

文件格式介绍
在创建CDM作业时,有些场景下源端、目的端的作业参数中需要选择“文件格式”,这里分别介绍这几种文件格式的使用场景、子参数、公共参数、使用示例等。
CSV格式
如果想要读取或写入某个CSV文件,请在选择“文件格式”的时候选择“CSV格式”。CSV格式的主要有以下使用场景:
- 文件导入到数据库、NoSQL。
- 数据库、NoSQL导出到文件。
选择了CSV格式后,通常还可以配置以下可选子参数:
- 换行符
用于分隔文件中的行的字符,支持单字符和多字符,也支持特殊字符。特殊字符可以使用URL编码输入,例如:
- 字段分隔符
用于分隔CSV文件中的列的字符,支持单字符和多字符,也支持特殊字符,详见表1。
- 编码类型
文件的编码类型,默认是UTF-8,中文的编码有时会采用GBK。
如果源端指定该参数,则使用指定的编码类型去解析文件;目的端指定该参数,则写入文件的时候,以指定的编码类型写入。
- 使用包围符
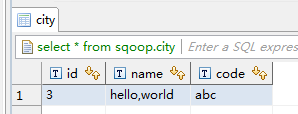
- 数据库、NoSQL导出到CSV文件(“使用包围符”在目的端):当源端某列数据的字符串中出现字段分隔符时,目的端可以通过开启“使用包围符”,将该字符串括起来,作为一个整体写入CSV文件。CDM目前只使用双引号("")作为包围符。如图1所示,数据库的name字段的值中包含了字段分隔符逗号:
不使用包围符的时候,导出的CSV文件,数据会显示为:
3,hello,world,abc
如果使用包围符,导出的数据则为:
3,"hello,world",abc
如果数据库中的数据已经包含了双引号(""),那么使用包围符后,导出的CSV文件的包围符会是三个双引号(""")。例如字段的值为:a"hello,world"c,使用包围符后导出的数据为:
"""a"hello,world"c"""
- CSV文件导出到数据库、NoSQL(“使用包围符”在源端):CSV文件为源端,并且其中数据是被包围符括起来的时候,如果想把数据正确的导入到数据库,就需要在源端开启“使用包围符”,这样包围符内的值的,会写入一个字段内。
- 数据库、NoSQL导出到CSV文件(“使用包围符”在目的端):当源端某列数据的字符串中出现字段分隔符时,目的端可以通过开启“使用包围符”,将该字符串括起来,作为一个整体写入CSV文件。CDM目前只使用双引号("")作为包围符。如图1所示,数据库的name字段的值中包含了字段分隔符逗号:
- 使用正则表达式分隔字段
这个功能是针对一些复杂的半结构化文本,例如日志文件的解析,详见使用正则表达式分隔半结构化文本。
- 首行为标题行
这个参数是针对CSV文件导出到其它地方的场景,如果源端指定了该参数,CDM在抽取数据时将第一行作为标题行。在传输CSV文件的时候会跳过标题行,这时源端抽取的行数,会比目的端写入的行数多一行,并在日志文件中进行说明跳过了标题行。
- 写入文件大小
这个参数是针对数据库导出到CSV文件的场景,如果一张表的数据量比较大,那么导出到CSV文件的时候,会生成一个很大的文件,有时会不方便下载或查看。这时可以在目的端指定该参数,这样会生成多个指定大小的CSV文件,避免导出的文件过大。该参数的数据类型为整型,单位为MB。
JSON格式
- CDM支持解析的JSON类型:JSON对象、JSON数组。
- JSON对象:JSON文件包含单个对象,或者以行分隔/串连的多个对象。
- 单一对象JSON
{ "took" : 190, "timed_out" : false, "total" : 1000001, "max_score" : 1.0 } - 行分隔的JSON对象
{"took" : 188, "timed_out" : false, "total" : 1000003, "max_score" : 1.0 } {"took" : 189, "timed_out" : false, "total" : 1000004, "max_score" : 1.0 } - 串连的JSON对象
{ "took": 190, "timed_out": false, "total": 1000001, "max_score": 1.0 } { "took": 191, "timed_out": false, "total": 1000002, "max_score": 1.0 }
- 单一对象JSON
- JSON数组:JSON文件是包含多个JSON对象的数组。
[{ "took" : 190, "timed_out" : false, "total" : 1000001, "max_score" : 1.0 }, { "took" : 191, "timed_out" : false, "total" : 1000001, "max_score" : 1.0 }]
- JSON对象:JSON文件包含单个对象,或者以行分隔/串连的多个对象。
- 记录节点
记录数据的根节点。该节点对应的数据为JSON数组,CDM会以同一模式从该数组中提取数据。多层嵌套的JSON节点以字符“.”分隔。
- 从JSON文件复制数据
- 示例一 从行分隔/串连的多个对象中提取数据。JSON文件包含了多个JSON对象,例如:
{ "took": 190, "timed_out": false, "total": 1000001, "max_score": 1.0 } { "took": 191, "timed_out": false, "total": 1000002, "max_score": 1.0 } { "took": 192, "timed_out": false, "total": 1000003, "max_score": 1.0 }如果您想要从该JSON对象中提取数据,使用以下格式写入到数据库,只需要在作业第一步指定文件格式为“JSON格式”,指定JSON类型为“JSON对象”,然后在作业第二步进行字段匹配即可。表2 示例 took
timedOut
total
maxScore
190
false
1000001
1.0
191
false
1000002
1.0
192
false
1000003
1.0
- 示例二 从记录节点中提取数据。JSON文件包含了单个的JSON对象,但是其中有效的数据在一个数据节点下,例如:
{ "took": 190, "timed_out": false, "hits": { "total": 1000001, "max_score": 1.0, "hits": [{ "_id": "650612", "_source": { "name": "tom", "books": ["book1","book2","book3"] } }, { "_id": "650616", "_source": { "name": "tom", "books": ["book1","book2","book3"] } }, { "_id": "650618", "_source": { "name": "tom", "books": ["book1","book2","book3"] } }] } }如果想以如下格式写入到数据库,则需要在作业第一步指定文件格式为“JSON格式”,指定JSON类型为“JSON对象”,并且指定记录节点为“hits.hits”,然后在作业第二步进行字段匹配。表3 示例 ID
SourceName
SourceBooks
650612
tom
["book1","book2","book3"]
650616
tom
["book1","book2","book3"]
650618
tom
["book1","book2","book3"]
- 示例三 从JSON数组中提取数据。JSON文件是包含了多个JSON对象的JSON数组,例如:
[{ "took" : 190, "timed_out" : false, "total" : 1000001, "max_score" : 1.0 }, { "took" : 191, "timed_out" : false, "total" : 1000002, "max_score" : 1.0 }]如果想以如下格式写入到数据库,需要在作业第一步指定文件格式为“JSON格式”,指定JSON类型为“JSON数组”,然后在作业第二步进行字段匹配。
表4 示例 took
timedOut
total
maxScore
190
false
1000001
1.0
191
false
1000002
1.0
- 示例四 在解析JSON文件的时候搭配转换器。在示例二前提下,想要把hits.max_score字段附加到所有记录中,即以如下格式写入到数据库中:
表5 示例 ID
SourceName
SourceBooks
MaxScore
650612
tom
["book1","book2","book3"]
1.0
650616
tom
["book1","book2","book3"]
1.0
650618
tom
["book1","book2","book3"]
1.0
则需要在作业第一步指定文件格式为“JSON格式”,指定JSON类型为“JSON对象”,并且指定记录节点为“hits.hits”,然后在作业第二步添加转换器,操作步骤如下:- 单击
 添加字段,新增一个字段。 图2 添加字段
添加字段,新增一个字段。 图2 添加字段
- 在添加的新字段后面,单击
 添加字段转换器。 图3 添加字段转换器
添加字段转换器。 图3 添加字段转换器
- 创建“表达式转换”的转换器,表达式输入“1.0”,然后保存。 图4 配置字段转换器

- 单击
- 示例一
二进制格式
如果想要在文件系统间按原样复制文件,则可以选择二进制格式。二进制格式传输文件到文件的速率高、性能稳定,且不需要在作业第二步进行字段匹配。
- 文件传输的目录结构
CDM的文件传输,支持单文件,也支持一次传输目录下所有的文件。传输到目的端后,目录结构会保持原样。
- 增量迁移文件
使用CDM进行二进制传输文件时,目的端有一个参数“重复文件处理方式”,可以用作文件的增量迁移,具体请参见文件增量迁移。
增量迁移文件的时候,选择“重复文件处理方式”为“跳过重复文件”,这样如果源端有新增的文件,或者是迁移过程中出现了失败,只需要再次运行任务,已经迁移过的文件就不会再次迁移。
- 写入到临时文件
二进制迁移文件时候,可以在目的端指定是否写入到临时文件。如果指定了该参数,在文件复制过程中,会将文件先写入到一个临时文件中,迁移成功后,再进行rename或move操作,在目的端恢复文件。
- 生成文件MD5值
对每个传输的文件都生成一个MD5值,并将该值记录在一个新文件中,新文件以“.md5”作为后缀,并且可以指定MD5值生成的目录。
文件格式的公共参数
- 启动作业标识文件
这个主要用于自动化场景中,CDM配置了定时任务,周期去读取源端文件,但此时源端的文件正在生成中,CDM此时读取会造成重复写入或者是读取失败。所以,可以在源端作业参数中指定启动作业标识文件为“ok.txt”,在源端生成文件成功后,再在文件目录下生成“ok.txt”,这样CDM就能读取到完整的文件。
另外,可以设置超时时间,在超时时间内,CDM会周期去查询标识文件是否存在,超时后标识文件还不存在的话,则作业任务失败。
启动作业标识文件本身不会被迁移。
- 作业成功标识文件
文件系统为目的端的时候,当任务成功时,在目的端的目录下,生成一个空的文件,标识文件名由用户来指定。一般和“启动作业标识文件”搭配使用。
这里需要注意的是,不要和传输的文件混淆,例如传输文件为“finish.txt”,但如果作业成功标识文件也设置为“finish.txt”,这样会造成这两个文件相互覆盖。
- 过滤器
使用CDM迁移文件的时候,可以使用过滤器来过滤文件。支持通过通配符或时间过滤器来过滤文件。
- 选择通配符时,CDM只迁移满足过滤条件的目录或文件。
- 选择时间过滤器时,只有文件的修改时间晚于输入的时间才会被传输。
例如用户的“/table/”目录下存储了很多数据表的目录,并且按天进行了划分DRIVING_BEHAVIOR_20180101~DRIVING_BEHAVIOR_20180630,保存了DRIVING_BEHAVIOR从1月到6月的所有数据。如果只想迁移DRIVING_BEHAVIOR的3月份的表数据,那么需要在作业第一步指定源目录为“/table”,过滤类型选择“通配符”,然后指定“路径过滤器”为“DRIVING_BEHAVIOR_201803*”。
文件格式问题解决方法
- 数据库的数据导出到CSV文件,由于数据中含有分隔符逗号,造成导出的CSV文件中数据混乱。
- 指定字段分隔符
使用数据库中不存在的字符,或者是极少见的不可打印字符来作为字段分隔符。例如可以在目的端指定“字段分隔符”为“%01”,这样导出的字段分隔符就是“\u0001”,详情可见表1。
- 使用包围符
在目的端作业参数中开启“使用包围符”,这样数据库中如果字段包含了字段分隔符,在导出到CSV文件的时候,CDM会使用包围符将该字段括起来,使之作为一个字段的值写入CSV文件。
- 指定字段分隔符
- 数据库的数据包含换行符




