
O que fazer se o agendamento do pod falhar?
Localização de falha
Se o pod estiver no estado Pending e o evento contiver informações de falha de agendamento do pod, localize a causa com base nas informações do evento. Para obter detalhes sobre como exibir eventos, consulte Como usar eventos para corrigir cargas de trabalho anormais?.
Processo de solução de problemas
Determine a causa com base nas informações do evento, conforme listado em Tabela 1.
| Informações sobre o evento | Causa e solução |
|---|---|
| no nodes available to schedule pods. | Nenhum nó está disponível no cluster. |
| 0/2 nodes are available: 2 Insufficient cpu. 0/2 nodes are available: 2 Insufficient memory. | Os recursos do nó (CPU e memória) são insuficientes. Item de verificação 2: se os recursos do nó (CPU e memória) são suficientes |
| 0/2 nodes are available: 1 node(s) didn't match node selector, 1 node(s) didn't match pod affinity rules, 1 node(s) didn't match pod affinity/anti-affinity. | As configurações de afinidade node e pod são mutuamente exclusivas. Nenhum nó atende aos requisitos do pod. Item de verificação 3: configuração de afinidade e anti-afinidade da carga de trabalho |
| 0/2 nodes are available: 2 node(s) had volume node affinity conflict. | O volume do EVS montado no pod e no nó não estão na mesma AZ. Item de verificação 4: se o volume e o nó da carga de trabalho residem na mesma AZ |
| 0/1 nodes are available: 1 node(s) had taints that the pod didn't tolerate. | Taints existem no nó, mas a vagem não pode tolerar essas manchas. |
| 0/7 nodes are available: 7 Insufficient ephemeral-storage. | O espaço de armazenamento efêmero do nó é insuficiente. |
| 0/1 nodes are available: 1 everest driver not found at node | O everest-csi-driver no nó não está no estado de execução. |
| Failed to create pod sandbox: ... Create more free space in thin pool or use dm.min_free_space option to change behavior | O espaço de thin pool do nó é insuficiente. |
Item de verificação 1: se um nó está disponível no cluster
Efetue logon no console do CCE e verifique se o status do nó está Available. Como alternativa, execute o seguinte comando para verificar se o status do nó é Ready:
$ kubectl get node NAME STATUS ROLES AGE VERSION 192.168.0.37 Ready <none> 21d v1.19.10-r1.0.0-source-121-gb9675686c54267 192.168.0.71 Ready <none> 21d v1.19.10-r1.0.0-source-121-gb9675686c54267
Se o status de todos os nós for Not Ready, nenhum nó estará disponível no cluster.
Solução
- Adicione um nó. Se uma política de afinidade não estiver configurada para a carga de trabalho, o pod será migrado automaticamente para o novo nó para garantir que os serviços estejam sendo executados corretamente.
- Localize o nó indisponível e corrija a falha. Para mais detalhes, consulte O que fazer se um cluster estiver disponível, mas alguns nós não estiverem disponíveis?.
- Redefina o nó indisponível. Para obter detalhes, consulte Redefinição de um nó.
Item de verificação 2: se os recursos do nó (CPU e memória) são suficientes
0/2 nodes are available: 2 Insufficient cpu. Isso significa CPUs insuficientes.
0/2 nodes are available: 2 Insufficient memory. Isso significa memória insuficiente.
Se os recursos solicitados pelo pod excederem os recursos alocáveis do nó em que o pod é executado, o nó não poderá fornecer os recursos necessários para executar novos pods e o agendamento do pod no nó definitivamente falhará.
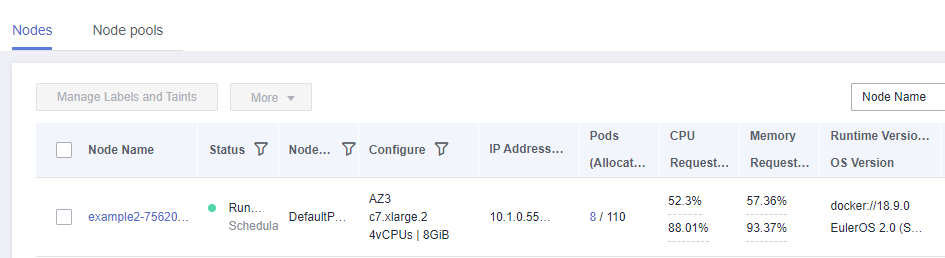
Se o número de recursos que podem ser alocados a um nó for menor que o número de recursos solicitados por um pod, o nó não atenderá aos requisitos de recursos do pod. Como resultado, o agendamento falha.
Solução
Adicione nós ao cluster. Expansão é a solução comum para recursos insuficientes.
Item de verificação 3: configuração de afinidade e anti-afinidade da carga de trabalho
Políticas de afinidade inapropriadas farão com que o agendamento de pod falhe.
Exemplo:
Estabelece-se uma relação anti-afinidade entre a carga de trabalho 1 e a carga de trabalho 2. A carga de trabalho 1 é implementada no nó 1, enquanto a carga de trabalho 2 é implementada no nó 2.
Quando você tenta implementar a carga de trabalho 3 no nó 1 e estabelece uma relação de afinidade com a carga de trabalho 2, ocorre um conflito, resultando em uma falha de implementação da carga de trabalho.
0/2 nodes are available: 1 node(s) didn't match node selector, 1 node(s) didn't match pod affinity rules, 1 node(s) didn't match pod affinity/anti-affinity.
- node selector indica que a afinidade de nó não é atendida.
- pod affinity rules do pod indicam que a afinidade do pod não é atendida.
- pod affinity/anti-affinity indica que a afinidade/anti-afinidade do pod não é satisfeita.
Solução
- Ao adicionar políticas de afinidade de carga de trabalho à carga de trabalho e afinidade de nó à carga de trabalho, certifique-se de que os dois tipos de políticas não entrem em conflito. Caso contrário, a implementação da carga de trabalho falhará.
- Se a carga de trabalho tiver uma política de afinidade de nó, certifique-se de que supportContainer no rótulo do nó de afinidade esteja definido como true. Caso contrário, os pods não podem ser agendados no nó de afinidade e o seguinte evento é gerado:
No nodes are available that match all of the following predicates: MatchNode Selector, NodeNotSupportsContainer
Se o valor for false, o agendamento falhará.
Item de verificação 4: se o volume e o nó da carga de trabalho residem na mesma AZ
0/2 nodes are available: 2 node(s) had volume node affinity conflict. Ocorre um conflito de afinidade entre volumes e nós. Como resultado, o agendamento falha.
Isso ocorre porque os discos EVS não podem ser anexados a nós em AZs. Por exemplo, se o volume do EVS estiver localizado em AZ 1 e o nó estiver localizado em AZ 2, a programação falhará.
O volume do EVS criado no CCE tem configurações de afinidade por padrão, conforme mostrado abaixo.
kind: PersistentVolume apiVersion: v1 metadata: name: pvc-c29bfac7-efa3-40e6-b8d6-229d8a5372ac spec: ... nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: failure-domain.beta.kubernetes.io/zone operator: In values: - ap-southeast-1a
Solução
Na AZ onde reside o nó da carga de trabalho, crie um volume. Como alternativa, crie uma carga de trabalho idêntica e selecione um volume de armazenamento em nuvem atribuído automaticamente.
Item de verificação 5: tolerância de taint de pods
0/1 nodes are available: 1 node(s) had taints that the pod didn't tolerate. Isso significa que o nó está contaminado e o pod não pode ser agendado para o nó.
Verifique os taints no nó. Se as seguintes informações forem exibidas, existem taints no nó:
$ kubectl describe node 192.168.0.37
Name: 192.168.0.37
...
Taints: key1=value1:NoSchedule
... Em alguns casos, o sistema adiciona automaticamente um taint a um nó. As manchas embutidas atuais incluem:
- node.kubernetes.io/not-ready: o nó não está pronto.
- node.kubernetes.io/unreachable: o controlador de nó não pode acessar o nó.
- node.kubernetes.io/memory-pressure: o nó tem estresse de memória.
- node.kubernetes.io/disk-pressure: o nó tem pressão de disco. Siga as instruções descritas em Item de verificação 4: se o espaço de disco do nó é insuficiente para lidar com isso.
- node.kubernetes.io/pid-pressure: o nó está sob pressão de PID. Siga as instruções em Alteração de limites de ID do processo (kernel.pid_max) para lidar com isso.
- node.kubernetes.io/network-unavailable: o nó da rede não está indisponível.
- node.kubernetes.io/unschedulable: o nó não pode ser agendado.
- node.cloudprovider.kubernetes.io/uninitialized: se um driver de plataforma de nuvem externa for especificado quando o kubelet for iniciado, o kubelet adicionará um taint ao nó atual e o marcará como indisponível. Depois que o cloud-controller-manager inicializa o nó, o kubelet exclui o taint.
Solução
Para programar o pod para o nó, use um dos seguintes métodos:
- Se o taint for adicionado por um usuário, você poderá excluir o taint no nó. Se o taint for adicionado automaticamente pelo sistema, o taint será automaticamente excluído após a falha ser corrigida.
- Especifique uma tolerância para o pod que contém o taint. Para obter detalhes, consulte Taints e tolerâncias.
apiVersion: v1 kind: Pod metadata: name: nginx spec: containers: - name: nginx image: nginx:alpine tolerations: - key: "key1" operator: "Equal" value: "value1" effect: "NoSchedule"
Item de verificação 6: uso de volume efêmero
0/7 nodes are available: 7 Insufficient ephemeral-storage. Isso significa armazenamento efêmero insuficiente do nó.
Verifique se o tamanho do volume efêmero no pod é limitado. Se o tamanho do volume efêmero exigido pela aplicação exceder a capacidade existente do nó, a aplicação não poderá ser agendada. Para resolver esse problema, altere o tamanho do volume efêmero ou expanda a capacidade do disco do nó.
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
ephemeral-storage: "2Gi"
limits:
ephemeral-storage: "4Gi"
volumeMounts:
- name: ephemeral
mountPath: "/tmp"
volumes:
- name: ephemeral
emptyDir: {} Item de verificação 7: se o everest funciona corretamente
0/1 nodes are available: 1 everest driver not found at node. Isso significa que o everest-csi-driver do everest não é iniciado corretamente no nó.
Verifique o daemon chamado everest-csi-driver no namespace de kube-system e verifique se o pod foi iniciado corretamente. Se não, exclua o pod. O daemon reiniciará o pod.
Item de verificação 8: espaço de thin pool
Um disco de dados de 100 GB dedicado para o Docker é anexado ao novo nó. Para obter detalhes, consulte Alocação de espaço de disco de dados. Se o espaço em disco de dados for insuficiente, o pod não poderá ser criado.
Solução 1
Você pode executar o seguinte comando para limpar imagens do Docker não utilizadas:
docker system prune -a
Esse comando excluirá todas as imagens do Docker que não forem usadas temporariamente. Tenha cuidado ao executar este comando.
Solução 2
Como alternativa, você pode expandir a capacidade do disco. O procedimento é o seguinte:
- Expanda a capacidade de um disco de dados no console do EVS. Para obter detalhes, consulte Expansão da capacidade de disco do EVS.
Somente a capacidade de armazenamento do disco EVS é expandida. Você também precisa executar as etapas a seguir para expandir a capacidade do volume lógico e do sistema de arquivos.
- Efetue logon no console do CCE e clique no cluster. No painel de navegação, escolha Nodes. Clique em More > Sync Server Data na linha que contém o nó de destino.
- Faça logon no nó de destino.
- Execute o comando lsblk para verificar as informações do dispositivo de bloco do nó.
Um disco de dados é dividido dependendo do armazenamento do contêiner Rootfs:
Overlayfs: nenhum thin pool independente é alocado. Os dados da imagem são armazenados no dockersys.
- Verifique os tamanhos do disco e da partição do dispositivo.
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 50G 0 disk └─sda1 8:1 0 50G 0 part / sdb 8:16 0 150G 0 disk # The data disk has been expanded to 150 GiB, but 50 GiB space is not allocated. ├─vgpaas-dockersys 253:0 0 90G 0 lvm /var/lib/containerd └─vgpaas-kubernetes 253:1 0 10G 0 lvm /mnt/paas/kubernetes/kubelet
- Expanda a capacidade do disco.
Adicione a nova capacidade de disco ao volume lógico dockersys usado pelo mecanismo de contêiner.
- Expanda a capacidade do PV para que o LVM possa identificar a nova capacidade do EVS. /dev/sdb especifica o volume físico onde o dockersys está localizado.
pvresize /dev/sdbInformação semelhante à seguinte é exibida:
Physical volume "/dev/sdb" changed 1 physical volume(s) resized or updated / 0 physical volume(s) not resized
- Expanda 100% da capacidade livre para o volume lógico. vgpaas/dockersys especifica o volume lógico usado pelo mecanismo de contêiner.
lvextend -l+100%FREE -n vgpaas/dockersysInformação semelhante à seguinte é exibida:
Size of logical volume vgpaas/dockersys changed from <90.00 GiB (23039 extents) to 140.00 GiB (35840 extents). Logical volume vgpaas/dockersys successfully resized.
- Ajuste o tamanho do sistema de arquivos. /dev/vgpaas/dockersys especifica o caminho do sistema de arquivos do mecanismo de contêiner.
resize2fs /dev/vgpaas/dockersysInformação semelhante à seguinte é exibida:
Filesystem at /dev/vgpaas/dockersys is mounted on /var/lib/containerd; on-line resizing required old_desc_blocks = 12, new_desc_blocks = 18 The filesystem on /dev/vgpaas/dockersys is now 36700160 blocks long.
- Expanda a capacidade do PV para que o LVM possa identificar a nova capacidade do EVS. /dev/sdb especifica o volume físico onde o dockersys está localizado.
- Verifique se a capacidade está expandida.
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 50G 0 disk └─sda1 8:1 0 50G 0 part / sdb 8:16 0 150G 0 disk ├─vgpaas-dockersys 253:0 0 140G 0 lvm /var/lib/containerd └─vgpaas-kubernetes 253:1 0 10G 0 lvm /mnt/paas/kubernetes/kubelet
- Verifique os tamanhos do disco e da partição do dispositivo.




