
RDS for PostgreSQL指标告警配置建议
通过在云监控服务界面设置告警规则,用户可自定义监控目标与通知策略,及时了解实例的运行状况,从而起到预警作用。本章节介绍了设置RDS for PostgreSQL指标告警规则的配置及建议。
创建指标告警规则
- 登录管理控制台。
- 单击管理控制台左上角的
 ,选择区域和项目。
,选择区域和项目。 - 在“服务列表”中,选择“管理与监管 > 云监控服务”,进入“云监控”服务信息页面。
- 在左侧导航栏选择“云服务监控 > 关系型数据库”。
图1 选择监控对象
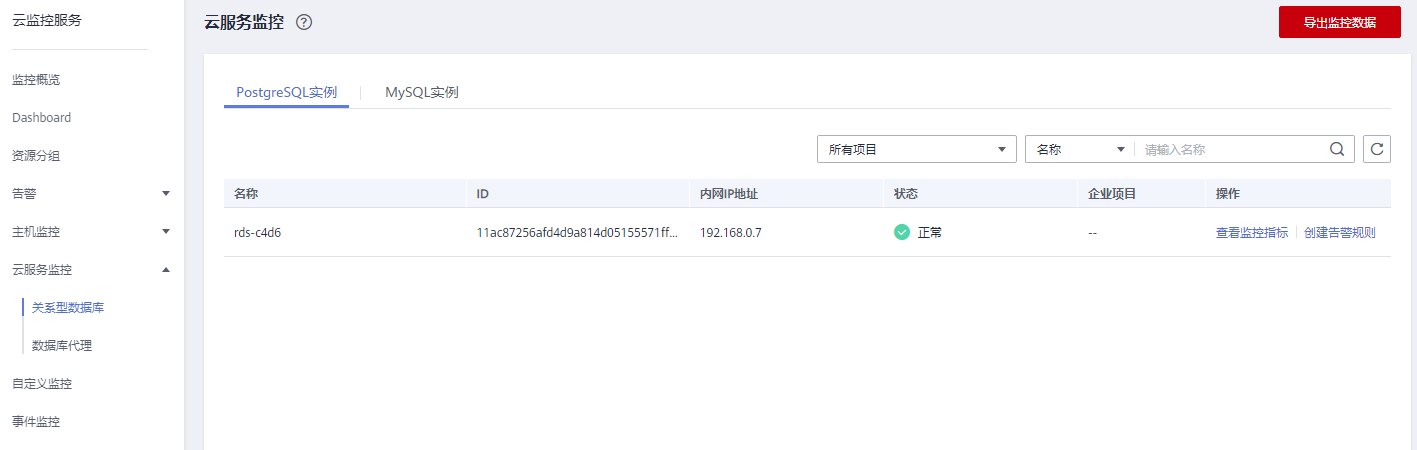
- 选择需要添加告警规则的实例,单击操作列的“创建告警规则”。
图2 创建告警规则

- 在“创建告警规则”页面,填选相关信息。
表1 告警规则信息 参数
参数说明
名称
系统会随机产生一个名称,用户也可以进行修改。
描述
告警规则描述。
触发规则
根据需要可选择关联模板、导入已有模板或自定义创建。
说明:选择关联模板后,所关联模板内容修改后,该告警规则中所包含策略也会跟随修改。
建议选择导入已有模板,模板中已经包含CPU使用率、内存使用率、磁盘利用率三个常用告警指标。
模板
选择需要导入的模板。
您可以选择系统预置的默认告警模板,或者选择自定义模板。
告警策略
触发告警规则的告警策略。
是否触发告警取决于连续周期的数据是否达到阈值。例如CPU使用率监控周期为5分钟,连续三个周期平均值≥80%,则触发告警。
说明:告警规则内最多可添加50条告警策略,若其中一条告警策略达到条件都会触发告警。
告警级别
根据告警的严重程度不同等级,可选择紧急、重要、次要、提示。
图3 设置告警通知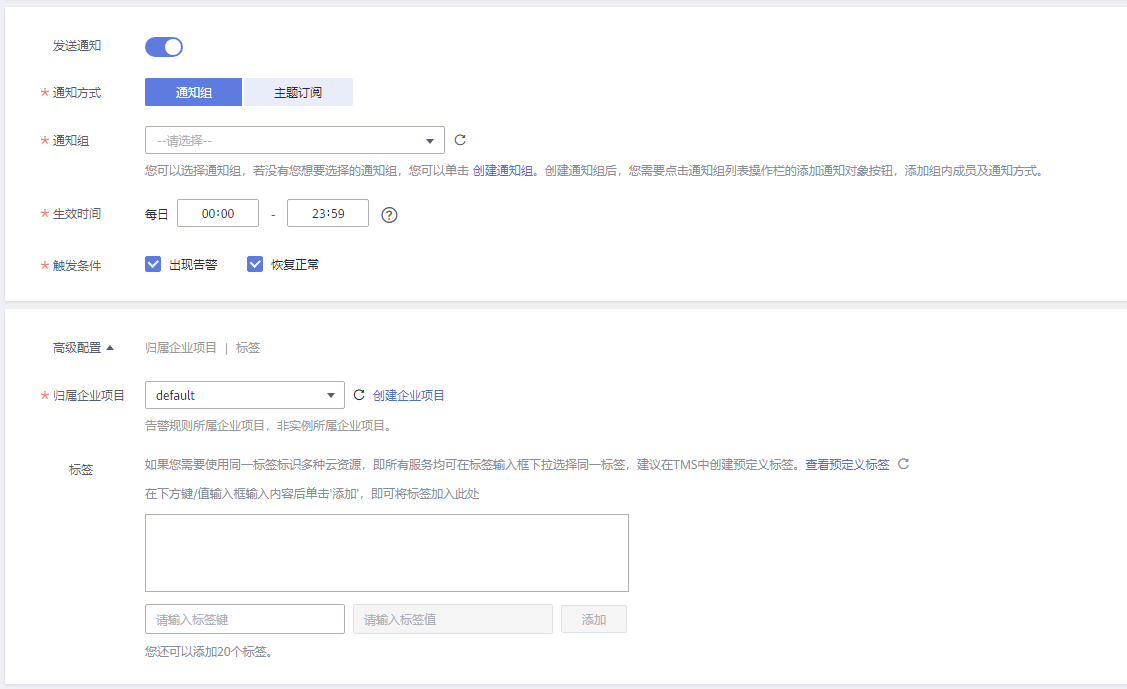
表2 告警通知 参数
参数说明
发送通知
配置是否发送邮件、短信、HTTP和HTTPS通知用户。
通知方式
根据需要可选择通知组或主题订阅两种方式。
通知组
需要发送告警通知的通知组。
通知对象
选择主题订阅时设置需要发送告警通知的对象,可选择云账号联系人或主题名称。
- 云账号联系人为注册时的手机和邮箱。
- 主题是消息发布或客户端订阅通知的特定事件类型。
生效时间
该告警仅在生效时间段发送通知消息,非生效时段则在隔日生效时段发送通知消息。
如生效时间为08:00-20:00,则该告警规则仅在08:00-20:00发送通知消息。
触发条件
可以选择“出现告警”、“恢复正常”两种状态,作为触发告警通知的条件。
归属企业项目
告警规则所属的企业项目。只有拥有该企业项目权限的用户才可以查看和管理该告警规则。
标签
标签由键值对组成,用于标识云资源,可对云资源进行分类和搜索。
- 单击“立即创建”,告警规则创建完成。
关于告警参数的配置,请参见《云监控用户指南》。
指标告警配置建议
|
指标ID |
指标名称 |
指标含义 |
最佳实践阈值 |
最佳实践告警级别 |
告警后的处理建议 |
|---|---|---|---|---|---|
|
rds001_cpu_util |
CPU使用率 |
该指标用于统计测量对象的CPU使用率,以比率为单位。 |
连续3个周期 原始值 > 80 % |
重要 |
|
|
rds002_mem_util |
内存使用率 |
该指标用于统计测量对象的内存使用率,以比率为单位。 |
连续3个周期 原始值 > 90 % |
重要 |
|
|
rds039_disk_util |
磁盘利用率 |
该指标用于统计测量对象的磁盘利用率,以比率为单位。 |
连续3个周期 原始值 > 80 % |
重要 |
|
|
rds045_oldest_replication_slot_lag |
最滞后副本滞后量 |
多个副本中最滞后副本(依据接收到的WAL数据)滞后量。 |
连续1个周期 原始值 > 20480 MB |
重要 |
建议参考最滞后副本滞后量和复制时延高问题定位及处理方法排查及处理。 |
|
rds046_replication_lag |
复制时延 |
副本滞后时延。 |
连续3个周期 原始值 > 600 s |
重要 |
|
|
rds083_conn_usage |
连接数使用率 |
该指标用于统计当前已用的PgSQL连接数占总连接数的百分比。 |
连续3个周期 原始值 > 80 % |
重要 |
|
|
active_connections |
活跃连接数 |
该指标为统计数据库当前活跃连接数。 |
连续1个周期 原始值 > [当前CPU核数*2] Counts |
重要 |
建议参考连接数和活跃连接数异常情况定位及处理方法排查及处理。 |
|
oldest_transaction_duration |
最长事务存活时长 |
该指标为统计当前数据库中存在的最长事务存活时长。 |
根据业务情况来配置。参考值:连续1个周期 原始值 > 7200000 ms |
重要 |
建议参考长事务问题定位及处理方法排查及处理。 |
|
oldest_transaction_duration_2pc |
最长未决事务存活时长 |
该指标为统计当前数据库存在的最长未决事务存活时长。 |
根据业务情况来配置。参考值:连续1个周期 原始值 > 7200000 ms |
重要 |
|
|
db_max_age |
最大数据库年龄 |
该指标为统计当前数据库的最大数据库年龄(获取表pg_database中max(age(datfrozenxid))值)。 |
连续1个周期 原始值 > 1000000000 |
重要 |
建议参考数据库年龄增长问题定位及处理方法排查及处理。 |
|
slow_sql_three_second |
已执行3s的SQL数 |
该指标为统计数据库执行时长3秒以上的慢SQL个数。 该指标为采集时刻的瞬时值,并不是一分钟内的累计值。 |
根据业务情况来配置。参考值:连续1个周期 原始值 > [当前CPU核数*2] Counts |
重要 |
建议参考已执行3s或5s SQL数问题定位及处理方法排查及处理。 |
|
slow_sql_five_second |
已执行5s的SQL数 |
该指标为统计数据库执行时长5秒以上的慢SQL个数。 该指标为采集时刻的瞬时值,并不是一分钟内的累计值。 |
根据业务情况来配置。参考值:连续1个周期 原始值 > [当前CPU核数*2] Counts |
重要 |
|
|
inactive_logical_replication_slot |
非活跃逻辑复制槽数量 |
该指标用于统计当前数据库中存在的非活跃逻辑复制槽数量。 |
连续3个周期 原始值 > 1 Counts |
重要 |
建议参考存在非活跃逻辑复制槽问题定位及处理方法排查及处理。 |




