

CREATE TABLE
功能描述
在当前数据库中创建一个新的空白表。
该表由命令执行者所有,如果系统管理员在某个与普通用户同名的schema下创建表,则该表的所有者为该schema对应的普通用户,而非系统管理员。
注意事项
| 约束项 | 详细内容 |
|---|---|
| 创建列存和HDFS分区表的数量 | 建议不超过1000个。 |
| 列存表支持的数据类型 | 请参考列存表支持的数据类型。 |
| 主键与唯一约束要求 | 表中的主键约束(PRIMARY KEY)和唯一约束(UNIQUE)必须包含分布列。 |
| 分布列修改限制 | 不支持修改已有表的分布列数据类型。 |
| 行存REPLICATION表限制 | 行存REPLICATION分布表不支持将系统列设置为主键。 |
| 列存表约束支持范围 | 列存表仅支持PARTIAL CLUSTER KEY、主键和唯一表级约束,不支持外键(FOREIGN KEY)表级约束。 |
| 列存表的字段约束 | 仅支持NULL、NOT NULL和DEFAULT常量值。 |
| 冷热表 |
|
| 列存表支持delta表 | 列存表支持delta表,由表级参数enable_delta控制是否开启,由参数deltarow_threshold控制进入delta表的阈值。不推荐使用列存带Delta表,否则会出现由于来不及merge而导致的磁盘膨胀以及性能劣化等问题。列存delta表由于上述问题在9.1.0.200后续版本不再支持新创建,统一使用HStore表替代,HStore相关资料参考《数据仓库服务开发指南》“实时数仓”章节。 |
| HSTORE表 |
|
| V3表 |
|
| 其他 | 如果在建表过程中数据库系统发生故障,系统恢复后可能无法自动清除之前已创建的、大小为0的磁盘文件。此种情况出现概率小,不影响数据库系统的正常运行。 |

- 不建议创建普通表时指定自定义TABLESPACE。
- 创建行存表时应避免指定COMPRESS压缩属性。
- 创建HASH分布的表对象时,要确保数据分布均匀(10G以上数据量的表,倾斜率控制在10%以内)。
- 创建REPLICATION分布的表对象,要确保表数据量控制在100万行以内。
- 针对存在时间字段的大表(数据量5000万行以上),必须设计成分区表,根据查询特征合理设计分区间隔。
- 针对有大批量数据增删改的表,索引个数建议控制在3个以内,最多不超过5个。
- 更多开发设计规范参见总体开发设计规范。
语法格式
1 2 3 4 5 6 7 8 9 10 11 12 | CREATE [ [ GLOBAL | LOCAL | VOLATILE ] { TEMPORARY | TEMP } | UNLOGGED ] TABLE [ IF NOT EXISTS ] table_name { ({ column_name data_type [ compress_mode ] [ COLLATE collation ] [ column_constraint [ ... ] ] | table_constraint | LIKE source_table [ like_option [...] ] } [, ... ])| LIKE source_table [ like_option [...] ] } [ WITH ( {storage_parameter = value} [, ... ] ) ] [ ON COMMIT { PRESERVE ROWS | DELETE ROWS } ] [ COMPRESS | NOCOMPRESS ] [ DISTRIBUTE BY { REPLICATION | ROUNDROBIN | { HASH ( column_name [,...] ) } } ] [ TO { GROUP groupname | NODE ( nodename [, ... ] ) } ] [ COMMENT [=] 'text' ]; |
- 其中列约束column_constraint为:
1 2 3 4 5 6 7 8 9 10 11
[ CONSTRAINT constraint_name ] { NOT NULL | NULL | CHECK ( expression ) | DEFAULT default_expr | ON UPDATE on_update_expr | COMMENT 'text' | UNIQUE [ NULLS [NOT] DISTINCT | NULLS IGNORE ] index_parameters | PRIMARY KEY index_parameters | REFERENCES reftable [ ( refcolumn ) ] } [ DEFERRABLE | NOT DEFERRABLE | INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
- 其中列的压缩可选项compress_mode为:
1{ DELTA | PREFIX | DICTIONARY | NUMSTR | NOCOMPRESS }
- 其中表约束table_constraint为:
1 2 3 4 5 6
[ CONSTRAINT constraint_name ] { CHECK ( expression ) | UNIQUE [ NULLS [NOT] DISTINCT | NULLS IGNORE ] ( column_name [, ... ] ) index_parameters | PRIMARY KEY ( column_name [, ... ] ) index_parameters | PARTIAL CLUSTER KEY ( column_name [, ... ] ) } [ DEFERRABLE | NOT DEFERRABLE | INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
- 其中like选项like_option为:
1{ INCLUDING | EXCLUDING } { DEFAULTS | CONSTRAINTS | INDEXES | STORAGE | COMMENTS | PARTITION | RELOPTIONS | DISTRIBUTION | DROPCOLUMNS | ALL }
- 其中索引参数index_parameters为:
1[ WITH ( {storage_parameter = value} [, ... ] ) ]
表设计参考
DWS兼容PostgreSQL生态,行存及其B-Tree索引和PostgreSQL类似,列存及其索引为自研。建表时,选择合适的存储方式、分布列、分区键、索引,能够使SQL在执行时快速命中数据,减少IO消耗。下图是一个SQL从发起到获取数据的执行流程,通过下图,可以理解每个技术手段的作用,用于指导性能调优。

- SQL执行时,分区表会通过Partition Column分区列进行分区裁剪,定位到所在分区。
- Hash分布表会通过Distribute Column快速定位到数据所在的数据分片(存算一体定位到DN,存算分离定位到bucket)。
- 行存通过B-Tree快速定位到数据所在的Page;列存通过min-max索引快速定位到可能存在数据的CU(Column Unit)数据块,PCK(Partial Cluster Key)列上的min-max索引过滤效果最好。
- 系统自动为列存的所有列维护min-max索引,无需用户定义。min-max索引是粗过滤,满足min-max条件的CU数据块不一定真正存在满足filter条件的数据行,如果定义了bitmap column,可以通过bitmap index快速定位到CU内符合条件的数据所在的行号;对于有序的CU,也会通过二分查找快速定位数据的行号。
- 列存也支持B-Tree和GIN索引,通过B-Tree/GIN索引也可以快速定位到满足条件的数据所在的CU及行号,但是,索引的维护代价比较大,除非对点查有极高的性能诉求,推荐使用bitmap index替代B-Tree/GIN。
DWS已有的优化手段可参考表2。
| 编号 | 优化手段 | 使用建议 | SQL示例 | 建表后是否可修改 | ||
|---|---|---|---|---|---|---|
| 1 | 字符串类型 |
| - | 是,已有数据会重写。 | ||
| 2 | Numeric类型 | Numeric类型要求都指定精度,性能会显著提高,不建议使用无精度的numeric。 | - | 是,已有数据会重写。 | ||
| 3 | Partition by Column(分区键) |
|
| 否,如需修改请重新建表。 | ||
| 4 | secondary_part_column(二级分区列) |
|
| 否,如需修改请重新建表。 | ||
| 5 | Distribute by Column(分布列) | 需用户定义,适用于频繁进行GROUP BY或者多表JOIN的关键字段,通过本地连接(Local Join)减少数据重分布(Shuffle),适用于等值查询。 |
| 否,如需修改请重新建表。 | ||
| 6 | Bitmap column(位图列) | 需用户定义,根据CU内的重复值,自适应创建bitmap index(基数<=32),或者bloom filter(基数>32),适用VARCHAR/TEXT类型列的等值查询,建议对WHERE条件中频繁过滤的列创建。 |
| 可以修改,已有数据不重写,只影响新数据。 | ||
| 7 | Min-max索引(稀疏索引) |
|
| PCK可以修改,已有数据不重写,只影响新数据。 | ||
| 8 | 主键(B-Tree索引) |
|
| 可以修改,重建索引。 | ||
| 9 | GIN索引 |
|
| 可以修改,重建索引。 | ||
| 10 | Orientation=column/row | 指定表为行存或者列存,行存不支持压缩,适合点查询和频繁更新场景;列存支持压缩,适合分析型(OLAP)场景。 | - | 否,如需修改请重新建表。 |
参数说明
| 参数 | 描述 | 取值范围或示例 | ||
|---|---|---|---|---|
| UNLOGGED | 如果指定UNLOGGED关键字,则创建的表为非日志表(Unlogged Table)。写入非日志表的数据不会被写入预写日志(WAL),因此写入速度比普通表快很多。但非日志表在冲突、执行操作系统重启、强制重启、切断电源操作或异常关机后会被自动截断(TRUNCATE),造成数据丢失的风险。非日志表中的内容也不会被复制到备服务器中,在非日志表中创建的索引也不会被自动记录。 须知:
| 使用场景:非日志表不能保证数据的安全性,用户应该在确保数据已经做好备份的前提下使用,例如系统升级时进行数据的备份。 故障处理:当异常关机等操作导致非日志表上的索引发生数据丢失时,用户应该对发生错误的索引进行重建。 示例: CREATE UNLOGGED TABLE table_unlog (
col1 VARCHAR(50) ,
col2 TEXT
); | ||
| GLOBAL | LOCAL | VOLATILE | 创建临时表时在TEMP或TEMPORARY前指定GLOBAL、LOCAL、VOLATILE关键字,以创建不同属性的临时表。仅8.2.1.220及以上集群版本支持全局临时表。
| 示例: CREATE LOCAL TEMP TABLE temp_test (
col1 INT,
col2 DECIMAL(10,2)
); | ||
| TEMPORARY | TEMP | 指定TEMP或TEMPORARY关键字,则创建的表为临时表。 临时表只在当前会话可见,本会话结束后会自动删除。因此,在除当前会话连接的CN以外的其他CN故障时,仍然可以在当前会话上创建和使用临时表。 由于临时表只在当前会话创建,对于涉及对临时表操作的DDL语句,可能会产生DDL失败的报错。因此,建议DDL语句中不要对临时表进行操作。TEMP和TEMPORARY等价。 | 该参数其他使用约束请参见TEMPORARY | TEMP参数使用说明。 | ||
| IF NOT EXISTS | 指定IF NOT EXISTS时,若不存在同名表,则可以成功创建表。若已存在同名表,创建时不会报错,仅会提示该表已存在并跳过创建。 | 示例:使用IF NOT EXISTS避免表重复创建错误。 CREATE TABLE IF NOT EXISTS test_t1(col1 INT,col2 VARCHAR(30)); | ||
| table_name | 要创建的表名。 | |||
| column_name | 新表中要创建的列名。 | 列名长度不超过63个字符,以字母或下划线开头,可包含字母、数字、下划线、$、#。 | ||
| data_type | 列的数据类型。 | 在兼容Teradata或MySQL语法的数据库中,列数据类型指定为DATE时同样返回为DATE类型,否则返回TIMESTAMP类型。 | ||
| compress_mode | 列的压缩选项,当前仅对行存表有效。该选项指定表字段优先使用的压缩算法。 | DELTA、PREFIX、DICTIONARY、NUMSTR或NOCOMPRESS。 | ||
| COLLATE collation | COLLATE子句指定列的排序规则(该列必须是可排序的数据类型)。如果没有指定,则使用默认的排序规则。 了解排序规则,参见DWS排序规则章节。 | 示例:创建表t1,使用case_insensitive的排序规则,表示列不区分大小写。 CREATE TABLE t1 (a text collate case_insensitive); | ||
| LIKE source_table [ like_option ... ] | LIKE子句声明一个表,新表自动从这个表中继承所有列名及其数据类型和非空约束。 | LIKE相关使用约束参见LIKE参数使用说明。 | ||
| WITH | 这个子句为表或索引指定可选的存储参数。 说明: 使用任意精度类型Numeric定义列时,建议指定精度p以及刻度s。在不指定精度和刻度时,会按输入的显示出来。 | WITH包含的子参数较多,按场景分类如下,开发者仅需关注特定场景下的参数即可: | ||
| ON COMMIT { PRESERVE ROWS | DELETE ROWS } | ON COMMIT选项决定在事务中创建临时表后,当事务提交时该临时表的后续行为。
全局临时表只支持PRESERVE ROWS选项。 | - | ||
| COMPRESS | NOCOMPRESS | 创建新表时,需要在CREATE TABLE语句中指定关键字COMPRESS,这样,当对该表进行批量插入时就会触发压缩特性。该特性会在页范围内扫描所有元组数据,生成字典、压缩元组数据并进行存储。指定关键字NOCOMPRESS则不对表进行压缩。 | 缺省值:NOCOMPRESS,即不对元组数据进行压缩。 | ||
| DISTRIBUTE BY | 指定表数据在节点之间的分布或者复制方式。
其他详细使用约束参见DISTRIBUTE BY参数使用说明。 | 示例: 指定表的数据分布方式为HASH。 CREATE TABLE test_t2(col1 INT,col2 VARCHAR(30))DISTRIBUTE BY HASH(col1); | ||
| TO { GROUP groupname | NODE ( nodename [, ... ] ) } | TO GROUP指定创建表所在的Node Group,目前不支持hdfs表使用。TO NODE主要供内部扩容工具使用,一般用户不应使用。 | 在逻辑集群模式下,如果不指定TO GROUP,表默认会创建在逻辑集群用户关联的节点组中;如果用户没有管理逻辑集群(例如管理员用户或其他普通用户),表默认会创建在第一个逻辑集群中(pgxc_group中oid最小的逻辑集群是第一个逻辑集群)。 如果TO GROUP指定的节点组是复制表节点组,表将创建在所有CN和DN节点上,但复制表数据将只分布在复制表节点组包含的DN节点上。 存算分离3.0版本支持只读逻辑集群,如果未绑定到只读逻辑集群的用户建表语句中TO GROUP指定的是只读逻辑集群,则创建表会报错;但绑定到只读逻辑集群的用户创建表会遵循未绑定逻辑集群用户的建表规则,将表创建到由GUC参数default_storage_nodegroup指定的逻辑集群上。如果default_storage_nodegroup是installation, 表会创建在第一个逻辑集群中。 | ||
| COMMENT [=] 'text' | COMMENT子句可在创建表时指定表注释。 | 示例: 添加表注释。 CREATE TABLE table_user(user_id INT,username VARCHAR(50)) COMMENT 'user Information'; | ||
| COMMENT 'text' | COMMENT子句可以指定列的注释。 | 示例: 添加指定列的注释。 CREATE TABLE table_users(user_id INT COMMENT 'employee id',username VARCHAR(50)); | ||
| CONSTRAINT constraint_name | 列约束或表约束的名字。可选的约束子句用于声明约束,新行或者更新的行必须满足这些约束才能成功插入或更新。 定义约束有两种方法:
| 示例: 创建表table_c_products,定义了主键约束:表的主键由C_CUSTKEY和C_NAME组成。 CREATE TABLE table_c_products
(
C_CUSTKEY BIGINT,
C_NAME VARCHAR(25) ,
C_ADDRESS VARCHAR(40),
C_NATIONKEY INT,
C_PHONE CHAR(15) ,
C_ACCTBAL DECIMAL(15,2),
CONSTRAINT C_CUSTKEY_KEY PRIMARY KEY(C_CUSTKEY,C_NAME)
)
DISTRIBUTE BY HASH(C_CUSTKEY,C_NAME); | ||
| NOT NULL | 字段值不允许为NULL。 | - | ||
| NULL | 字段值允许为NULL,这是默认值。 这个子句只是为和非标准SQL数据库兼容。不建议使用。 | - | ||
| CHECK ( expression ) | CHECK约束声明一个布尔表达式,每次要插入的新行或者要更新的行的新值必须使表达式结果为真或未知才能成功,否则会抛出一个异常并且不会修改数据库。 声明为字段约束的检查约束应该只引用该字段的数值,而在表约束里出现的表达式可以引用多个字段。 | expression表达式中,如果存在“<>NULL”或“!=NULL”,这种写法是无效的,需要写成“is NOT NULL”。 | ||
| DEFAULT default_expr | DEFAULT子句给字段指定缺省值。 | 该数值可以是任何不含变量的表达式(不允许使用子查询和对本表中的其他字段的交叉引用)。缺省表达式的数据类型必须和字段类型匹配。 缺省表达式将被用于任何未声明该字段数值的插入操作。若未显式指定DEFAULT,则默认值为NULL。 | ||
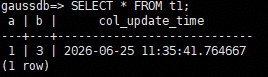
| ON UPDATE on_update_expr | ON UPDATE子句给字段指定时间戳函数。ON UPDATE子句支持指定的字段类型必须为timestamp类型或者timestamptz类型。 当执行含有update操作的SQL语句时,自动更新此列为时间戳函数所代表的时间。 on_update_expr时间戳函数仅支持CURRENT_TIMESTAMP, CURRENT_TIME, CURRENT_DATE, LOCALTIME, LOCALTIMESTAMP。 | 示例:当更新t1表的b列数据时,第三列会显示对应的更新时间。
| ||
| UNIQUE [ NULLS [ NOT ] DISTINCT | NULLS IGNORE ] index_parameters UNIQUE [ NULLS [ NOT ] DISTINCT | NULLS IGNORE ] ( column_name [, ... ] ) index_parameters | UNIQUE约束表示表里的一个字段或多个字段的组合必须在全表范围内唯一。 其中[ NULLS [ NOT ] DISTINCT | NULLS IGNORE ]字段用来指定Unique唯一索引中索引列NULL值的处理方式。 | 默认值:该参数默认缺省,即NULL值可重复插入。 在对插入的新数据和表中原始数据进行列的等值比较时,对于NULL值有以下三种处理方式:
三种处理方式具体的行为如表10所示。 说明: 如果没有声明DISTRIBUTE BY REPLICATION,则唯一约束的列集合中必须包含分布列。 | ||
| PRIMARY KEY index_parameters PRIMARY KEY ( column_name [, ... ] ) index_parameters | 主键约束声明表中的一个或者多个列只能包含唯一的非NULL值。 一个表只能声明一个主键。 注意: 如果没有声明DISTRIBUTE BY REPLICATION,则主键约束的列集合中必须包含分布列。 | 示例: 创建表products,定义 product_no为整数类型,并将其设为主键。 CREATE TABLE products (product_no integer PRIMARY KEY, name text, price numeric ) DISTRIBUTE BY HASH(product_no); | ||
| REFERENCES reftable [ ( refcolumn ) ] | 外键约束要求新表中一列或多列构成的组应该只包含、匹配被参考表中被参考字段值。被参考列应该是被参考表中的唯一字段或主键。 由于DWS不会进行外键约束检查,使用外键约束时需通过函数。check_foreign_key_constraint来检测外键表中的数据是否满足外键约束。 | - | ||
| DEFERRABLE | NOT DEFERRABLE | 这两个关键字设置该约束是否可延迟。一个不可延迟的约束将在每条命令之后马上检查。可延迟约束可以延迟到事务结尾使用SET CONSTRAINTS命令检查。 缺省是NOT DEFERRABLE。目前,只有行存的UNIQUE约束和主键约束可以接受这个子句。所有其他约束类型都是不可延迟的。 | - | ||
| PARTIAL CLUSTER KEY | 局部聚簇存储,列存表导入数据时按照指定的列(单列或多列),进行局部排序。 | 示例: 创建表products_new,并在product_no列上定义了局部聚簇。 CREATE TABLE products_new
(
product_no integer,
name text,
price numeric,
PARTIAL CLUSTER KEY(product_no)
) WITH (ORIENTATION = COLUMN); | ||
| INITIALLY IMMEDIATE | INITIALLY DEFERRED | 如果约束是可延迟的,则这个子句声明检查约束的缺省时间。 |
|
| 参数 | 描述 | 取值范围 |
|---|---|---|
| ORIENTATION | 指定表数据的存储方式,即行存方式、列存方式,该参数设置成功后就不再支持修改。
|
默认值:ROW,即行存方式。 说明: 如需创建列存表,需显式设置orientation属性为column,存算分离版本如需创建本地表(数据全部存储在EVS盘),需显式指定colversion=2.0 |
| COMPRESSION | 指定表数据的压缩级别,它决定了表数据的压缩比以及压缩时间。一般来讲,压缩级别越高,压缩比也越大,压缩时间也越长;反之亦然。实际压缩比取决于加载的表数据的分布特征。 | 该参数仅列存表支持,有效值为:LOW、MIDDLE或HIGH。默认值为LOW。 DWS内部提供的压缩算法参见表9。 说明:
|
| COMPRESSLEVEL | 指定表数据同一压缩级别下的不同压缩水平,它决定了同一压缩级别下表数据的压缩比以及压缩时间。 对同一压缩级别进行了更加详细的划分,为用户选择压缩比和压缩时间提供了更多的空间。总体来讲,此值越大,表示同一压缩级别下压缩比越大,压缩时间越长;反之亦然。该参数只对列存表有效。 | 0~3 默认值:0 |
| MAX_BATCHROW | 指定了在数据加载过程中一个存储单元可以容纳记录的最大数目。该参数只对列存表有效。 | 10000~60000 默认值:60,000 |
| PARTIAL_CLUSTER_ROWS | 指定了在数据加载过程中进行局部聚簇存储的记录数目。该参数只对列存表有效。 | 600000~2147483647 默认值:4,200,000 |
| COLVERSION | 指定列存存储格式的版本,支持不同存储格式版本之间的切换。 |
默认值:存算一体版本默认值2.0,存算分离版本默认值3.0。 需注意,OBS冷热表仅支持COLVERSION为2.0格式。 说明:
|
| cache_policy(该参数仅9.0.2及以上的存算分离版本支持) | 控制了表或者分区表(磁盘)缓存的方式,如果在缓存策略中指定相应参数范围,则会进行热缓存,否则进行冷缓存。热缓存相比冷缓存占用的空间更大,技术上使用更加复杂的替换策略。
默认值:ALL 说明:
|
|
| enable_disaster_cstore | 指定了列存表是否开启细粒度容灾功能。该参数仅适用于COLVERSION为2.0的普通列存表,不支持hstore表、行存表、临时表、UNLOGGED表、外表、时序表、冷热表,物化视图以及开启delta表功能,并且不能和enable_hstore、enable_delta同时打开。该参数仅8.2.0.100及以上集群版本支持。 | - |
| fine_disaster_table_role | 该参数8.2.1版本中已废弃,为兼容历史版本功能保留该参数,当前版本设置无效。 指定了细粒度容灾表的表角色为主表还是备表。使用该参数时,必须要保证已经开启了enable_disaster_cstore参数。 |
|
| on_commit_preserve_rows | 与 ON COMMIT { PRESERVE ROWS | DELETE ROWS } 类似。两者不能同时指定。该参数仅用于全局临时表。 | 默认值:true。 |
| 参数 | 描述 | 取值范围 |
|---|---|---|
| enable_delta | 指定了列存表是否开启delta表。该参数只对列存表有效。V3表暂不支持该参数,即COLVERSION为3.0时不支持设置enable_delta为on。 不推荐使用列存带Delta表,否则会出现由于来不及merge而导致的磁盘膨胀以及性能劣化等问题。 | 默认值:off |
| DELTAROW_THRESHOLD | 指定列存表导入时小于多少行的数据进入delta表,只在表级参数enable_delta开启时生效。该参数只对列存表有效。 | 0~60000 默认值:6000 |
| 参数 | 描述 | 取值范围 |
|---|---|---|
| enable_hstore | 指定了是否创建为HStore表(基于列存表实现)。该参数只对列存表有效。
| 取值为on/off 默认值:off |
| enable_hstore_opt | enable_hstore_opt表级参数打开时会默认同时打开enable_hstore表级参数,该参数仅9.1.0.100及以上集群版本支持。 | 取值为on/off 默认值:false 说明: 打开该参数时必须设置以下GUC参数用于保证HStore表的清理,推荐值如下: autovacuum=on,autovacuum_max_workers=6,autovacuum_max_workers_hstore=3。 |
| enable_binlog | 用于控制hstore表是否开启binlog功能。该参数仅9.1.0及以上集群版本支持。 | 取值为on/off 默认值:off |
| enable_binlog_timestamp | 用于控制hstore表是否开启带时间戳的binlog功能。该参数与enable_binlog无法同时打开,且仅9.1.0.200及以上集群版本支持。 | 取值为on/off 默认值:off |
| secondary_part_column | 指定列存表二级分区列的列名,仅能指定一列作为二级分区列且只适用于HStore列存表。该参数仅8.3.0及以上集群版本支持。 |
|
| secondary_part_num | 指定列存表二级分区的数量,仅适用于HStore列存表。该参数仅8.3.0及以上集群版本支持。
| 1~32 默认值:8 |
| bitmap_columns | bitmap index只适用于hstore_opt表,只有开启表级参数enable_hstore_opt且开启bitmap_columns="指定列",才能生成bitmap index映射关系。该参数仅8.3.0及以上集群版本支持。 | - |
| 参数 | 描述 | 取值范围 |
|---|---|---|
| FILLFACTOR | 一个表的填充因子(fillfactor)是一个介于10和100之间的百分数。100(完全填充)是默认值。如果指定了较小的填充因子,INSERT操作仅按照填充因子指定的百分率填充表页。每个页上的剩余空间将用于在该页上更新行,这就使得UPDATE有机会在同一页上放置同一条记录的新版本,这比把新版本放置在其他页上更有效。对于一个从不更新的表将填充因子设为100是合适的选择,但是对于频繁更新的表,选择较小的填充因子则更加合适。该参数对于列存表没有意义。 | 10~100 |
| analyze_mode | 控制表级自动analyze的方式。 |
默认值:all |
| incremental_analyze | 控制分区表是否启用增量analyze模式。该参数只对分区表有效,复制表不支持设置。该参数仅9.1.0.100及以上集群版本支持。 | 默认值:false |
| enable_turbo_store | 用于控制是否创建为turbo表(基于列存表实现)。该参数只对列存表有效。该选项仅9.1.0.100及以上集群版本支持。 说明:
| 默认值:off 说明: turbo表对部分numeric和varchar数据类型做了整数格式存储优化,以提升对于numeric和varchar数据类型的处理速度。
|
| SKIP_FPI_HINT | 顺序扫描过程中,若需要写FPW(full page writes)日志时,该参数控制是否跳过设置HintBits操作。 | 默认值:false 说明: 设置SKIP_FPI_HINT=true时,在对某表执行checkpoint操作后,若对该表进行顺序扫描,将不再产生Xlog。适用于查询次数较少的中间表,有效减少Xlog的大小,提升查询性能。 |
| enable_column_autovacuum_garbage | 用于控制是否开启列存表AUTOVACUUM重写CU的逻辑。该参数仅8.2.1.100及以上集群版本支持。 当前列存轻量化UPDATE与后台列存AUTOVACUUM并发会小概率报错, 可以通过设置该表级参数为off来避免。 | 默认值:true |
TEMPORARY | TEMP参数使用说明
- LOCAL/VOLATILE临时表通过每个会话独立的以pg_temp开头的schema来保证只对当前会话可见,因此,不建议用户在日常操作中手动删除以pg_temp,pg_toast_temp开头的schema。
- 如果建表时不指定TEMPORARY/TEMP关键字,而指定表的schema为当前会话的pg_temp_开头的schema,则此表会被创建为临时表。
- LOCAL临时表的所有相关元数据同普通表类似,都存储在系统表内,而VOLATILE临时表会将除schema外的相关表结构元数据直接存储在内存中。所以相对本地临时表而言,VOLATILE临时表有更多约束:
- 当前CN或DN重启之后,对应实例上的内存数据丢失,相关volatile临时表会失效。
- VOLATILE临时表当前不支持ALTER/GRANT等修改表结构相关操作。
- VOLATILE临时表和LOCAL临时表共用一种临时schema,所以在同一session中,VOLATILE临时表和LOCAL临时表不能存在同名表。
- VOLATILE临时表信息不存储在系统表内,所以无法通过对系统表执行DML语句查询到VOLATILE相关元数据。
- VOLATILE临时表仅支持普通的行存、列存表,不支持delta表、时序表、冷热表。
- 不支持基于VOLATILE临时表创建视图。
- 不支持创建临时表时指定tablespace(VOLATILE临时表默认tablespace均为pg_volatile)。
- 创建VOLATILE临时表时不支持指定约束:CHECK约束、UNIQUE约束、主键约束、触发器约束、EXCLUDE约束、PARTIAL CLUSTER约束。
- GLOBAL临时表的所有相关元数据同普通表类似,都存储在系统表内。
- GLOBAL临时表与LOCAL临时表不同的是,会话退出时元数据不会删除,但会话的数据会删除。不同会话的数据独立,但共享同一份GLOBAL临时表的元数据。
- 全局临时表与普通表一样必须定义在常规Schema中(如public或用户自定义Schema),不能使用以pg_temp开头的临时Schema。全局临时表可以与LOCAL/VOLATILE临时表同名,因为两者存储在不同的Schema中。
- 全局临时表仅支持普通的行存、列存表,不支持delta表、时序表、冷热表。
- 不支持操作其他逻辑集群的全局临时表。
LIKE参数使用说明
新表与源表之间在创建动作完毕之后是完全无关的。在源表做的任何修改都不会传播到新表中,并且也不可能在扫描源表的时候包含新表的数据。
被复制的列和约束并不使用相同的名字进行融合。如果明确的指定了相同的名字或者在另外一个LIKE子句中,将会报错。
- 源表上的字段缺省表达式或者ON UPDATE表达式只有在指定INCLUDING DEFAULTS时,才会复制到新表中。缺省是不包含缺省表达式的,即新表中的所有字段的缺省值都是NULL。
- 源表上的CHECK约束仅在指定INCLUDING CONSTRAINTS时,会复制到新表中,而其他类型的约束永远不会复制到新表中。非空约束总是复制到新表中。此规则同时适用于表约束和列约束。
- 如果指定了INCLUDING INDEXES,则源表上的索引也将在新表上创建,默认不建立索引。
- 如果指定了INCLUDING STORAGE,则复制列的STORAGE设置会复制到新表中,默认情况下不包含STORAGE设置。
- 如果指定了INCLUDING COMMENTS,则源表列、约束和索引的注释会复制到新表中。默认情况下,不复制源表的注释。
- 如果指定了INCLUDING PARTITION,则源表的分区定义会复制到新表中,同时新表将不能再使用PARTITION BY子句。默认情况下,不复制源表的分区定义。
- 如果指定了INCLUDING RELOPTIONS,则源表的存储参数(即源表的WITH子句)会复制到新表中。默认情况下,不复制源表的存储参数。

WITH中的'PERIOD','TTL'为partition相关参数,LIKE INCLUDING RELOPTIONS不会复制到新表中,若要复制需INCLUDING PARTITION。
- 如果指定了INCLUDING DISTRIBUTION,则源表的分布信息会复制到新表中,包括分布类型和分布列,同时新表将不能再使用DISTRIBUTE BY子句。默认情况下,不复制源表的分布信息。
- 如果指定了INCLUDING DROPCOLUMNS,则源表被删除的列信息会被复制到新表中。默认情况下,不复制源表的删除列信息。
- INCLUDING ALL包含了INCLUDING DEFAULTS、INCLUDING CONSTRAINTS、INCLUDING INDEXES、INCLUDING STORAGE、INCLUDING COMMENTS、INCLUDING PARTITION、INCLUDING RELOPTIONS、INCLUDING DISTRIBUTION和INCLUDING DROPCOLUMNS的内容。
- 如果指定了EXCLUDING,则表示不包括指定的参数。
- 如果是OBS冷热表,INCLUDING PARTITION后新表所有分区均为本地热分区。
- 对源表同时执行ALTER TABLE...ADD PARTITION与CREATE TABLE语句,偶发可能会出现不同节点的分区数量不一致的情况,从而导致CREATE TABLE语句报错。出现此情况时,建议重新执行CREATE TABLE语句,即可解决。

- 如果源表包含serial、bigserial、smallserial类型,或者源表字段的默认值是sequence,且sequence属于源表(通过CREATE SEQUENCE ... OWNED BY创建),这些Sequence不会关联到新表中,新表中会重新创建属于自己的sequence。这和之前版本的处理逻辑不同。如果用户希望源表和新表共享Sequence,需要首先创建一个共享的Sequence(避免使用OWNED BY),并配置为源表字段默认值,这样创建的新表会和源表共享该Sequence。
- 不建议将其他表私有的Sequence配置为源表字段的默认值,尤其是其他表只分布在特定的NodeGroup上,这可能导致CREATE TABLE ... LIKE执行失败。另外,如果源表配置其他表私有的Sequence,当该表删除时Sequence也会连带删除,这样源表的Sequence将不可用。如果用户希望多个表共享Sequence,建议创建共享的Sequence。
DISTRIBUTE BY参数使用说明
指定表如何在节点之间分布或者复制。
取值范围:
- REPLICATION:表的每一行存储在所有数据节点(DN)中,即每个数据节点都有完整的表数据。
- ROUNDROBIN:表的每一行被轮询发送给各个DN,因此数据会被均匀地分布在各个DN中。(ROUNDROBIN仅8.1.2及以上版本支持)
- HASH (column_name ) :对指定的列进行Hash,通过映射,把数据分布到指定DN。
- 当指定DISTRIBUTE BY HASH (column_name)参数时,创建主键和唯一索引必须包含“ column_name”列。
- 当被参照表指定DISTRIBUTE BY HASH (column_name)参数时,参照表的外键必须包含“ column_name”列。
- 如果TO GROUP指定为复制表节点组(8.1.2及以上版本支持),DISTRIBUTE BY必须指定为REPLICATION。如果没有指定DISTRIBUTE BY,创建的表会自动设置为复制表。
- 当default_distribution_mode=roundrobin时,DISTRIBUTE BY的默认值按如下规则选取:
- 若建表时包含主键/唯一约束,则选取HASH分布,分布列为主键/唯一约束对应的列。
- 若建表时不包含主键/唯一约束,则选取ROUNDROBIN分布。
- 当default_distribution_mode=hash时,DISTRIBUTE BY的默认值按如下规则选取:
- 若建表时包含主键/唯一约束,则选取HASH分布,分布列为主键/唯一约束对应的列。
- 若建表时不包含主键/唯一约束,但存在数据类型支持作分布列的列,则选取HASH分布,分布列为第一个数据类型支持作分布列的列。
- 若建表时不包含主键/唯一约束,也不存在数据类型支持作分布列的列,选取ROUNDROBIN分布。
- INTEGER TYPES:TINYINT,SMALLINT,INT,BIGINT,NUMERIC/DECIMAL
- CHARACTER TYPES:CHAR,BPCHAR,VARCHAR,VARCHAR2,NVARCHAR2,TEXT
- DATE/TIME TYPES:DATE,TIME,TIMETZ,TIMESTAMP,TIMESTAMPTZ,INTERVAL,SMALLDATETIME
在建表时,选择分布列和分区键可对SQL查询性能产生重大影响。因此,需要根据一定策略选择合适的分布列和分区键。
- 选择合适的分布列 对于采用散列(Hash)方式的数据分布表,一个合适的分布列应将一个表内的数据,均匀分散存储在多个DN内,避免出现数据倾斜现象(即多个DN内数据分布不均)。请按照如下原则判定合适的分布列:
- 判断是否已发生数据倾斜现象。
连接数据库,执行如下语句,查看各DN内元组数目。命令中的斜体部分tablename,请填入待分析的表名。
SELECT a.count,b.node_name FROM (SELECT count(*) AS count,xc_node_id FROM tablename GROUP BY xc_node_id) a, pgxc_node b WHERE a.xc_node_id=b.node_id ORDER BY a.count DESC;
如果各DN内元组数目相差较大(如相差数倍、数十倍),则表明已发生数据倾斜现象,请按照下面原则调整分布列。
- 重新选择分布列,可通过ALTER TABLE语句调整分布列,选择原则如下:
分布列的列值应比较离散,以便数据能够均匀分布到各个DN。例如,考虑选择表的主键为分布列,如在人员信息表中选择身份证号码为分布列。
在满足上面原则的情况下,考虑选择查询中的连接条件为分布列,以便Join任务能够下推到DN中执行,且减少DN之间的通信数据量。
- 如果找不到一个合适的分布列,使数据能够均匀分布到各个DN,那么可以考虑使用REPLICATION或ROUNDROBIN的数据分布方式。由于REPLICATION的数据分布方式会在每个DN中存放完整的数据,因此在表较大且找不到合适的分布列时,推荐使用ROUNDROBIN的数据分布方式。(ROUNDROBIN分布方式8.1.2及以上版本支持)
- 判断是否已发生数据倾斜现象。
- 选择合适的分区键
数据分区功能,可根据表的一列或者多列,将要插入表的记录分为若干个范围(这些范围在不同的分区里没有重叠)。然后为每个范围创建一个分区,用来存储相应的数据。
调整分区键,使每次查询结果尽可能存储在相同或者最少的分区内(称为“分区剪枝”),通过获取连续I/O大幅度提升查询性能。
实际业务中,经常将时间作为查询对象的过滤条件,因此,可考虑选择时间列为分区键,键值范围可根据总数据量、一次查询数据量调整。
示例:创建存算一体表
创建表test_t4。
1 2 3 4 5 6 7 8 9 10 11 | DROP TABLE IF EXISTS test_t4; CREATE TABLE test_t4 ( ---当数据库中没有同名表(test_t4)时创建表 col_id INT PRIMARY KEY, ---定义一个整数类型的列,并将其设为主键 col_number INT NOT NULL, ---定义一个整数类型的列,并设置为非空 col_date DATE NOT NULL, ---定义一个日期类型的列,并设置为非空 col_price NUMERIC(10,2), --- 定义一个数值类型的列,允许的最大整数位数为10,小数位数为2 col_status TEXT ---定义一个文本类型的列 ) WITH (ORIENTATION = COLUMN,COLVERSION=2.0,COMPRESSION=middle) ---表的存储方式为列存,表的压缩级别为MIDDLE DISTRIBUTE BY HASH (col_id) ---使用哈希分布 COMMENT ' order information for test_table4'; ---表注释 |
示例:创建存算分离V3表
创建名为test_t5的存算分离V3表(仅存算分离3.0版本支持)。
1 2 3 4 5 6 7 8 9 | DROP TABLE IF EXISTS test_t5; CREATE TABLE test_t5 ( id integer not null, data integer, age integer ) WITH (ORIENTATION =COLUMN, COLVERSION =3.0) DISTRIBUTE BY ROUNDROBIN; |
创建表的时候指定缓存策略(仅存算分离3.0版本集群支持)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | DROP TABLE IF EXISTS sports; CREATE TABLE sports ( N_NATIONKEY INT NOT NULL , N_NAME CHAR(25) NOT NULL , N_REGIONKEY INT NOT NULL , N_COMMENT VARCHAR(152) ) WITH (orientation = column, colversion = 3.0, cache_policy = 'HPL: Balls, Basketball') tablespace cu_obs_tbs DISTRIBUTE BY ROUNDROBIN partition by list(N_NAME) ( partition Balls values ('Basketball', 'football', 'badminton'), partition Athletics values ('High jump', 'long jump', 'javelin'), partition Water_Sports values ('Surfing', 'diving', 'swimming'), partition Shooting values ('air guns', 'Rifles', 'archery'), partition rest values (DEFAULT) ); |
示例:创建表时定义约束
为表定义主键表约束,可以在表的一列或多列上定义主键表约束。
1 2 3 4 5 6 7 8 9 10 11 12 | DROP TABLE IF EXISTS CUSTOMER; CREATE TABLE CUSTOMER ( C_CUSTKEY BIGINT , C_NAME VARCHAR(25) , C_ADDRESS VARCHAR(40) , C_NATIONKEY INT , C_PHONE CHAR(15) , C_ACCTBAL DECIMAL(15,2) , CONSTRAINT C_CUSTKEY_KEY PRIMARY KEY(C_CUSTKEY,C_NAME) ) DISTRIBUTE BY HASH(C_CUSTKEY,C_NAME); |
为表定义唯一列约束。
1 2 3 4 5 6 7 8 9 10 11 | DROP TABLE IF EXISTS CUSTOMER; CREATE TABLE CUSTOMER ( C_CUSTKEY BIGINT NOT NULL CONSTRAINT C_CUSTKEY_pk PRIMARY KEY, C_NAME VARCHAR(25) , C_ADDRESS VARCHAR(40) , C_NATIONKEY INT , C_PHONE CHAR(15) , C_ACCTBAL DECIMAL(15,2) ) DISTRIBUTE BY HASH(C_CUSTKEY); |
定义CHECK表约束。
DROP TABLE IF EXISTS CUSTOMER;
CREATE TABLE CUSTOMER
(
C_CUSTKEY BIGINT NOT NULL CONSTRAINT C_CUSTKEY_pk PRIMARY KEY,
C_NAME VARCHAR(25) ,
C_ADDRESS VARCHAR(40) ,
C_NATIONKEY INT ,
CONSTRAINT C_CUSTKEY_KEY2 CHECK(C_CUSTKEY > 0 AND C_NAME <> '')
)
DISTRIBUTE BY HASH(C_CUSTKEY); 定义CHECK列约束。
1 2 3 4 5 6 7 8 9 | DROP TABLE IF EXISTS CUSTOMER; CREATE TABLE CUSTOMER ( C_CUSTKEY BIGINT NOT NULL CONSTRAINT C_CUSTKEY_pk PRIMARY KEY , C_NAME VARCHAR(25) , C_ADDRESS VARCHAR(40) , C_NATIONKEY INT NOT NULL CHECK (C_NATIONKEY > 0) ) DISTRIBUTE BY HASH(C_CUSTKEY); |
使用DEFAULT为列col_STATE声明默认值为“GA”。
1 2 3 4 5 6 7 8 9 10 11 | DROP TABLE IF EXISTS test_t5; CREATE TABLE test_t5 ( col_SK INTEGER NOT NULL, col_ID CHAR(16) NOT NULL, col_NAME VARCHAR(20) UNIQUE DEFERRABLE, col_WAREHOUSE INTEGER, col_COUNTY VARCHAR(30), col_STATE CHAR(2) DEFAULT 'GA', col_ZIP CHAR(10) ); |
示例:创建列存表并指定压缩方式
创建列存表customer_address并指定该表的数据压缩级别为高压缩。
1 2 3 4 5 6 7 8 9 10 11 12 | DROP TABLE IF EXISTS customer_address; CREATE TABLE customer_address ( ca_address_sk INTEGER NOT NULL , ca_address_id CHARACTER(16) NOT NULL , ca_street_number CHARACTER(10) , ca_street_name CHARACTER varying(60) , ca_street_type CHARACTER(15) , ca_suite_number CHARACTER(10) ) WITH (ORIENTATION = COLUMN, COMPRESSION=HIGH,COLVERSION=2.0) DISTRIBUTE BY HASH (ca_address_sk); |
示例:使用CREATE TABLE LIKE语句创建表
使用CREATE TABLE LIKE方式快速复制现有表test_t6结构创建表test_t7。
1 2 3 4 5 6 7 8 9 10 11 12 13 | DROP TABLE IF EXISTS test_t6; CREATE TABLE test_t6 ( col_id INT PRIMARY KEY, col_number INT NOT NULL, col_date DATE NOT NULL, col_price NUMERIC(10,2), col_status TEXT ) WITH (ORIENTATION = COLUMN, COMPRESSION=middle) DISTRIBUTE BY HASH (col_id); CREATE TABLE test_t7 (LIKE test_t6 INCLUDING ALL); |
示例:创建HPN磁盘缓存策略的分区表
cache policy选项可以在执⾏CREATE TABLE或者ALTER TABLE语句时设置成HPN:N,⽤户需要提供⼀个数字N(N >= -1600 && N <= 1600),之后获取表中的数据,更晚创建的N个分区中的数据会被热缓存,其余分区会被冷缓存。当N等于0时,所有分区中的数据都会被冷缓存。HPN只对V3表中的range分区表和list分区表⽣效。
了解更多磁盘缓存,请参见DWS磁盘缓存最佳实践。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | DROP TABLE IF EXISTS lineitem; CREATE TABLE lineitem ( L_ORDERKEY BIGINT NOT NULL , L_PARTKEY BIGINT NOT NULL , L_SUPPKEY BIGINT NOT NULL , L_LINENUMBER BIGINT NOT NULL , L_QUANTITY DECIMAL(15,2) NOT NULL , L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL , L_DISCOUNT DECIMAL(15,2) NOT NULL , L_TAX DECIMAL(15,2) NOT NULL , L_RETURNFLAG CHAR(1) NOT NULL , L_LINESTATUS CHAR(1) NOT NULL , L_SHIPDATE DATE NOT NULL , L_COMMITDATE DATE NOT NULL , L_RECEIPTDATE DATE NOT NULL , L_SHIPINSTRUCT CHAR(25) NOT NULL , L_SHIPMODE CHAR(10) NOT NULL , L_COMMENT VARCHAR(44) NOT NULL ) with ( orientation = column, colversion = 3.0, cache_policy = 'HPN:3' ) TABLESPACE cu_obs_tbs DISTRIBUTE BY HASH(L_ORDERKEY) PARTITION BY RANGE(L_SHIPDATE) ( PARTITION L_SHIPDATE_4 VALUES LESS THAN('1993-01-01 00:00:00'), -- 冷缓存 PARTITION L_SHIPDATE_5 VALUES LESS THAN('1994-01-01 00:00:00'), -- 冷缓存 PARTITION L_SHIPDATE_3 VALUES LESS THAN('1995-01-01 00:00:00'), -- 冷缓存 PARTITION L_SHIPDATE_1 VALUES LESS THAN('1996-01-01 00:00:00'), -- 冷缓存 PARTITION L_SHIPDATE_2 VALUES LESS THAN('1997-01-01 00:00:00'), -- 热缓存 PARTITION L_SHIPDATE_7 VALUES LESS THAN('1998-01-01 00:00:00'), -- 热缓存 PARTITION L_SHIPDATE_6 VALUES LESS THAN('1999-01-01 00:00:00') -- 热缓存 ); |
示例:创建HPL磁盘缓存策略的分区表
cache policy选项可以在执⾏CREATE TABLE或者ALTER TABLE语句时设置成HPL : , , ...,⽤户需要提供指定为热分区的分区名,之后获取表中的数据,热分区中的数据会被热缓存,⽽其余分区中的数据则会被冷缓存。HPL只对V3表中的range分区表和list分区表⽣效。
了解更多磁盘缓存,请参见DWS磁盘缓存最佳实践。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | DROP TABLE IF EXISTS nation; CREATE TABLE nation ( N_NATIONKEY INT NOT NULL, N_NAME CHAR(25) NOT NULL, N_REGIONKEY INT NOT NULL, N_COMMENT VARCHAR(152) ) WITH ( orientation = column, colversion = 3.0, cache_policy = 'HPL : ASIA, AMERICA, REST' ) TABLESPACE cu_obs_tbs DISTRIBUTE BY ROUNDROBIN PARTITION BY LIST(N_NAME) ( PARTITION ASIA VALUES ('INDIA', 'INDONESIA', 'JAPAN'), -- 热缓存 PARTITION EUROPE VALUES ('FRANCE', 'GERMANY', 'UNITED KINGDOM'), -- 冷缓存 PARTITION AFRICA VALUES ('ALGERIA', 'ETHIOPIA', 'KENYA'), -- 冷缓存 PARTITION AMERICA VALUES ('ARGENTINA', 'BRAZIL', 'CANADA'), -- 热缓存 PARTITION REST VALUES (DEFAULT) -- 热缓存 ); |




