
Migration
Data Migration
- Migrating Hadoop data to MRS
As shown in the following figure, data in the Hadoop cluster in the IDC or other public clouds is migrated to MRS. For details, see MRS Help Center.
Figure 1 Migrating Hadoop data
- Migrating HBase data to MRS
Migrate data in the HBase cluster in the IDC or other public clouds to MRS. HBase stores data in HDFS, including HFile and WAL files. The hbase.rootdir configuration item specifies the HDFS path. By default, data is stored in the /hbase folder on MRS. Some mechanisms and tool commands of HBase can also be used to migrate data. For example, you can migrate data by exporting snapshots, exporting/importing data, and CopyTable. For details, see the Apache official website.
You can also use CDM to migrate HBase data. For details, see MRS Help Center.
Figure 2 Migrating HBase data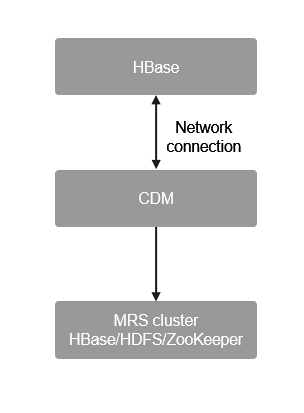
- Migrating Hive data to MRS
You can use CDM to migrate data in the Hive cluster in the IDC or other public clouds to MRS.
For details, see MRS Help Center.
Figure 3 Migrating Hive metadata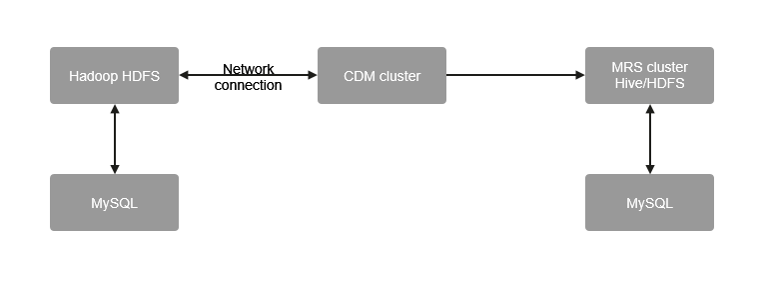
- Using BulkLoad to import data to HBase in batches
Organizations frequently encounter the need to ingest substantial volumes of data into HBase. While data can be loaded into HBase in batches by invoking the put method of HBase APIs or by leveraging MapReduce to load data from HDFS, these approaches can impose significant strain on RegionServers. This is due to the frequent flush, compaction, and split operations triggered by HBase, leading to high consumption of CPU and network resources and consequently, reduced efficiency. When operating within an MRS environment, utilizing the BulkLoad method for batch importing local data into HBase is strongly recommended. During the initial data loading phase, BulkLoad significantly enhances write efficiency and alleviates write pressure on the RegionServer nodes.
For details, see MRS Help Center.
- Migrating MySQL data to a Hive partition table in an MRS cluster
Hive partitions are implemented by using the HDFS subdirectory function. Each subdirectory contains the column names and values of each partition. If there are multiple partitions, there are many HDFS subdirectories. It is not easy to load external data to each partition of the Hive table without using tools. With CDM, you can easily load data of the external data sources (relational databases, object storage services, and file system services) to Hive partitioned tables.
For details, see MRS Help Center.
- Migrating data from MRS HDFS to OBS
CDM can migrate MRS HDFS data to OBS. For details, see MRS Help Center.
- Migrating tasks
Big data task migration involves the process of transferring big data workloads from one scheduling platform to another. This primarily encompasses JAR tasks, SQL tasks, and script tasks. The subsequent sections detail the migration procedures for these three task types.
- Migrating JAR tasks
To migrate JAR tasks effectively, a thorough understanding of the source code and dependency libraries of the original tasks is essential. The migration process necessitates recompiling the code to generate executable JAR files that are compatible with the target cloud environment. Following recompilation, comprehensive verification and optimization of these files are crucial to ensure proper functionality and performance within the new infrastructure. The steps are as follows:
Figure 4 JAR task migration process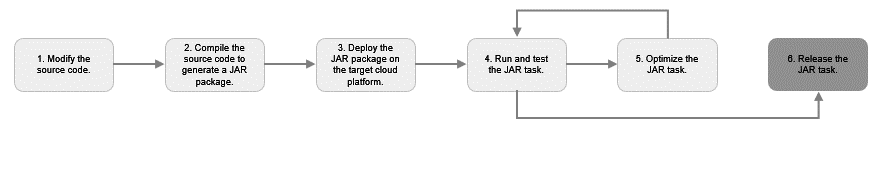
Prerequisite: Ensure that the data dependencies required for JAR task debugging have been successfully migrated to the cloud environment. Refer to the "Data Migration" section for detailed information on the data migration process.
- Adapt the source code to align with the big data resource configuration in the cloud environment. This includes adjusting parameters such as the version, dependency libraries, database connection strings, and library dependency configurations to match the cloud environment's specifications.
- Compile the modified source code to generate a JAR package that is executable within the cloud environment.
- Upload the generated JAR package to the task scheduling platform in the cloud. Subsequently, deploy and configure the JAR package.
- Execute the scheduled task and monitor its execution status and results by reviewing the generated logs.
- In the event that the task execution does not meet the expected outcomes (e.g., prolonged execution time), perform thorough root cause analysis. Based on the analysis, implement necessary optimizations and conduct further verification.
- Configure the scheduling parameters of the task based on the defined service requirements.
If you use DataArts Studio of Huawei Cloud as the big data task scheduling platform, you can configure JAR tasks by referring to DataArts Studio Help Center.
- Migrating SQL tasks
To migrate SQL tasks, you need to adapt and reconstruct SQL scripts. The following figure shows the migration process.
Figure 5 SQL task migration process
Prerequisite: Ensure that the data dependencies required for SQL task debugging have been successfully migrated to the cloud environment. Refer to the "Data Migration" section for detailed information on the data migration process.
- Export the source SQL script(s): Export the SQL script(s) from the source task scheduling platform.
- Modify the SQL script(s): Adapt the exported SQL script(s) to align with the specific syntax and resource configuration of the target cloud scheduling platform.
- Import the SQL script(s) to the target cloud platform: On the target cloud task scheduling platform, configure the necessary SQL tasks and import the modified SQL script(s).
- Run and test SQL tasks: Execute the configured SQL scheduling tasks and thoroughly monitor their execution status and output by reviewing the generated logs and execution results.
- Optimize SQL tasks: In the event that the task execution does not meet the expected outcomes (e.g., prolonged execution time), perform thorough root cause analysis. Based on the analysis, implement necessary optimizations and conduct further verification.
- Release SQL tasks: Configure scheduling tasks as required by services and configure correct task dependencies.
If you use DataArts Studio of Huawei Cloud as the big data task scheduling platform, you can develop and configure SQL jobs by referring to DataArts Studio Help Center.
- Migrating script tasks (Python and Shell)
When migrating script tasks, you also need to adapt to the cloud environment. The following figure shows the process.
Figure 6 Process of migrating script tasks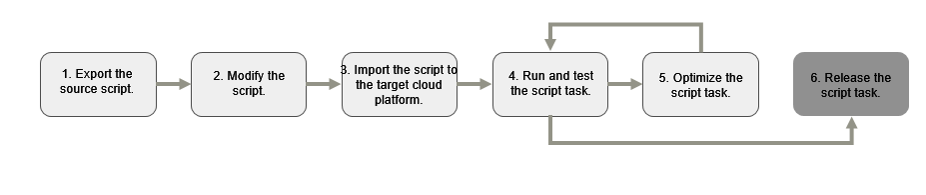
Prerequisite: Ensure that the data dependencies required for script task debugging have been successfully migrated to the cloud environment. Refer to the "Data Migration" section for detailed information on the data migration process.
- Export source scripts: Copy the executable scripts associated with the scheduling tasks from the source scheduling platform.
- Modify scripts: Adapt the copied scripts to align with the cloud environment's configuration. This includes adjusting parameters such as database connection strings, resource allocations, and output directory paths to match the cloud infrastructure.
- Import scripts to the target cloud platform: Upload the modified scripts to the target cloud scheduling platform and configure the corresponding script scheduling tasks within the platform.
- Run and test script tasks: Execute the configured scheduling tasks and thoroughly monitor the script's execution status and output by reviewing the generated logs and execution results.
- Optimize script tasks: In the event that the task execution does not meet the expected outcomes (e.g., prolonged execution time), perform thorough root cause analysis. Based on the analysis, implement necessary optimizations and conduct further verification.
- Release script tasks: Configure scheduling tasks as required by services and configure correct task dependencies.
If you use DataArts Studio of Huawei Cloud as the big data task scheduling platform, you can develop and configure Shell and Python scripts by referring to DataArts Studio Help Center.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



