin/npu-smi
- name: ascend-install
hostPath:
path: /etc/ascend_install.info
- name: log
hostPath:
path: /usr/slog
- name: sfs-volume
persistentVolumeClaim:
claimName: ${pvc_name} #已创建的PVC名称
restartPolicy: OnFailure参数说明:
- ${container_name} 容器名称,此处可以自己定义一个容器名称,例如ascendspeed。
- ${image_name} 为步骤五 修改并上传镜像中,上传至SWR上的镜像链接。
- ${command} 使用config.yaml文件创建pod后,在容器内自动运行的命令。在进行训练任务中会给出替换命令。
- /mnt/sfs_turbo 为宿主机中默认挂载SFS Turbo的工作目录,目录下存放着训练所需代码、数据等文件。
- 同样,/mnt/sfs_turbo 也可以映射至容器中,作为容器中挂载宿主机的目录。宿主机和容器使用不同的文件系统。为方便访问两个地址可以相同。
- ${pvc_name} 为在CCE集群关联SFS Turbo步骤中创建的PVC名称。
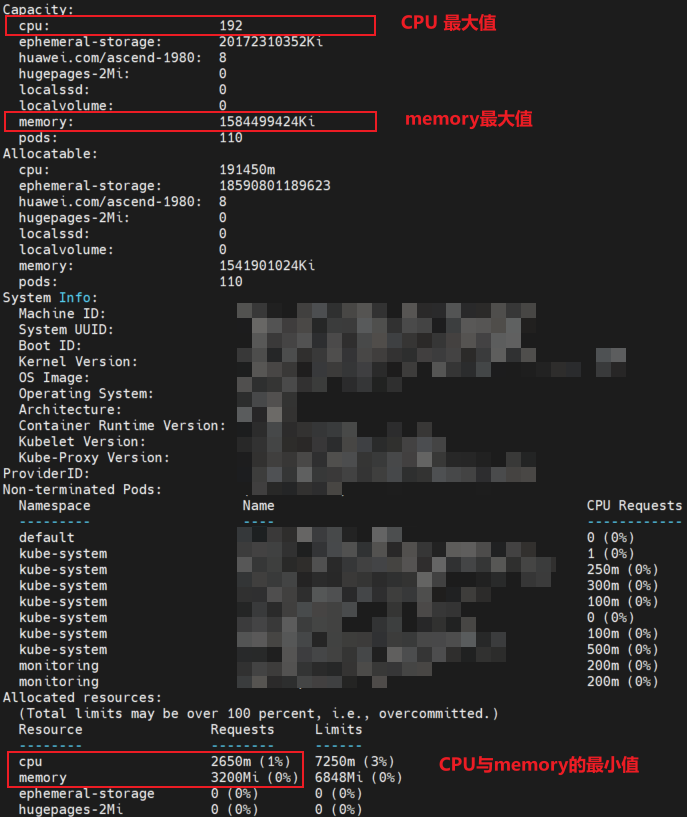
- 在设置容器中需要的CPU与内存大小时,可通过运行以下命令查看申请的节点机器中具体的CPU与内存信息。
kubectl describe node
- ${requests_cpu} 指在容器中请求的最小CPU核心数量,可使用Requests中的值,例如2650m。
- ${requests_memory} 指在容器中请求的最小内存空间大小,可使用Requests中的值,例如3200Mi。
- ${limits_cpu} 指在容器中可使用的最大CPU核心数量,例如192。
- ${limits_memory} 指在容器中可使用的最大内存空间大小,例如换算成1500Gi。