

网络智能体
网络智能体
-
数据资产管理服务
- 文档导读
- 产品介绍
- 快速入门
- 用户指南
-
API参考
- 使用前必读
- 接口简介
- 环境准备
- 接口使用方法
-
数据集
- 数据集订购接口
- 数据集发布接口
- 目录管理接口
- 数据集管理接口
- 数据集可视授权接口
-
订阅和审批接口
- 查询数据集订阅类型
- 申请订阅单个数据集
- 查询已经订阅的数据集
- 将需要订阅的数据集加入购物车
- 删除加入购物车的内容
- 查询加入购物车的内容
- 申请人员查看申请信息
- 查看具体的申请内容
- 添加审批人员信息
- 查看审批人员信息
- 删除审批人员信息
- 审批人员查看待审批或者已经审批的申请信息
- 审批人员审批申请信息
- 查询订购用户信息
- 查询用户订阅并下载成功的数据集信息
- 根据数据集ID查询用户订阅成功数据集详情信息
- 查看给定数据集的订阅情况
- 撤销未审批完成的订单
- 申请本地下载数据集
- 获取用户订阅申请状态
- 自动订阅数据集
- 查询自动订阅的数据集的下载状态
- 批量申请订阅数据集
- 数据集订阅到期续订和确认销毁
- 数据集订阅到期续订
- 重复提交校验
- 订阅付费数据集
- 根据ID订阅付费数据集
- 数据集下载接口
- 计量统计接口
- 用户信息管理接口
- 通知接口
- 标签接口
- 数据集评论接口
- 网图服务数据集查询接口
- 数据集备份恢复接口
- 数据资产账本接口
-
数据接入
- 管理软件包
- 管理采集机(运维)
- 管理采集机(用户)
-
管理采集任务
- 创建采集任务(数据准备,含机机接口)
- 创建采集任务
- 创建采集任务(控制节点,含机机接口)
- 编辑采集任务(数据节点,console页面)
- 启动采集任务(数据准备,含机机接口)
- 启动采集任务(控制节点,含机机接口)
- 启动采集任务(数据节点,console页面)
- 停止采集任务(数据准备,含机机接口)
- 停止采集任务(控制节点,含机机接口)
- 停止采集任务(数据节点console页面)
- 删除采集任务(数据准备,含机机接口)
- 删除采集任务(控制节点,含机机接口)
- 删除采集任务(数据节点,console页面)
- 连通性测试(数据准备,含机机接口)
- 连通性测试(数据准备,控制节点,含机机接口)
- 连通性测试(console,数据节点)
- 连通性测试(console,控制节点)
- 判断VPN是否打通
- 发送邮件
- 查询采集任务列表
- 采集任务发布数据集
- 查询采集任务详情
- 更新采集任务(数据节点)
- 查询采集任务状态列表
- 获取任务采集批次信息
- 获取任务批次采集信息
- 查询采集任务日志
- 删除采集文件记录
- 根据标签查询采集任务(数据准备)
- 查询采集任务状态(数据准备)
- 查询项目OBS信息(数据准备)
- 项目ID与采集任务ID关联(数据准备)
- 项目ID与采集任务ID取消关联(数据准备)
- 下载采集数据记录
- 查询kafkatopic信息
- 上传kafka证书
- 查询国家或者城市编码
- 根据协议类型获取协议类别列表
- 根据协议和采集机ID获取对应的探针包信息
- 根据采集机ID获取所有探针包信息
- 获取探针自定义参数
- 管理本地上传任务
- 数据接入备份恢复
- 采集机相关接口(机机接口)
- 订购数据服务相关接口
- 管理用户信息
- 施工数据相关接口
- 网图服务相关接口
- 数据解析
- 数据备份
- 数据恢复
- 数据准备
- 公共参数
- 修订记录
- 常见问题
- 产品术语
-
数据集服务
- 文档导读
- 产品介绍
- 快速入门
- 用户指南
-
API参考
- 使用前必读
- 接口简介
- 环境准备
- 接口使用方法
- 数据集服务订购接口
- 数据集发布接口
- 目录管理接口
- 数据集管理接口
- 数据集可视授权接口
-
订阅和审批接口
- 查询数据集订阅类型
- 申请订阅单个数据集
- 查询已经订阅的数据集
- 将需要订阅的数据集加入购物车
- 删除加入购物车的内容
- 查询加入购物车的内容
- 申请人员查看申请信息
- 查看具体的申请内容
- 添加审批人员信息
- 查看审批人员信息
- 删除审批人员信息
- 审批人员查看待审批或者已经审批的申请信息
- 审批人员审批申请信息
- 查询订购用户信息
- 查询用户订阅并下载成功的数据集信息
- 根据数据集ID查询用户订阅成功数据集详情信息
- 查看给定数据集的订阅情况
- 撤销未审批完成的订单
- 获取用户订阅申请状态
- 自动订阅数据集
- 查询自动订阅的数据集的下载状态
- 批量申请订阅数据集
- 数据集订阅到期续订和确认销毁
- 数据集订阅到期续订
- 重复提交校验
- 订阅付费数据集
- 根据ID订阅付费数据集
- 数据集下载接口
- 计量统计接口
- 用户信息管理接口
- 通知接口
- 标签接口
- 数据集评论接口
- 网图服务数据集查询接口
- 数据集服务备份恢复接口
- 数据资产账本接口
- 公共参数
- 修订记录
- 常见问题
- 产品术语
- 数据生成服务
- 模型训练服务
- 文档下载
- 通用参考
本文导读
展开导读

链接复制成功!
模型训练
硬盘故障检测模板会预置模型训练工程,无需关注,下面会提供端到端的操作流程,帮助用户快速熟悉模型训练界面操作。
- 单击菜单栏中的“模型训练”,进入模型训练首页。
可以看到预置的“hardisk_detect”模型训练工程,这是硬盘故障检测模板预置的模型训练工程,本次不使用。
- 单击界面右上角的“创建”,弹出“创建训练”对话框。
参数配置说明,如下所示,其余参数保持默认值即可。
- 请选择模型训练方式:保持默认值“新建模型训练工程”。
- 模型训练名称:请根据实际情况设置。示例:harddisk。
- 开发环境:选择“简易编辑器”。
- 单击“确定”。
进入模型训练工程详情界面。
- 单击界面右上角的
 图标,进入代码编辑界面。
图标,进入代码编辑界面。 - 界面左侧的
 图标,查看代码目录。
图标,查看代码目录。
可根据实际情况,在代码目录下添加代码文件。单击代码文件,编辑代码。
以下代码目录及文件,皆参考硬盘故障检测模板中的模型训练工程创建。此处旨在介绍操作方法,用户请按实际情况创建。- 在界面左侧目录,选中根节点“harddisk”,单击
 图标。在弹出的“新建文件”对话框中,输入文件名称“hardisk_predict.py”。
图标。在弹出的“新建文件”对话框中,输入文件名称“hardisk_predict.py”。 - 将预置模型训练工程“hardisk_detect_predict.py”中的文件代码,拷贝至新建的“hardisk_predict.py”文件中,并按“Ctrl+S”保存。
- 在界面左侧目录,选中根节点“harddisk”,单击上方的
 图标,在根目录下创建目录“hardisk”。
图标,在根目录下创建目录“hardisk”。 - 选中新建目录“hardisk”,单击上方的
 图标,分别创建代码文件“preprocess.py”和“train.py”。
图标,分别创建代码文件“preprocess.py”和“train.py”。 - 将预置模型训练工程“hardisk_detect”中同名文件“preprocess.py”和“train.py”的代码,分别拷贝至新建文件“preprocess.py”和“train.py”中,并按“Ctrl+S”保存。
- 单击与训练工程同名的“.py”主入口文件,并清空文件内容。将预置模型训练工程“hardisk_detect”中的“hardisk_detect.py”文件代码拷贝进当前主入口文件,并按“Ctrl+S”保存。
- 在界面左侧目录,选中根节点“harddisk”,单击
- 单击界面左侧的
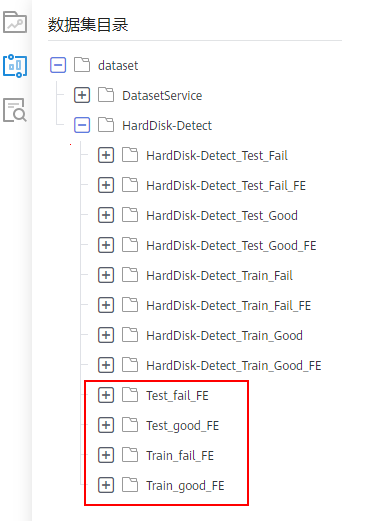
 图标,查看数据集目录,如图1所示。
图标,查看数据集目录,如图1所示。
HardDisk-Detect节点下面会展示预置的四份数据集和经过特征处理后生成的四份新数据集。
 说明:
说明:
当前数据集目录中展示的数据实例数量比数据集菜单页面多,属于正常,无需关注。
- 单击“训练”,进入“训练任务配置”界面,配置训练任务,配置效果如图2所示。
参数配置说明,如下所示,其余参数保持默认值即可。
- AI引擎:AI算法运行平台。从第一个下拉框中选择AI引擎“TensorFlow”,从第二个下拉框中选择匹配的python语言版本“TF-1.8.0-python3.6”。
- 计算节点规格:模型训练的资源配置信息。
- 计算节点个数:是否进行分布式训练,请设置为“1”,即不进行分布式训练。
- 数据集超参:每行一个超参,单击超参行右侧的“增加”图标,新增2个超参。共需要设置3个数据集超参,标签列均为“failure”,如下所示:
- train_good_data:设置为无故障硬盘训练数据集,经过特征处理后生成的数据集,对应数据集实例“Train_good_FE”。
- test_good_data:设置为无故障硬盘测试数据集,经过特征处理后生成的数据集,对应数据集实例“Test_good_FE”。
- train_failure_data:设置为故障硬盘训练数据集,经过特征处理后生成的数据集,对应数据集实例“Train_fail_FE”。
- 运行超参:模型参数是模型内部的配置变量,参数值可以根据数据自动估算。参数是机器学习的关键,通常从过去的训练数据中总结得出。超参区别于参数,是模型外部的配置,必须手工设置和调整,可用于帮助估算模型参数值。请勾选“超参优化”,第一列设置超参名称,第二列设置超参类型。第三列和第四列,分别设置为超参取值范围的下限和上限。
- n_estimators:勾选“超参优化”,INT类型,依次输入“10”和“500”。
- min_samples_split:勾选“超参优化”,INT类型,依次输入“2”和“20”。
- max_features:勾选“超参优化”,FLOAT类型,依次输入“0”和“1”。
- 优化方法:选择优化方法“贝叶斯优化 - GP”和优化目标“最大值”。
- 终止条件:配置超参优化终止的条件。设置“迭代次数”为“10”,即使用“贝叶斯优化 - GP”算法,选取十个超参组合,依次进行模型训练。
- 单击“开始训练”,回到代码编辑界面。
可通过单击界面右上角的“训练任务”,查看训练任务状态。如图3所示。
模型训练结束后,单击训练任务下方的
 图标,可查看10个超参组合对应的10个模型训练评估结果,如图4所示。
图标,可查看10个超参组合对应的10个模型训练评估结果,如图4所示。- “评分”页签分别展示了10个模型训练任务的评分。
- “超参”页签分别展示了10个超参组合的取值。
- “试验时长”页签分别展示了10个超参组合对应的模型训练时长。
- “详情”页签分别展示了10个超参组合的迭代信息、耗时、评估值、超参取值,并支持对每个超参组合重新加入训练。
- 在评分页签内选取一个评分最高的模型任务数据,记录其三个超参值。参考7~8,配置最优模型的训练任务并进行训练。
说明:
对评分最高的模型再创建训练任务是为了在训练结束后,打包该最优模型包。模型训练任务在进行“超参配置”时,去勾选“超参优化”,三个超参值分别配置为此前记录的最优模型的三个对应超参值。
- 单击菜单栏的“模型训练”。
进入模型训练界面。
- 单击模型训练任务所在行。
进入模型训练任务详情界面。
- 在“模型训练任务”下面,单击最优模型训练任务右侧的
 图标。
图标。
弹出“归档”对话框,如图5所示。参数说明如下所示,其余参数保持默认值即可。
- 归档名:归档模型包名称。示例:HardDisk_predict。
- 生成模型包:是否直接在归档的时,打包模型包。选择“是”,表示同时对模型执行归档和打包操作;选择“否”表示仅对模型执行归档操作。默认选择“是”。
- 包含代码:模型包是否包含训练和推理相关代码。选择“是”,表示包含;选择“否”,表示不包含。默认选择“是”。
- 单击“确定”,等待模型打包完成。





父主题: 使用模型训练服务快速训练算法模型




