
Cross-Region Replication Across Accounts Using OMS
Scenarios
Cross-region replication across accounts is to replicate data from a source bucket in one region of an account to a destination bucket in a different region of another account.
This section describes how to replicate data between buckets across different accounts and regions using the OMS console, OMS APIs, or obsutil.
Replication scope: files, folders, object lists, objects with specified prefix, or specified URL lists
Replication content: object content, metadata (object name, size, last modification time, creator, version number, and user-defined metadata), ACL (supported by obsutil), and storage class
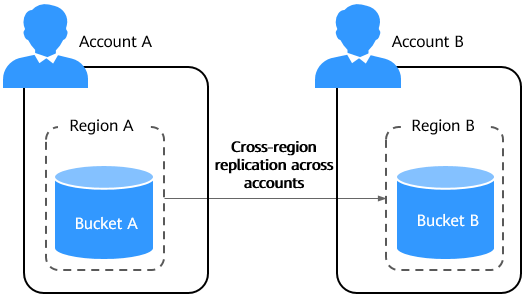
You can use cross-region replication across accounts to meet the following requirements:
- Regulatory compliance
By default, OBS stores data across AZs that are relatively far apart from each other. However, regulatory compliance may require data to be stored at even greater distances. In such cases, you can use cross-region replication to meet compliance requirements.
- Low latency
The same OBS resources may need to be accessed from different locations. To minimize the access latency, you can use cross-region replication to create object copies in the nearest region.
- Data replication
You want to migrate data stored in OBS to the data center in another region.
- Data backup and disaster recovery
For security and availability purposes, you want to create explicit backups for all data written to OBS in the data center of another region to ensure data remains available if there is any damage.
- Easy maintenance
You have compute clusters used to analyze the same group of objects in two different OBS regions and may need to maintain object copies in these two regions.

OBS helps you replicate your service data stored in OBS to a specified region. However, Huawei Cloud does not have visibility into your data and is not responsible for ensuring the legal compliance of your use of OBS. If your replication involves cross-border transfer, ensure that your use complies with relevant laws and regulations.
Constraints
The following table describes the constraints on using Object Storage Migration Service (OMS) to migrate data.
| Item | Description |
|---|---|
| Objects with multiple versions | By default, OMS migrates only the latest version of objects in source buckets. |
| Destination storage class | The destination storage class can be Standard, Infrequent Access, Archive, or Deep Archive. |
| Migration network | Migrations can be performed over the Internet or intranet. Migrations cannot be performed over private lines. |
| Metadata migration | Only Chinese characters, English characters, digits, and hyphens (-) can be migrated. Any other characters cannot be migrated. Chinese punctuation marks cannot be URL-encoded during the migration. If metadata contains Chinese punctuation marks, migrating the metadata and the corresponding object will fail.
|
| Migration scope | A single migration task or migration task group can only migrate data of one bucket. If data of multiple buckets needs to be migrated, you need to create multiple tasks or task groups. |
| Symbolic links | Symbolic link files cannot be migrated. Symbolic link files will be recorded as failed, and the migration task will also be marked as failed. Other files can be migrated normally. If the source contains symbolic links, enter the actual file paths. |
| Migration of object ACLs | OMS cannot migrate object ACLs. |
| Migration speed | Generally, OMS can migrate 10 TB to 20 TB of data per day. For higher migration efficiency, you are advised to use storage migration workflows on MgC. MgC allows you to migrate data using dedicated, scalable migration clusters and up to 20 Gbit/s of bandwidth. However, the speed depends on the number and size of source objects, bandwidth, and transmission distance over the Internet between the source and destination buckets. You are advised to create a migration task to test the migration speed. The maximum migration speed is five times the average speed of a single task because up to five tasks can be executed concurrently in a region by default. If you need more concurrent tasks, you can create a storage migration workflow on MgC to define a number. |
| Archived data | You need to restore archived data before the migration. Note that when there is archived data to be migrated, you need to:
|
| Migration tasks | A maximum of five concurrent migration tasks is allowed for your account per region. NOTE: If your destination regions are CN North-Beijing1 and CN South-Guangzhou, you can run up to 10 migration tasks concurrently. |
| A maximum of 1,000,000 migration tasks can be created in a region within 24 hours. | |
| Migration Task Groups | A maximum of five concurrent migration task groups is allowed for your account per region. NOTE: If your destination regions are CN North-Beijing1 and CN South-Guangzhou, you can run up to 10 migration task groups concurrently. |
| Synchronization tasks | Synchronization tasks share quotas with migration tasks and migration task groups, but enjoy a higher priority. A maximum of five concurrent synchronization tasks is allowed. |
| Object list files |
|
| URL list files |
|
| Failed object list files | A maximum of 100,000 failed objects can be recorded in a list file. NOTE: If more than 100,000 objects fail to be migrated in a migration task, you are advised to rectify the fault based on the existing failed object list and perform the migration again. |
Billing for Cross-Region Replication Across Accounts
- When you use the OMS console or APIs to migrate data, OBS APIs of both the source and destination ends are invoked to handle data upload and download. You will be billed for the API requests and data download traffic. For details, see OMS Billing. In addition, you will be billed for storing the objects in the destination bucket. For details, see Storage Costs.
- When you use obsutil to replicate data across regions, you will be billed for requests, traffic, and storage. For details, see Table 2.
Table 2 Billing for data replication across regions Action
Billing Item
Description
Billing Mode
Replicate data across regions
Requests
You are billed for the number of successfully replicated objects. Successfully replicating one object creates a copy request. For details, see Copying Objects.
- For non-multipart objects, replicating an object creates a GET request to the source bucket and a PUT request to the destination bucket; deleting an object from the source bucket creates a DELETE request to the destination bucket.
- For multipart objects, replicating each part creates a GET request to the source bucket and a PUT request to the destination bucket.
For details about how requests are billed, see Requests.
Pay-per-use
Data transfer
Traffic generated when you replicate data from the source bucket to the destination bucket in another region. Billing only applies to the data transferred out of the source bucket.
If objects are encrypted using server-side encryption, the cost of their cross-region replication traffic is calculated based on the length of the plaintext for SSE-KMS and SSE-OBS.
Pay-per-use
Storage space
Space occupied by the replicated objects in the destination bucket
If you have specified another storage class for object copies in the destination bucket, these copies are billed based on the new storage class.
If objects are encrypted using server-side encryption, their storage cost is calculated based on the length of the ciphertext.
Pay-per-use
Resource packages
Synchronize existing objects
Requests
You are billed for the number of existing objects that are successfully replicated to the destination bucket.
Billing applies to the number of objects that are successfully replicated. You are also billed for listing the existing objects.
Pay-per-use
Data transfer
Traffic generated when OBS replicates existing objects to the destination bucket in another region. Billing only applies to the data transferred out of the source bucket.
If historical objects are encrypted using server-side encryption, the cost of their cross-region replication traffic is calculated based on the length of the plaintext for SSE-KMS and SSE-OBS.
Pay-per-use
Storage space
Space occupied by the replicated objects in the destination bucket
If you have specified another storage class for object copies in the destination bucket, these copies are billed based on the new storage class.
If historical objects are encrypted using server-side encryption, their storage cost is calculated based on the length of the ciphertext.
Pay-per-use
Resource packages
Prerequisites
- There is a source bucket in a region of an account.
- There is a destination bucket in a different region of another account. To create a bucket, see Creating a Bucket.
- When obsutil is used to replicate objects across accounts and regions, the version of the source bucket is 3.0 or later, and the source bucket region supports cross-region replication.
Cross-Region Replication Across Accounts
You can use the OMS console or APIs to migrate data across accounts and regions or use obsutil to replicate data across accounts and regions.
OMS does not automatically migrate data. This means that data changes in a source bucket will not be automatically synchronized to the destination bucket. To synchronize the data changes, you must execute a migration task.
Using the OMS Console
You can use the OMS console to migrate data in OBS buckets. For details, see Migration Process.
- If a single bucket has no more than 3 TB of data or has no more than 5 million objects, you can create a migration task to migrate the data in the bucket.
- If a single bucket has more than 3 TB of data or has more than 5 million objects, you can create a migration task group to migrate the data in the bucket.
Using the OBS CLI Tool - obsutil
When using obsutil to replicate objects across regions and accounts, you must enable cross-region replication, which means that the crr parameter is mandatory.
- Do not change the source objects in the OBS bucket when copying a single object or objects in batches. Otherwise, the operation may fail or data may be inconsistent.
- If the storage class of the object to be copied is cold, you must restore the object to be copied first. Otherwise, the copy fails.
- To copy objects, you must have the read permission on the objects to be copied and the write permission on the destination bucket.
- If the client-side cross-region replication function is not enabled, ensure that the source bucket and destination bucket are in the same region.
- If the source bucket is a parallel file system (supporting POSIX), the destination bucket must also be a parallel file system.
Constraints:
- The source and destination paths cannot be the same.
- The source and destination paths cannot be nested during a batch copy.
- If the destination path has the source path as its prefix, recursive copy may occur.
- If the source path has the destination path as its prefix, overwriting may occur.
Command Line Structure
- Windows
- Copying a single object
obsutil cp obs://srcbucket/key obs://dstbucket/[dest] [-dryRun][-u] [-crr] [-vlength] [-vmd5] [-p=1] [-threshold=52428800] [-versionId=xxx] [-acl=xxx] [-sc=xxx] [-meta=aaa:bbb#ccc:ddd] [-ps=auto] [-cpd=xxx] [-fr] [-o=xxx] [-config=xxx] [-e=xxx] [-i=xxx] [-k=xxx] [-t=xxx]
- Copying objects in batches
obsutil cp obs://srcbucket[/key] obs://dstbucket[/dest] -r [-dryRun][-f] [-flat] [-u] [-crr] [-vlength] [-vmd5] [-j=1] [-p=1] [-threshold=52428800] [-acl=xxx] [-sc=xxx] [-meta=aaa:bbb#ccc:ddd] [-ps=auto] [-include=*.xxx] [-exclude=*.xxx] [-timeRange=time1-time2] [-mf] [-o=xxx] [-cpd=xxx] [-config=xxx] [-e=xxx] [-i=xxx] [-k=xxx] [-t=xxx]
- Copying a single object
- macOS or Linux
- Copying a single object
./obsutil cp obs://srcbucket/key obs://dstbucket/[dest] [-dryRun] [-u] [-crr] [-vlength] [-vmd5] [-p=1] [-threshold=52428800] [-versionId=xxx] [-acl=xxx] [-sc=xxx] [-meta=aaa:bbb#ccc:ddd] [-ps=auto] [-cpd=xxx] [-fr] [-o=xxx] [-config=xxx] [-e=xxx] [-i=xxx] [-k=xxx] [-t=xxx]
- Copying objects in batches
./obsutil cp obs://srcbucket[/key] obs://dstbucket[/dest] -r [-dryRun] [-f] [-flat] [-u] [-crr] [-vlength] [-vmd5] [-j=1] [-p=1] [-threshold=52428800] [-acl=xxx] [-sc=xxx] [-meta=aaa:bbb#ccc:ddd] [-ps=auto] [-include=*.xxx] [-exclude=*.xxx] [-timeRange=time1-time2] [-mf] [-o=xxx] [-cpd=xxx] [-config=xxx] [-e=xxx] [-i=xxx] [-k=xxx] [-t=xxx]
- Copying a single object
Examples
- In Windows, run obsutil cp obs://bucket-test/key obs://bucket-test2 to copy a single object.
obsutil cp obs://bucket-test/key obs://bucket-test2 Start at 2024-09-30 08:30:09.0815415 +0000 UTC Parallel: 3 Jobs: 3 Threshold: 50.00MB PartSize: auto CheckpointDir: xxxx [=====================================================] 100.00% 6/s 0s Waiting for the copied key to be completed on server side. Copy successfully, 19B, obs://bucket-test/key --> obs://bucket-test2/key ext.txt, cost [1708], status [200], request id [00000192420D227E4017336A12F1DC22]
- In Windows, run obsutil cp obs://bucket-test/temp/ obs://bucket-test2 -f -r to copy objects in batches.
obsutil cp obs://bucket-test/temp/ obs://bucket-test2 -r -f Start at 2024-09-30 08:34:02.7819703 +0000 UTC Parallel: 5 Jobs: 5 Threshold: 50.00MB PartSize: auto CheckpointDir: xxxx Task id: 0476929d-9d23-4dc5-b2f8-0a0493f027c5 OutputDir: xxxx [=============================================================] 100.00% 10/s 0s Succeed count: 5 Failed count: 0 Metrics [max cost:298 ms, min cost:192 ms, average cost:238.00 ms, average tps:9.71, transferred size: 7.20MB] Task id: 0476929d-9d23-4dc5-b2f8-0a0493f027c5
- For more examples, see Common Examples.
Parameter Description
| Parameter | Optional or Mandatory | Description |
|---|---|---|
| srcbucket | Mandatory | The source bucket name |
| dstbucket | Mandatory | The destination bucket name |
| dest | Optional | The destination object name when copying an object, or the name prefix of destination objects when copying objects in batches |
| key | Mandatory for copying an object. Optional for copying objects in batches. | The source object name when copying an object, or the name prefix of source objects when copying objects in batches The rules are as follows:
NOTE: For details about how to use this parameter, see Copy. |
| fr | Optional for copying an object (additional parameter) | Generates an operation result file when copying an object. |
| flat | Optional for copying objects in batches (additional parameter) | The name prefix of the parent object is excluded when copying objects in batches. |
| dryRun | Optional (additional parameter) | Conducts a dry run. |
| crr | Mandatory for cross-region replication across accounts | Enables the client-side cross-region replication function. In this mode, data is directly copied to the destination bucket from the source bucket through data stream. The buckets can be any two OBS buckets.
NOTE: The configurations of the source bucket and destination bucket are respectively akCrr/skCrr/tokenCrr/endpointCrr and ak/sk/token/endpoint in the configuration file. |
| vlength | Optional (additional parameter) | Verifies whether the object size in the destination bucket is the same as that in the source bucket after the copy task completes. This parameter must be used together with crr. |
| vmd5 | Optional (additional parameter) | Verifies whether the MD5 value of the destination bucket is the same as that of the source bucket after the copy task completes.
|
| u | Optional (additional parameter) | Indicates incremental copy. If this parameter is set, each object can be copied only when it does not exist in the destination bucket, its size is different from the namesake one in the destination bucket, or it has the latest modification time. |
| p | Optional (additional parameter) | The maximum number of concurrent multipart copy tasks when copying an object. The default value is the value of defaultParallels in the configuration file. |
| threshold | Optional (additional parameter) | The threshold for enabling multipart copy. If the size of the object to be copied is smaller than the threshold, copy the object directly. If not, a multipart copy is required. The default value is the value of defaultBigfileThreshold in the configuration file. Unit: byte This parameter value can contain a unit, for example, 1MB (indicating 1,048,576 bytes). NOTE: If you copy an object directly, no part record is generated, and resumable transmission is not supported. |
| versionId | Optional for copying an object (additional parameter) | The source object version ID that can be specified when copying an object |
| acl | Optional (additional parameter) | The access control policies for destination objects that can be specified when copying objects. Possible values are:
|
| sc | Optional (additional parameter) | The storage classes of the destination objects that can be specified when copying objects. Possible values are:
|
| meta | Optional (additional parameter) | The standard or user-defined metadata that can be specified during object replication.
|
| fs | Optional (additional parameter) | Specifies whether the method of listing parallel file systems is applied. If you are listing parallel file systems, you are recommended to add this parameter.
|
| ps | Optional (additional parameter) | The size of each part in a multipart copy task
|
| cpd | Optional (additional parameter) | The folder where the part records reside. The default value is .obsutil_checkpoint, the subfolder in the home directory of the user who executes obsutil commands. A part record is generated during a multipart copy and saved to the upload subfolder. After the copy succeeds, its part record is deleted automatically. If the copy fails or is suspended, the system attempts to resume the task according to its part record when you perform the copy the next time. |
| r | Mandatory for copying objects in batches (additional parameter) | Copies objects in batches based on a specified name prefix of objects in the source bucket. |
| f | Optional for copying objects in batches (additional parameter) | Runs in force mode. |
| j | Optional for copying objects in batches (additional parameter) | The maximum number of concurrent tasks for copying objects in batches. The default value is the value of defaultJobs in the configuration file. NOTE: The value is ensured to be greater than or equal to 1. |
| exclude | Optional for copying objects in batches (additional parameter) | The matching patterns of source objects that are excluded. After this parameter is specified, if the name of the object to be copied matches the value of this parameter, the object is skipped. For example, if this parameter is set to *.txt, all files whose names end with .txt are skipped and not copied.
Constraints: This matching pattern applies only to objects whose names do not end with a slash (/). NOTE:
|
| include | Optional for copying objects in batches (additional parameter) | The included matching patterns of source objects. After this parameter is specified, if the name of the object to be copied matches the value of this parameter, the object is copied. For example, if this parameter is set to *.txt, all objects whose names end with .txt are copied.
Constraints:
Example: ./obsutil cp obs://src-bucket/ obs://target-bucket/ -include=/src-object/* -f -r This command copies files whose names start with src-object/ from the src-bucket bucket to the target-bucket bucket. NOTE:
|
| timeRange | Optional for copying objects in batches (additional parameter) | The time range matching pattern when copying objects. Only objects whose latest modification time is within the configured time range are copied. This pattern has a lower priority than the file matching patterns (exclude/include). That is, the time range matching pattern is executed after the configured file matching patterns.
This matching pattern applies only to objects whose names do not end with a slash (/). |
| mf | Optional (additional parameter) | Indicates that the name matching pattern (include or exclude) and the time matching pattern (timeRange) also take effect on objects whose names end with a slash (/). |
| o | Optional (additional parameter) | The folder that stores the result files. After the command is executed, result files (possibly success, failure, and warning files) will be created in the specified folder. The default value is .obsutil_output, a subfolder in the user's home directory where obsutil commands are executed.
|
| config | Optional (additional parameter) | The user-defined configuration file for executing the current command. To learn the parameters that can be configured in this file, see Configuration Parameters. |
| e | Optional (additional parameter) | The endpoint |
| i | Optional (additional parameter) | The user's AK |
| k | Optional (additional parameter) | The user's SK |
| t | Optional (additional parameter) | The user's security token |
Response
| Field | Description |
|---|---|
| Parallel | The parameter -p in the request |
| Jobs | The parameter -j in the request |
| Threshold | The parameter -threshold in the request |
| PartSize | The parameter -ps in the request |
| Exclude | The parameter -exclude in the request |
| Include | The parameter -include in the request |
| TimeRange | The parameter -timeRange in the request |
| VerifyLength | The parameter -vlength in the request |
| VerifyMd5 | The parameter -vmd5 in the request |
| CheckpointDir | The parameter -cpd in the request |
| OutputDir | The parameter -o in the request |
| ArcDir | The parameter -arcDir in the request |
| Succeed count | The number of successful tasks |
| Failed count | The number of failed tasks |
| Skip count | The number of tasks that are skipped during incremental upload, download, or copy, and synchronous upload, download, or copy. NOTE: Skipped tasks are recorded into successful tasks. |
| Warning count | The number of tasks that are executed successfully but contain warnings. NOTE:
|
| Succeed bytes | The number of bytes that are successfully uploaded or downloaded. |
| max cost | The maximum duration of all tasks, in ms |
| min cost | The minimum duration of all tasks, in ms |
| average cost | The average duration of all tasks, in ms |
| average tps | The average number of tasks completed per second |
| Task id | The unique ID of an operation, which is used to search for the result file generated for a batch task |
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



