

使用CDM服务迁移MySQL数据至MRS Hive
应用场景
云数据迁移(Cloud Data Migration,简称CDM),是一种高效、易用的批量数据迁移服务。 CDM围绕大数据迁移上云和智能数据湖解决方案,提供了简单易用的迁移能力和多种数据源到数据湖的集成能力,降低了客户数据源迁移和集成的复杂性,有效地提高您数据迁移和集成的效率。
Hive的分区使用HDFS的子目录功能实现,每一个子目录包含了分区对应的列名和每一列的值。当分区很多时,会有很多HDFS子目录,如果不依赖工具,将外部数据加载到Hive表各分区不是一件容易的事情。
云数据迁移服务可以轻松将外部数据源(关系数据库、对象存储服务、文件系统服务等)加载到Hive分区表。
本实践为您演示使用CDM云服务将MySQL数据导入到MRS集群内的Hive分区表中,流程如下:

前提条件
- 已经购买包含有Hive服务的MRS集群。
- 已获取连接MySQL数据库的IP地址、端口、数据库名称、用户名、密码,且该用户拥有MySQL数据库的读写权限。
- 已参考管理驱动,上传了MySQL数据库驱动。
步骤1:在MRS Hive上创建Hive分区表
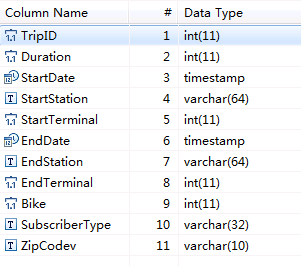
- 假设MySQL数据库中有一张表“trip_data”,保存了自行车骑行记录,里面有起始时间、结束时间,起始站点、结束站点、骑手ID等信息。
“trip_data”表字段定义如图2所示。
- 在MRS的Hive客户端中,执行以下SQL语句创建一张Hive分区表,表名与MySQL上的表trip_data一致,且Hive表比MySQL表多建三个字段y、ym、ymd,作为Hive的分区字段。 SQL语句如下:
1create table trip_data(TripID int,Duration int,StartDate timestamp,StartStation varchar(64),StartTerminal int,EndDate timestamp,EndStation varchar(64),EndTerminal int,Bike int,SubscriberType varchar(32),ZipCodev varchar(10))partitioned by (y int,ym int,ymd int);

步骤3:创建MySQL连接
- 在CDM集群管理界面,单击集群后的“作业管理”,选择,进入连接器类型的选择界面。 图4 选择连接器类型

- 选择“MySQL”后单击“下一步”,配置MySQL连接的参数。
单击“显示高级属性”可查看更多可选参数,具体请参见配置关系数据库连接。此处保持默认,必填参数如表1所示。
表1 MySQL连接参数 参数名
说明
取值样例
名称
输入便于记忆和区分的连接名称。
mysqllink
数据库服务器
MySQL数据库的IP地址或域名。
192.168.1.110
端口
MySQL数据库的端口。
3306
数据库名称
MySQL数据库的名称。
sqoop
用户名
拥有MySQL数据库的读、写和删除权限的用户。
admin
密码
用户的密码。
-
使用Agent
是否选择通过Agent从源端提取数据。
是
Agent
单击“选择”,选择已创建的Agent。
-
图5 创建MySQL连接
- 单击“保存”回到连接管理界面。

如果保存时出错,一般是由于MySQL数据库的安全设置问题,需要设置允许CDM集群的EIP访问MySQL数据库。
步骤4:创建Hive连接
- 在连接管理界面,单击“新建连接”,连接器类型选择“MRS Hive”。
- 单击“下一步”配置Hive连接参数,如图6所示。
各参数说明如表2所示,需要您根据实际情况配置。
表2 MRS Hive连接参数 参数名
说明
取值样例
名称
连接的名称,根据连接的数据源类型,用户可自定义便于记忆、区分的连接名。
hivelink
Manager IP
MRS Manager的浮动IP地址,可以单击输入框后的“选择”来选定已创建的MRS集群,CDM会自动填充下面的鉴权参数。
127.0.0.1
认证类型
访问MRS的认证类型:- SIMPLE:非安全模式选择Simple鉴权。
- KERBEROS:安全模式选择Kerberos鉴权。
SIMPLE
Hive版本
Hive的版本。根据服务端Hive版本设置。
HIVE_3_X
用户名
选择KERBEROS鉴权时,需要配置MRS Manager的用户名和密码。从HDFS导出目录时,如果需要创建快照,这里配置的用户需要HDFS系统的管理员权限。
如果要创建MRS安全集群的数据连接,不能使用admin用户。因为admin用户是默认的管理页面用户,这个用户无法作为安全集群的认证用户来使用。您可以创建一个新的MRS用户,然后在创建MRS数据连接时,“用户名”和“密码”填写为新建的MRS用户及其密码。说明:- 如果CDM集群为2.9.0版本及之后版本,且MRS集群为3.1.0及之后版本,则所创建的用户至少需具备Manager_viewer的角色权限才能在CDM创建连接;如果需要对应组件的进行库、表、数据的操作,还需要添加对应组件的用户组权限。
- 如果CDM集群为2.9.0之前的版本,或MRS集群为3.1.0之前的版本,则所创建的用户需要具备Manager_administrator或System_administrator权限,才能在CDM创建连接。
- 仅具备Manager_tenant或Manager_auditor权限,无法创建连接。
cdm
密码
访问MRS Manager的用户密码。
-
OBS支持
需服务端支持OBS存储。在创建Hive表时,您可以指定将表存储在OBS中。
否
运行模式
EMBEDDED
是否使用集群配置
您可以通过使用集群配置,简化Hive连接参数配置。
否
集群配置名
仅当“是否使用集群配置”为“是”时,此参数有效。此参数用于选择用户已经创建好的集群配置。
集群配置的创建方法请参见管理集群配置。
hive_01
- 单击“保存”回到连接管理界面。

步骤5:创建迁移作业
- 在CDM集群管理界面,单击集群后的“作业管理”,选择,开始创建数据迁移任务,如图7所示。
“导入前清空数据”选“是”,这样每次导入前,会将之前已经导入到Hive表的数据清空。
- 作业参数配置完成后,单击“下一步”,进入字段映射界面,如图8所示。
映射MySQL表和Hive表字段,Hive表比MySQL表多三个字段y、ym、ymd,即是Hive的分区字段。由于没有源表字段直接对应,需要配置表达式从源表的StartDate字段抽取。
- 单击
 进入转换器列表界面,再选择。
进入转换器列表界面,再选择。 y、ym、ymd字段的表达式分别配置如下:
DateUtils.format(DateUtils.parseDate(row[2],"yyyy-MM-dd HH:mm:ss.SSS"),"yyyy")
DateUtils.format(DateUtils.parseDate(row[2],"yyyy-MM-dd HH:mm:ss.SSS"),"yyyyMM")
DateUtils.format(DateUtils.parseDate(row[2],"yyyy-MM-dd HH:mm:ss.SSS"),"yyyyMMdd")
- 单击“下一步”配置任务参数,一般情况下全部保持默认即可。 该步骤用户可以配置如下可选功能:
- 作业失败重试:如果作业执行失败,可选择是否自动重试,这里保持默认值“不重试”。
- 作业分组:选择作业所属的分组,默认分组为“DEFAULT”。在CDM“作业管理”界面,支持作业分组显示、按组批量启动作业、按分组导出作业等操作。
- 是否定时执行:如果需要配置作业定时自动执行,请参见配置定时任务。这里保持默认值“否”。
- 抽取并发数:设置同时执行的抽取任务数。这里保持默认值“1”。
- 是否写入脏数据:如果需要将作业执行过程中处理失败的数据、或者被清洗过滤掉的数据写入OBS中,以便后面查看,可通过该参数配置,写入脏数据前需要先配置好OBS连接。这里保持默认值“否”即可,不记录脏数据。
- 作业运行完是否删除:这里保持默认值“不删除”。
- 单击“保存并运行”,回到作业管理界面,在作业管理界面可查看作业执行进度和结果。
- 作业执行成功后,单击作业操作列的“历史记录”,可查看该作业的历史执行记录、读取和写入的统计数据。
在历史记录界面单击“日志”,可查看作业的日志信息。






