

功能总览
-
MapReduce服务
OBS 2.0支持
-
大数据是人类进入互联网时代以来面临的一个巨大问题:社会生产生活产生的数据量越来越大,数据种类越来越多,数据产生的速度越来越快。传统的数据处理技术,比如说单机存储,关系数据库已经无法解决这些新的大数据问题。为解决以上大数据处理问题,Apache基金会推出了Hadoop大数据处理的开源解决方案。Hadoop是一个开源分布式计算平台,可以充分利用集群的计算和存储能力,完成海量数据的处理。企业自行部署Hadoop系统有成本高,周期长,难运维和不灵活等问题。
针对上述问题,华为云提供了大数据MapReduce服务(MRS),MRS是一个在华为云上部署和管理Hadoop系统的服务,一键即可部署Hadoop集群。MRS提供租户完全可控的一站式企业级大数据集群云服务,完全兼容开源接口,结合华为云计算、存储优势及大数据行业经验,为客户提供高性能、低成本、灵活易用的全栈大数据平台,轻松运行Hadoop、Spark、HBase、Kafka等大数据组件,并具备在后续根据业务需要进行定制开发的能力,帮助企业快速构建海量数据信息处理系统,并通过对海量信息数据实时与非实时的分析挖掘,发现全新价值点和企业商机。
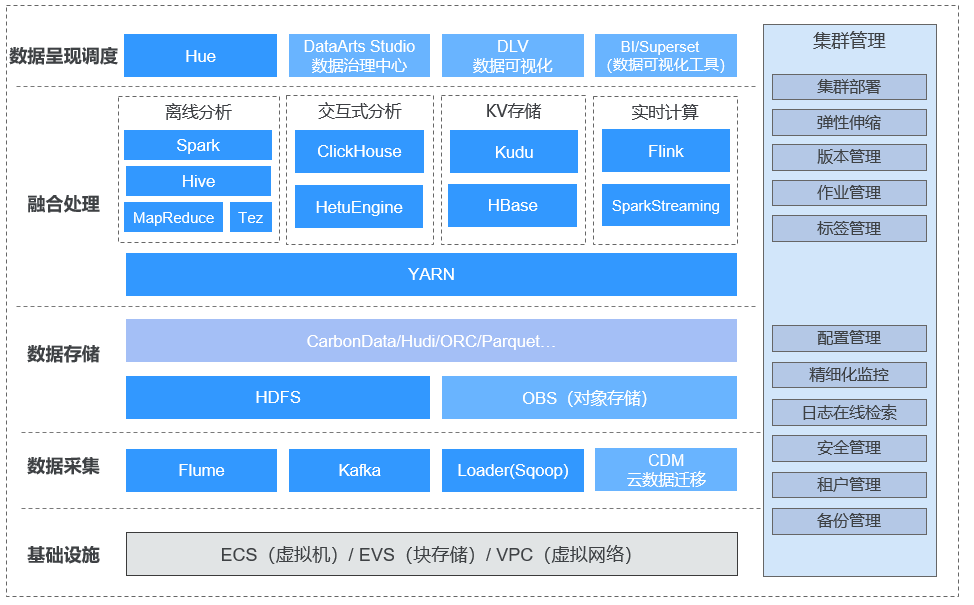

发布区域:全部。
-
-
集群管理
-
购买集群
-
扩容集群
-
MRS的扩容不论在存储还是计算能力上,都可以简单地通过增加Core节点或者Task节点来完成,不需要修改系统架构,降低运维成本。集群Core节点不仅可以处理数据,也可以存储数据。可以在集群中添加Core节点,通过增加节点数量处理峰值负载。集群Task节点主要用于处理数据,不存放持久数据。集群扩容后无需更新客户端。
-
-
缩容集群
-
用户可以根据业务需求量,通过简单的缩减Core节点或者Task节点,对集群进行缩容,以使MRS拥有更优的存储、计算能力,降低运维成本。
目前支持缩容Core节点和Task节点,不支持缩容Master节点。对集群进行缩容时,只需要在界面调整节点个数,MRS会自动选择缩容节点,完成缩容任务。
-
-
退订包周期集群指定节点
-
用户可以根据业务需求量,通过指定节点对集群进行缩容,以使MRS拥有更优的存储、计算能力,降低运维成本。
使用限制:
1. 当集群中分析Core节点个数小于等于HDFS副本数时,为了保证数据的可靠性MRS不支持退订节点。HDFS副本数可通过“组件管理 > HDFS > 服务配置 > 全部配置”中的“dfs.replication”参数查询。
2. MRS不支持退订部署了ZooKeeper服务的节点。
-
-
Task节点弹性伸缩
-
在大数据应用,尤其是实时分析处理数据的场景中,常常需要根据数据量的变化动态调整集群节点数量以增减资源。MRS的弹性伸缩规则功能支持根据集群负载对集群进行弹性伸缩。此外,如果数据量以天为周期有规律的变化,并且希望在数据量变化前提前完成集群的扩缩容,可以使用MRS的资源计划(按时间段设置Task节点数量范围)特性。
-
-
Master规格升级
-
随着用户业务的增长,Core节点的扩容,CPU使用率变高,而Master节点规格已经不满足用户需求时,则需要升级Master节点规格。
-
-
创建自定义拓扑集群
-
MRS当前提供的“分析集群”、“流式集群”和“混合集群”采用固定模板进行部署集群的进程,无法满足用户自定义部署管理角色和控制角色在集群节点中的需求。如需自定义集群部署方式,可在创建集群时的“集群类型”选择“自定义”,实现用户自主定义集群的进程实例在集群节点中的部署方式。自定义集群可实现以下功能:
管控分离部署,管理角色和控制角色分别部署在不同的Master节点中。
管控合设部署,管理角色和控制角色共同部署在Master节点中。
ZooKeeper单独节点部署,增加可靠性。
组件分开部署,避免资源争抢。
-
-
-
文件管理
-
用户通过“文件管理”页面可以在分析集群进行文件夹创建、删除,文件导入、导出、删除操作,暂不支持文件创建功能。
导入:MRS目前只支持将OBS上的数据导入至HDFS中。上传文件速率会随着文件大小的增大而变慢,适合数据量小的场景下使用。
导出:数据完成处理和分析后,您可以将数据存储在HDFS中,也可以将集群中的数据导出至OBS系统。
-
-
作业管理
MRS作业是MRS为用户提供的程序执行平台,用于处理和分析用户数据。作业创建完成后,所有的作业列表信息展示在“作业管理”页面中,您可以查看所有的作业列表,也可以创建和管理作业。
-
提交Flink作业
-
Flink提供一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态计算。Flink作业用于提交jar程序处理流式数据。
-
-
提交MapReduce作业
-
MapReduce提供快速并行处理大量数据的能力,是一种分布式数据处理模式和执行环境。MapReduce作业用于提交jar程序快速并行处理大量数据。
-
-
提交Hive作业
-
Hive是建立在Hadoop基础上的开源的数据仓库。HiveSql作业用于提交SQL语句和SQL脚本文件查询和分析数据,包括SQL语句和Script脚本两种形式,如果SQL语句涉及敏感信息,请使用Script提交。
-
-
提交Spark作业
-
Spark基于内存进行计算的分布式计算框架。Spark支持提交Spark Jar和Spark python程序,执行Spark application,计算和处理用户数据。
-
-
提交SparkSQL作业
-
Spark基于内存进行计算的分布式计算框架。SparkSQL作业用于查询和分析数据,包括SQL语句和Script脚本两种形式,如果SQL语句涉及敏感信息,请使用Spark Script提交。
-
-
-
运维管理
-
MRS提供的集群的资源是完全属于用户的,MRS提供多种方式帮助用户维护集群的正常运行。
-
登录集群
-
在创建集群时,MRS支持指定使用密钥或密码的方式登录ECS后台。
登录MRS集群中的节点支持远程登录(VNC方式)和使用密钥或密码方式(SSH方式),远程登录主要用于紧急运维场景,远程登录弹性云服务器进行相关维护操作。其他场景下,建议用户采用SSH方式登录。
-
-
确认MRS Manager的主备管理节点
-
登录Master节点后,可以确认MRS Manager的主备管理节点,并在对应的管理节点中执行命令。
在主备模式下,由于Master1和Master2之间会切换,Master1节点不一定是MRS Manager的主管理节点。
-
-
Manager管理
-
MRS为用户提供海量数据的管理及分析功能,快速从结构化和非结构化的海量数据中挖掘您所需要的价值数据。开源组件结构复杂,安装、配置、管理过程费时费力,Manager提供了企业级的大数据集群的统一管理平台:
提供集群状态的监控功能,您能快速掌握服务及主机的健康状态。
提供图形化的指标监控及定制,您能及时的获取系统的关键信息。
提供服务属性的配置功能,满足您实际业务的性能需求。
提供集群、服务、角色实例的操作功能,满足您一键启停等操作需求。
-
-
EIP方式访问集群
-
通过EIP访问快速便捷地访问Manager,及开源组件Web站点。
-
-
消息通知
-
配置消息通知后,可以实时给用户发送MRS集群健康状态,用户可以通过手机短信或邮箱实时接收到MRS集群变更及组件告警信息。MRS可以帮助用户轻松运维,实时监控,实时发送告警,操作灵活,大数据业务部署更加省心省力。
-
-
告警管理
-
MRS可以实时监控大数据集群,通过告警和事件可以识别系统健康状态。同时MRS也支持用户自定义配置监控与告警阈值用于关注各指标的健康情况,当监控数据达到告警阈值,系统将会触发一条告警信息。
-
-
滚动重启服务
-
在修改了大数据组件的配置项后,需要重启对应的服务来使得配置生效,使用普通重启方式会并发重启所有服务或实例,可能引起业务断服。为了确保服务重启过程中,尽量减少或者不影响业务运行,可以通过滚动重启来按批次重启服务或实例(对于有主备状态的实例,会先重启备实例,再重启主实例)。滚动重启方式的重启时间比普通重启时间久。
-
-
滚动安装补丁
-
滚动补丁是指在补丁安装/卸载时,采用滚动重启服务(按批次重启服务或实例)的方式,在不中断或尽可能短地中断集群各个服务业务的前提下完成对集群中单个或多个服务的补丁安装/卸载操作。
-
-
BootStrap自定义引导操作
-
引导操作是指启动集群组件前(或后)在指定的节点上执行脚本。您可以通过引导操作来完成安装其他第三方软件,修改集群运行环境等自定义操作。
如果集群扩容,选择执行引导操作,则引导操作也会以相同方式在新增节点上执行。如果集群开启弹性伸缩功能,可以在配置资源计划的同时添加自动化脚本,则自动化脚本会在弹性伸缩的节点上执行,实现用户自定义操作。
-
-
运维授权
-
当用户使用集群过程中出现问题需要华为云支持人员协助解决时,用户可通过“运维授权”功能授权华为云支持人员访问用户机器的权限用于定位问题。
-
-
-
运营管理
-
MRS的计费简单、易于预测,并在控制台购买界面中提供价格计算器功能帮助您计算好了整个MRS集群的价格,您可一键完成整个配置的购买。已经购买的集群提供标签管理、审计管理等功能帮助您更好地进行集群管理。
-
集群计费
-
MRS(MapReduce服务)的计费简单、易于预测,MRS当前支持灵活的按需计费和更经济的包年包月两种模式。为了便于您便捷的下单购买,系统在控制台购买界面中已经为您计算好了整个MRS集群的价格,您可一键完成整个配置的购买。
-
-
退订/删除集群
-
企业多项目管理
-
企业项目是一种云资源管理方式。企业管理提供面向企业客户的云上资源管理、人员管理、权限管理、财务管理等综合管理服务。区别于管理控制台独立操控、配置云产品的方式,企业管理控制台以面向企业资源管理为出发点,帮助企业以公司、部门、项目等分级管理方式实现企业云上的人员、资源、权限、财务的管理。
-
-
标签管理
-
标签是集群的标识,为集群添加标签,可以方便用户识别和管理拥有的集群资源。MRS服务通过与标签管理服务(TMS)关联,可以让拥有大量云资源的用户,通过给云资源打标签,快速查找具有同一标签属性的云资源,进行统一检视、修改、删除等管理操作,方便用户对大数据集群及其他相关云资源的统一管理。
您可以在创建集群时添加标签,也可以在集群创建完成后,在集群的详情页添加标签,您最多可以给集群添加10个标签。
-
-
审计管理
-
记录MRS Manager上所有操作,用于安全事件中事后追溯、定位问题原因及划分事故责任。
-
-
-
用户权限管理
-
MRS通过对接IAM服务,帮助您对企业中的员工设置不同的访问权限,以达到不同员工之间的权限隔离。
-
IAM权限管理
-
通过IAM,您可以在华为云账号中给员工创建IAM用户,并授权控制其对华为云资源的访问范围。
例如员工中有负责软件开发的人员,需要具有MRS服务的使用权限,但是不能拥有删除MRS集群等高危操作的权限,那么可以使用IAM为开发人员创建用户,通过授予仅能使用MRS,但是不允许删除MRS集群的权限策略,控制MRS集群资源的使用范围。
-
-
IAM用户同步
-
MRS支持将绑定MRS相关策略的IAM用户同步至MRS系统中,创建同用户名、不同密码的账号,用于集群管理。同步之后,用户可以使用IAM用户名(密码需要MRS Manager的管理员admin重置后方可使用)登录MRS Manager管理集群。
-
-
OBS权限映射
-
用户通过该功能配置访问OBS权限,实现MRS用户对OBS桶下的目录权限控制。
例如,您只允许用户组A访问某一OBS桶中的日志文件,您可以执行以下操作来实现:
为MRS集群配置OBS访问权限的委托,实现使用ECS自动获取的临时AK/SK访问OBS。避免了AK/SK直接暴露在配置文件中的风险。
在IAM中创建一个只允许访问某一OBS桶中的日志文件的策略,并创建一个绑定该策略权限的委托。
在MRS集群中,新建的委托与MRS集群中的用户组A进行绑定,即可实现用户组A只拥有访问某一OBS桶中的日志文件的权限。
-
-
-
存算分离
-
存算分离集群配置
-
MRS支持通过IAM服务的“委托”机制进行简单配置, 实现使用ECS自动获取的临时AK/SK访问OBS。避免了AK/SK直接暴露在配置文件中的风险。
MRS也支持通过在配置文件中添加AKSK的方式使用obs://对接OBS文件系统,修改配置后无需在每次执行任务时手动添加AK/SK、endpoint就可以直接访问OBS上的数据。
-
-
外置元数据连接
-
MRS的支持组件使用外部数据源存储数据,如Hive的元数据使用外部的关系型数据库(RDS),可以通过数据连接来关联Hive组件实现。
-
-
HDFS地址映射方式访问OBS
-
通过HDFS地址映射到OBS地址的方式,支持将HDFS中的数据迁移到OBS后,不需要变动业务逻辑中的数据地址,即可完成数据访问。
例如将HDFS文件系统的数据迁移到OBS服务中,通过使用HDFS地址映射功能简单配置即可实现客户端无需修改自己的的业务代码逻辑的情况下,访问存储到OBS的数据。或将元数据信息从HDFS文件系统部分迁移到OBS服务中,通过使用HDFS地址映射功能简单配置即可实现既能访问存储在OBS的数据也能访问存储在HDFS文件系统的数据。
该功能不支持使用WebHdfsFileSystem (A FileSystem for HDFS over the web.)的rest api访问的场景。
-
-
-
CDL组件
-
ClickHouse组件
-
ClickHouse是面向联机分析处理的列式数据库,支持SQL查询,且查询性能好,特别是基于大宽表的聚合分析查询性能非常优异,比其他分析型数据库速度快一个数量级。
-
-
DBService组件
-
DBService是一个具备高可靠性的传统关系型数据库,为Hive、Hue、Oozie、Loader、Metadata和Redis组件提供元数据存储服务。
-
-
Doris组件
-
Doris是一款简单易用、高性能、实时的分析型数据库,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。
-
-
Flink组件
-
Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎。
Flink最适合的应用场景是低时延的数据处理(Data Processing)场景:高并发pipeline处理数据,时延毫秒级,且兼具可靠性。
-
-
Flume组件
-
Flume是一个高可用、高可靠,分布式的海量日志采集、聚合和传输的系统。Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
-
-
HBase组件
-
数据存储使用HBase来承接,HBase是一个开源的、面向列(Column-Oriented)、适合存储海量非结构化数据或半结构化数据的、具备高可靠性、高性能、可灵活扩展伸缩的、支持实时数据读写的分布式存储系统。
存储在HBase中的表的典型特征:
- 大表(BigTable):一个表可以有上亿行,上百万列
- 面向列:面向列(族)的存储、检索与权限控制
- 稀疏:表中为空(null)的列不占用存储空间
MRS服务的HBase组件支持计算存储分离,数据可以存储在低成本的云存储服务中,包含对象存储服务,并支持跨AZ数据备份。并且MRS服务支持HBase组件的二级索引,支持为列值添加索引,提供使用原生的HBase接口的高性能基于列过滤查询的能力。
-
-
HDFS组件
-
HDFS是Hadoop的分布式文件系统(Hadoop Distributed File System),实现大规模数据可靠的分布式读写。HDFS针对的使用场景是数据读写具有“一次写,多次读”的特征,而数据“写”操作是顺序写,也就是在文件创建时的写入或者在现有文件之后的添加操作。HDFS保证一个文件在一个时刻只被一个调用者执行写操作,而可以被多个调用者执行读操作。
-
-
Hive组件
-
Hive是建立在Hadoop上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive定义了简单的类SQL查询语言,称为HiveQL,它允许熟悉SQL的用户查询数据。Hive的数据计算依赖于MapReduce、Spark、Tez。
-
-
Hue组件
-
Hudi组件
-
Hudi是一种数据湖的存储格式,在Hadoop文件系统之上提供了更新数据和删除数据的能力以及消费变化数据的能力。支持多种计算引擎,提供IUD接口,在HDFS的数据集上提供了插入更新和增量拉取的流原语。
-
-
Impala组件
-
Impala直接对存储在HDFS,HBase 或对象存储服务(OBS)中的Hadoop数据提供快速,交互式SQL查询。除了使用相同的统一存储平台之外,Impala还使用与Apache Hive相同的元数据,SQL语法(Hive SQL),ODBC驱动程序和用户界面(Hue中的Impala查询UI)。这为实时或面向批处理的查询提供了一个熟悉且统一的平台。作为查询大数据的工具的补充,Impala不会替代基于MapReduce构建的批处理框架,例如Hive。基于MapReduce构建的Hive和其他框架最适合长时间运行的批处理作业。
-
-
Kafka组件
-
Kafka是一个分布式的、分区的、多副本的消息发布-订阅系统,它提供了类似于JMS的特性,但在设计上完全不同,它具有消息持久化、高吞吐、分布式、多客户端支持、实时等特性,适用于离线和在线的消息消费,如常规的消息收集、网站活性跟踪、聚合统计系统运营数据(监控数据)、日志收集等大量数据的互联网服务的数据收集场景。
-
-
Kudu组件
-
Kudu是专为Apache Hadoop平台开发的列式存储管理器,具有Hadoop生态系统应用程序的共同技术特性:在通用的商用硬件上运行,可水平扩展,提供高可用性。
-
-
Loader组件
-
Loader是在开源Sqoop组件的基础上进行了一些扩展,实现MRS与关系型数据库、文件系统之间交换“数据”、“文件”,同时也可以将数据从关系型数据库或者文件服务器导入到MRS的HDFS/HBase中,或者反过来从HDFS/HBase导出到关系型数据库或者文件服务器中。
-
-
MapReduce组件
-
MapReduce是Hadoop的核心,是Google提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算。
概念“Map(映射)”和“Reduce(化简)”都是从函数式编程语言借来的,还有从矢量编程语言借来的特性。
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(化简)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
-
-
Oozie组件
-
Oozie是一个基于工作流引擎的开源框架,提供了对开源Hadoop组件的任务编排、执行的功能。以Java Web应用程序的形式运行在Java servlet容器(如:Tomcat)中,并使用数据库来存储工作流定义、当前运行的工作流实例(含实例的状态和变量)。
-
-
Presto组件
-
Presto是一个开源的用户交互式分析查询的SQL查询引擎,用于针对各种大小的数据源进行交互式分析查询。其主要应用于海量结构化数据/半结构化数据分析、海量多维数据聚合/报表、ETL、Ad-Hoc查询等场景。
Presto允许查询的数据源包括Hadoop分布式文件系统(HDFS),Hive,HBase,Cassandra,关系数据库甚至专有数据存储。一个Presto查询可以组合不同数据源,执行跨数据源的数据分析。
-
-
Ranger组件
-
Apache Ranger提供一个集中式安全管理框架,并解决授权和审计。它可以对整个Hadoop生态中如HDFS、Hive、HBase、Kafka、Storm等进行细粒度的数据访问控制。用户可以利用Ranger提供的前端WebUI控制台通过配置相关策略来控制用户对这些组件的访问权限 。
Ranger组件当前不支持开启Kerberos认证。
-
-
Spark组件
-
Spark是一个开源的,并行数据处理框架,能够帮助用户简单的开发快速,统一的大数据应用,对数据进行,协处理,流式处理,交互式分析等等。
Spark提供了一个快速的计算,写入,以及交互式查询的框架。相比于Hadoop,Spark拥有明显的性能优势。Spark使用in-memory的计算方式,通过这种方式来避免一个MapReduce工作流中的多个任务对同一个数据集进行计算时的IO瓶颈。Spark利用Scala语言实现,Scala能够使得处理分布式数据集时,能够像处理本地化数据一样。除了交互式的数据分析,Spark还能够支持交互式的数据挖掘,由于Spark是基于内存的计算,很方便处理迭代计算,而数据挖掘的问题通常都是对同一份数据进行迭代计算。除此之外,Spark能够运行于安装Hadoop 2.0 Yarn的集群。之所以Spark能够在保留MapReduce容错性,数据本地化,可扩展性等特性的同时,能够保证性能的高效,并且避免繁忙的磁盘IO,主要原因是因为Spark创建了一种叫做RDD(Resilient Distributed Dataset)的内存抽象结构。
-
-
Tez组件
-
Tez是Apache最新的支持DAG作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升DAG作业的性能。如果Hive项目使用Tez而不是MapReduce作为其数据处理的骨干,那么将会显著提升它们的响应时间,Tez构建在YARN之上,能够不需要做任何改动地运行MR任务。
MRS将Tez作为Hive的默认执行引擎,执行效率远远超过原先的Mapreduce的计算引擎。
-
-
YARN组件
-
为了实现一个Hadoop集群的集群共享、可伸缩性和可靠性,并消除早期MapReduce框架中的JobTracker性能瓶颈,开源社区引入了统一的资源管理框架YARN。
YARN是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的ApplicationMaster(AM)。
-
-
HetuEngine组件
-
HetuEngine是华为自研高性能交互式SQL分析及数据虚拟化引擎。与大数据生态无缝融合,实现海量数据秒级交互式查询;支持跨源跨域统一访问,使能数据湖内、湖间、湖仓一站式SQL融合分析。
-
-
ZooKeeper组件
-
ZooKeeper是一个分布式、高可用性的协调服务。帮助系统避免单点故障,从而建立可靠的应用程序。
-





