

更新时间:2026-05-25 GMT+08:00
GPU日志收集上传
场景描述
当GPU出现故障,您可以通过本方案收集GPU的日志信息。本方案中生成的日志会保存在节点上,并自动上传至技术支持提供的OBS桶中,日志仅用于问题定位分析,因此需要您提供AK/SK给技术支持,用于授权认证。
操作步骤
- 获取AK/SK。该AK/SK用于后续脚本配置,做认证授权。
如果已生成过AK/SK,则可跳过此步骤,找到原来已下载的AK/SK文件,文件名一般为:credentials.csv。
如下图所示,文件包含了租户名(User Name),AK(Access Key Id),SK(Secret Access Key)。
图1 credential.csv文件内容 AK/SK生成步骤:
AK/SK生成步骤:- 登录华为云管理控制台。
- 单击右上角的用户名,在下拉列表中单击“我的凭证”。
- 单击“访问密钥”。
- 单击“新增访问密钥”。
- 下载密钥,并妥善保管。
- 准备租户名ID和IAM用户名ID,用于OBS桶配置。
将您的租户名ID和IAM用户名ID提供给华为技术支持,技术支持将根据您提供的信息,为您配置OBS桶策略,以便用户收集的日志可以上传至对应的OBS桶。
技术支持配置完成后,会给您提供对应的OBS桶目录“obs_dir”,该目录用于后续配置的脚本中。
图2 租户名ID和IAM用户名ID
- 准备日志收集上传脚本。 修改以下脚本中GpuLogCollection的参数,将ak、sk、obs_dir替换为前面步骤中获取到的值。然后把该脚本上传到要收集GPU日志的节点上。
import json import os import sys import hashlib import hmac import binascii from datetime import datetime class GpuLogCollection(object): GPU_LOG_PATH = "nvidia-bug-report.log.gz" SUPPORT_REGIONS = ['cn-north-4', 'cn-north-9'] OPENSTACK_METADATA = "http://169.254.169.254/openstack/latest/meta_data.json" OBS_BUCKET_PREFIX = "npu-log-" def __init__(self, ak, sk, obs_dir): self.ak = ak self.sk = sk self.obs_dir = obs_dir self.region_id = self.get_region_id() def get_region_id(self): meta_data = os.popen("curl {}".format(self.OPENSTACK_METADATA)) json_meta_data = json.loads(meta_data.read()) meta_data.close() region_id = json_meta_data["region_id"] if region_id not in self.SUPPORT_REGIONS: print("current region {} is not support.".format(region_id)) raise Exception('region exception') return region_id def gen_collect_gpu_log_shell(self): collect_gpu_log_shell = "nvidia-bug-report.sh" return collect_gpu_log_shell def collect_gpu_log(self): print("begin to collect gpu log") os.system(self.gen_collect_gpu_log_shell()) date_collect = datetime.now().strftime('%Y%m%d%H%M%S') instance_ip_obj = os.popen("curl http://169.254.169.254/latest/meta-data/local-ipv4") instance_ip = instance_ip_obj.read() instance_ip_obj.close() log_tar = "%s-gpu-log-%s.gz" % (instance_ip, date_collect) os.system("cp %s %s" % (self.GPU_LOG_PATH, log_tar)) print("success to collect gpu log with {}".format(log_tar)) return log_tar def upload_log_to_obs(self, log_tar): obs_bucket = "{}{}".format(self.OBS_BUCKET_PREFIX, self.region_id) print("begin to upload {} to obs bucket {}".format(log_tar, obs_bucket)) obs_url = "https://%s.obs.%s.myhuaweicloud.com/%s/%s" % (obs_bucket, self.region_id, self.obs_dir, log_tar) date = datetime.utcnow().strftime('%a, %d %b %Y %H:%M:%S GMT') canonicalized_headers = "x-obs-acl:public-read" obs_sign = self.gen_obs_sign(date, canonicalized_headers, obs_bucket, log_tar) auth = "OBS " + self.ak + ":" + obs_sign header_date = '\"' + "Date:" + date + '\"' header_auth = '\"' + "Authorization:" + auth + '\"' header_obs_acl = '\"' + canonicalized_headers + '\"' cmd = "curl -X PUT -T " + log_tar + " " + obs_url + " -H " + header_date + " -H " + header_auth + " -H " + header_obs_acl os.system(cmd) print("success to upload {} to obs bucket {}".format(log_tar, obs_bucket)) # calculate obs auth sign def gen_obs_sign(self, date, canonicalized_headers, obs_bucket, log_tar): http_method = "PUT" canonicalized_resource = "/%s/%s/%s" % (obs_bucket, self.obs_dir, log_tar) IS_PYTHON2 = sys.version_info.major == 2 or sys.version < '3' canonical_string = http_method + "\n" + "\n" + "\n" + date + "\n" + canonicalized_headers + "\n" + canonicalized_resource if IS_PYTHON2: hashed = hmac.new(self.sk, canonical_string, hashlib.sha1) obs_sign = binascii.b2a_base64(hashed.digest())[:-1] else: hashed = hmac.new(self.sk.encode('UTF-8'), canonical_string.encode('UTF-8'), hashlib.sha1) obs_sign = binascii.b2a_base64(hashed.digest())[:-1].decode('UTF-8') return obs_sign def execute(self): log_tar = self.collect_gpu_log() self.upload_log_to_obs(log_tar) if __name__ == '__main__': gpu_log_collection = GpuLogCollection(ak='ak', sk='sk', obs_dir='xxx') gpu_log_collection.execute() - 执行脚本收集日志。
在节点上执行该脚本,可以看到有如下输出,代表日志收集完成并成功上传至OBS。
图3 日志收集完成
- 查看在脚本的同级目录下。可以看到收集到的日志压缩包。 图4 查看结果
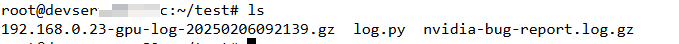
父主题: 轻量算力节点日志采集




