

在Standard上部署SD WebUI推理服务
本文档主要介绍如何在ModelArts Standard的推理环境上部署Stable Diffusion的WebUI套件,使用NPU卡进行推理。
完成在DevServer上部署SD WebUI推理服务章节的任务后,如果还需要在ModelArts的推理生产环境(ModelArts控制台的在线服务模块)中部署推理服务,可参考下述步骤。
Step1 导出镜像
完成在DevServer上部署SD WebUI推理服务章节的任务后,在宿主机上执行以下命令,导出镜像。
docker commit ${container_name} sdxl-train:0.0.1
Step2 创建镜像组织
在SWR服务页面创建镜像组织。

Step3 在宿主机上传镜像到SWR
在SWR中单击右上角的“登录指令”,然后在跳出的登录指定窗口,单击复制临时登录指令。在创建的ECS中复制临时登录指令,即可完成登录。
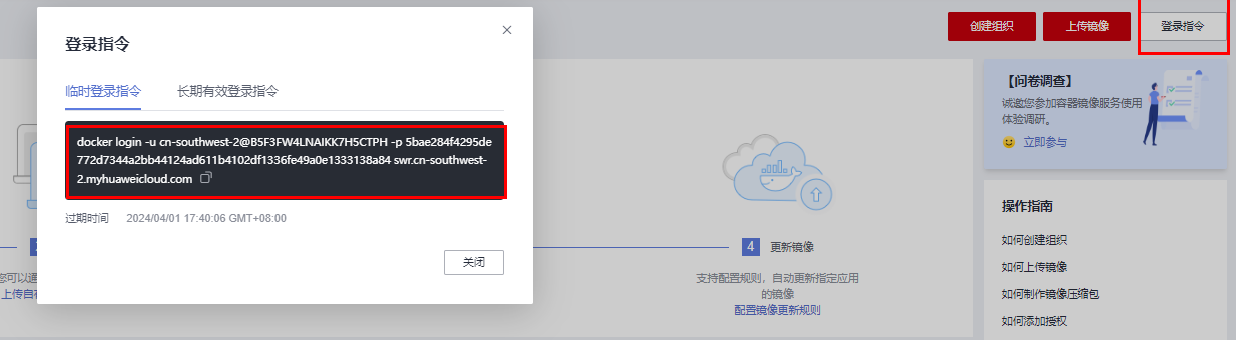
登录指令输入之后,使用下列示例命令:
docker tag sdxl-train:0.0.1 <镜像仓库地址>/<组织名称>/<镜像名称>:<版本名称> docker push <镜像仓库地址>/<组织名称>/<镜像名称>:<版本名称>
参数说明:
- <镜像仓库地址>:可在SWR控制台上查询,容器镜像服务中登录指令末尾的域名即为镜像仓库地址。
- <组织名称>:前面步骤中自己创建的组织名称。示例:ma-group
- <镜像名称>:<版本名称>:定义镜像名称。示例:sdxl-train:0.0.1
以贵阳一的SWR为例:
docker tag sdxl-train:0.0.1 swr.cn-southwest-2.myhuaweicloud.com/ma-group/sdxl-train:0.0.1 docker push swr.cn-southwest-2.myhuaweicloud.com/ma-group/sdxl-train:0.0.1
Step4 创建AI应用
在ModelArts的AI应用页面,进行AI应用创建。
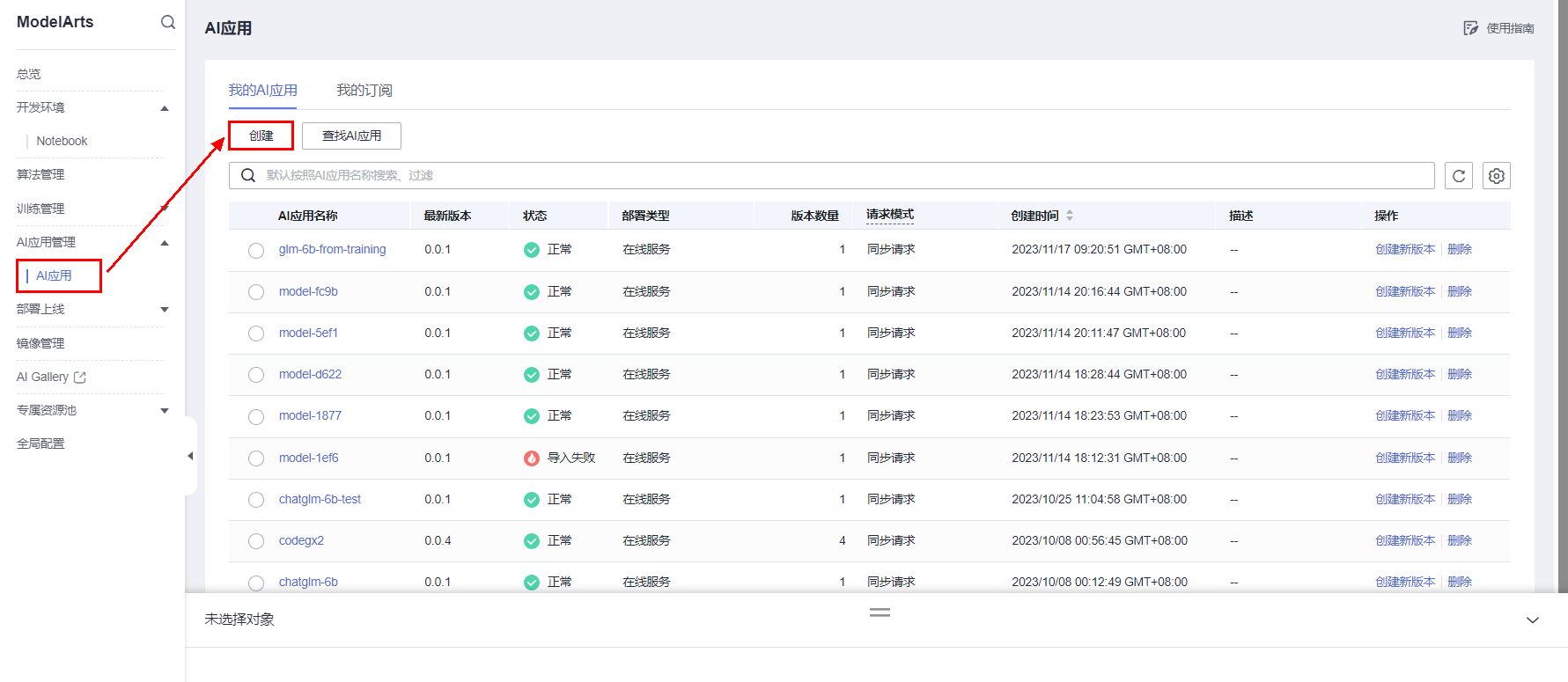
填写如下参数信息。
- 名称:AI应用的名称,请按照实际应用名填写。
- 版本:版本描述,请按照实际填写。
- 元模型来源:注意此处选择“从容器镜像选择”。
- 容器镜像所在路径:单击文件夹标签,选择已经制作好的镜像。
- 容器调用接口参数:根据镜像实际提供的协议和端口填写,本案例中的SDXL镜像提供HTTP服务和8183端口。
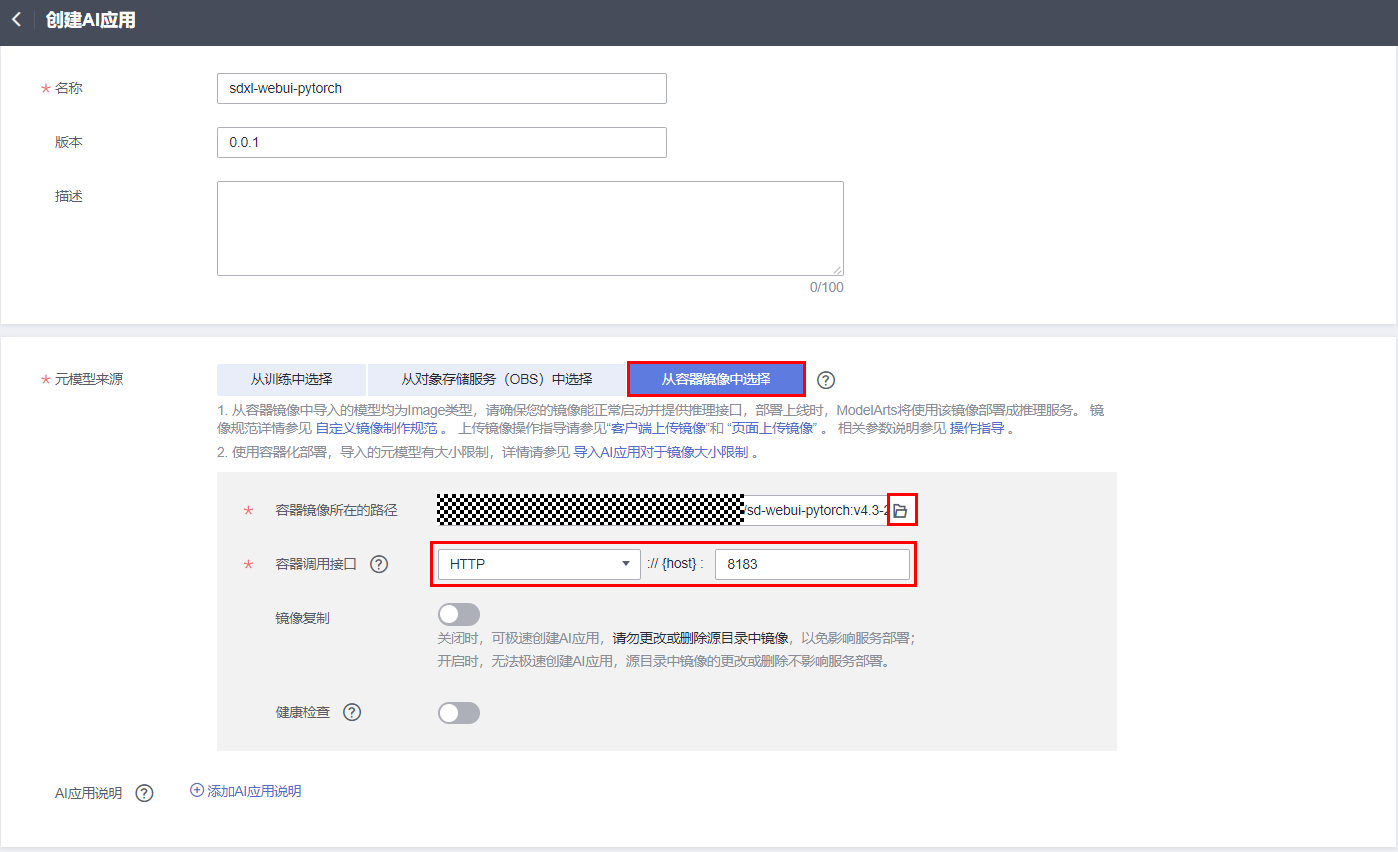
- 系统运行架构: 选择ARM.
- 推理加速卡:无。
- 部署类型: 在线服务。
- 请求模式:同步请求。
- 启动命令:
source /etc/bashrc && python3 launch.py --skip-torch-cuda-test --port 8183 --enable-insecure-extension-access --listen --log-startup --disable-safe-unpickle --skip-prepare-environment --api
按照上述配置完参数后,单击右下角的立即创建, 完成AI应用的创建。
当AI应用状态变为正常时,表示创建完成。
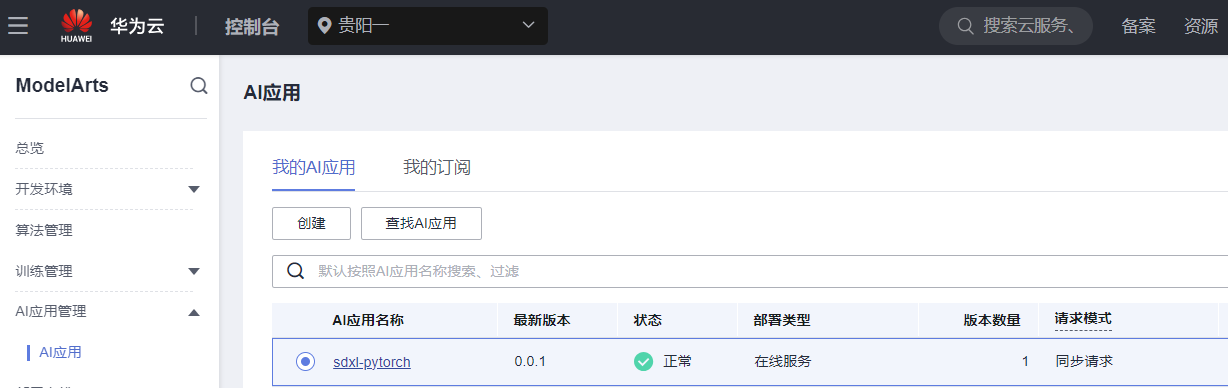
Step5 部署服务
单击AI应用名称,进入AI应用详情页,单击部署在线服务。
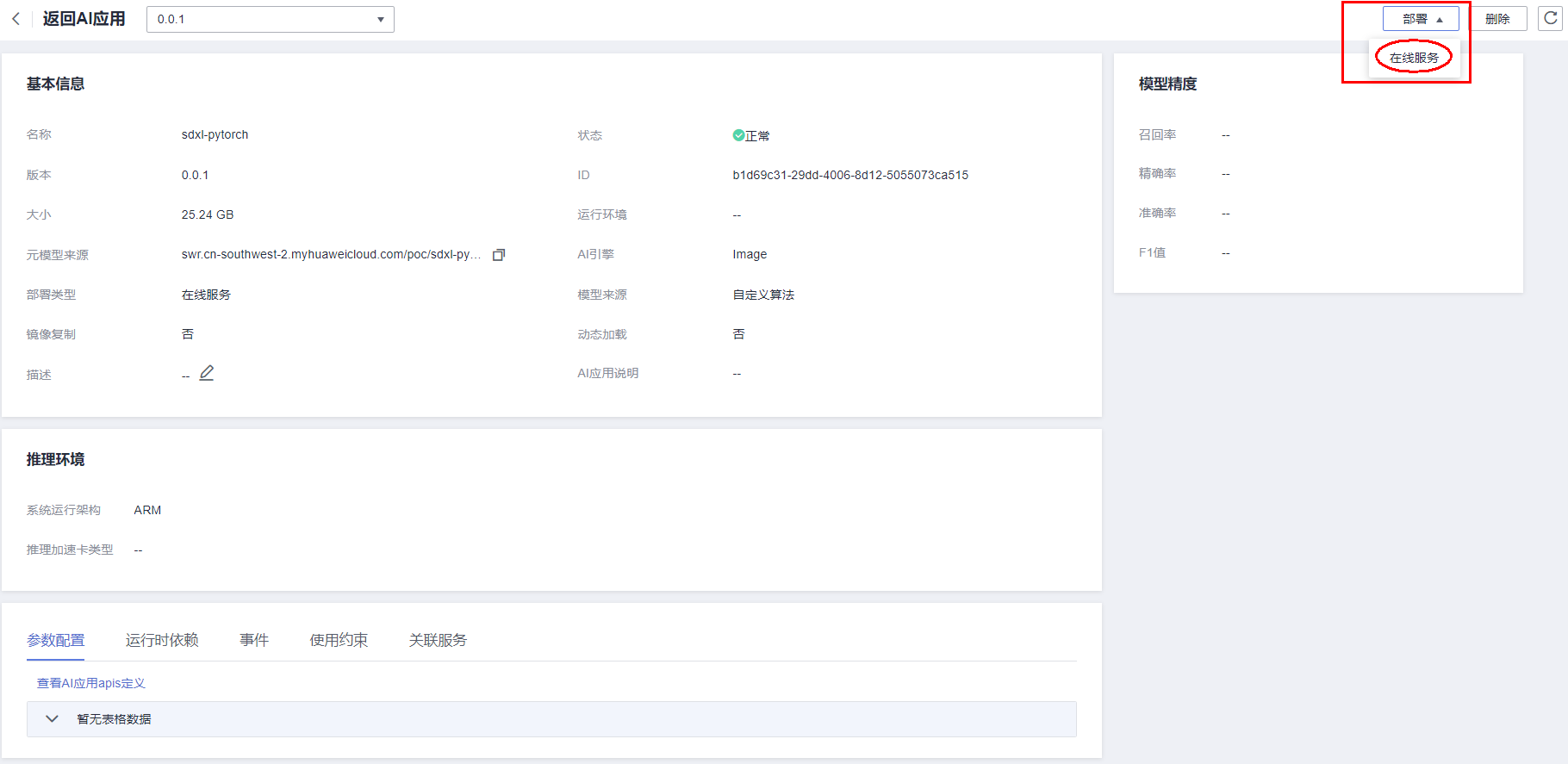
填写如下服务部署参数。
- 名称: 服务的名称,按照实际需要填写
- 是否自动停止:如果配置自动停止,服务会按照配置的时间自动停止。如果需要常驻的服务,建议关掉该按钮。
- 描述:按照需要填写。
- 资源池:选择专属资源池。若之前未购买专属资源池,具体步骤请参考创建资源池。
资源规格要求:
- 硬盘空间:至少200GB。
- 昇腾资源规格:可以申请Ascend: 1* ascend-snt9b(32GB)或Ascend: 1* ascend-snt9b(64GB)规格。请按需选择需要的规格,64GB规格的推理耗时更短。
- 推荐使用“西南-贵阳一”Region上的昇腾资源。
- AI应用来源: 我的AI应用。
- 选择AI应用及其版本:此处选择上一步中创建的sdxl-webui-pytorch:0.0.1应用。
- 计算节点规格: 按需选择Ascend: 1* ascend-snt9b(32GB)或Ascend: 1* ascend-snt9b(64GB)。
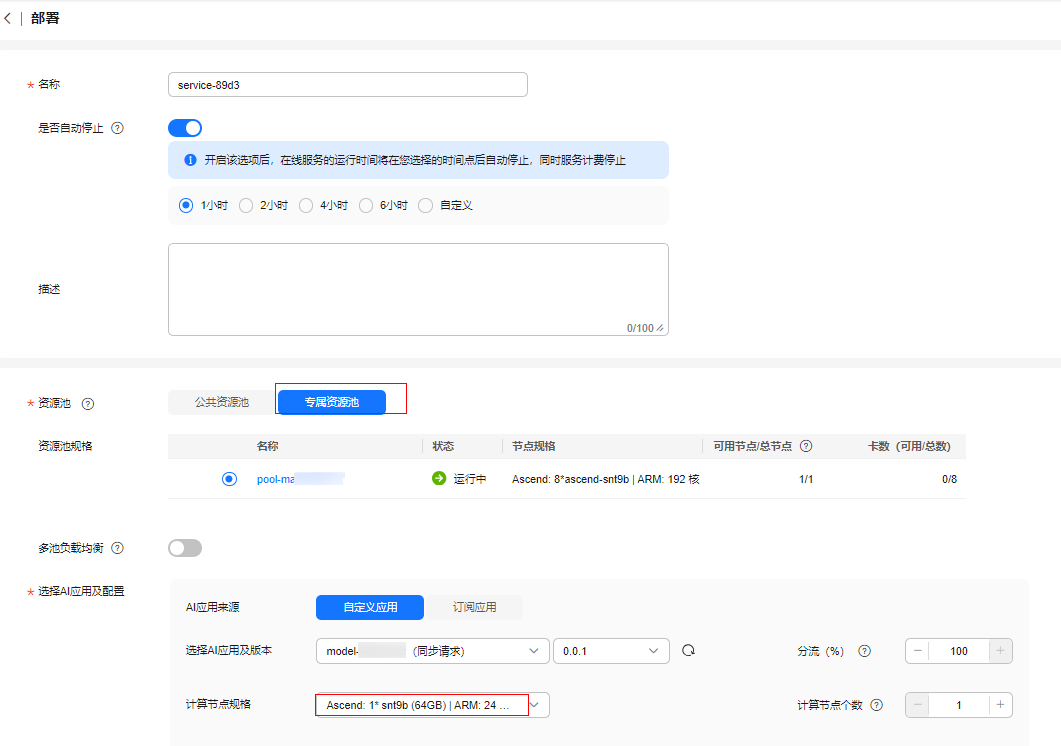
选择开启APP认证并选择应用。
按照上述配置完参数后,单击“下一步”, 确认信息无误后,单击“提交”,完成服务的部署。
Step6 访问在线服务
在Chrome浏览器中安装ModHeader插件。

Chrome浏览器安装ModHeader插件后,可能会导致访问不了ModelArts平台,访问ModelArts时需要临时禁用ModHeader插件。或者使用Edge登录ModelArts,使用Chrome安装插件访问页面。
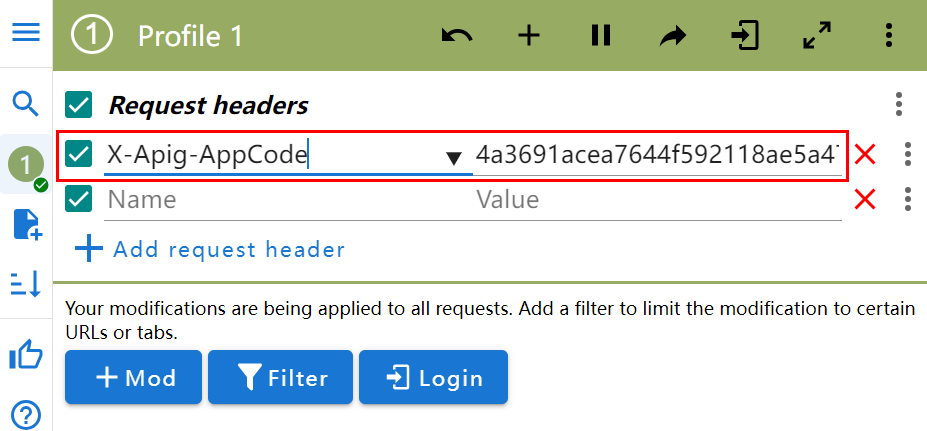
打开ModHeader,单击添加MOD。
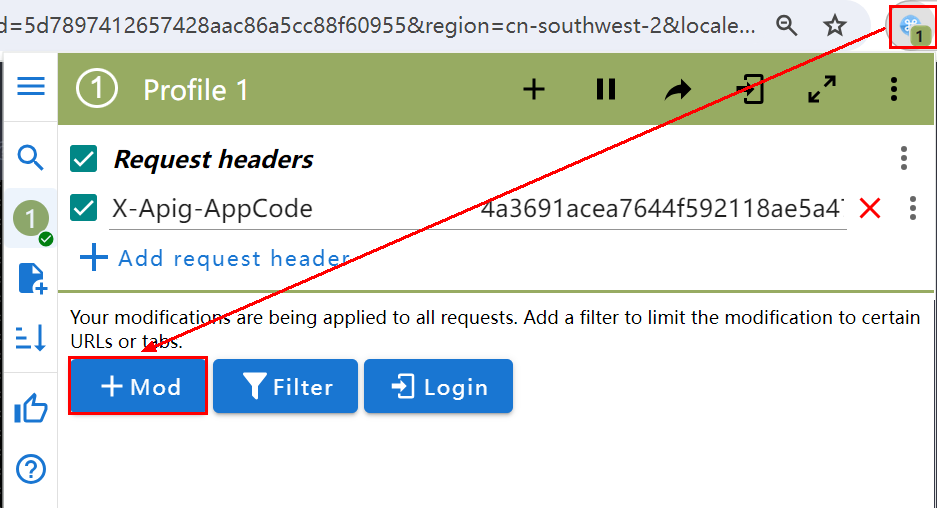
选择添加Request header。
进入在线服务详情,查看Key值和Value值。
Key值固定为X-Apig-AppCode,Value值为APP认证的app_code值,在服务调用指南tab的APP认证API处展开,进行AppCode管理设置。
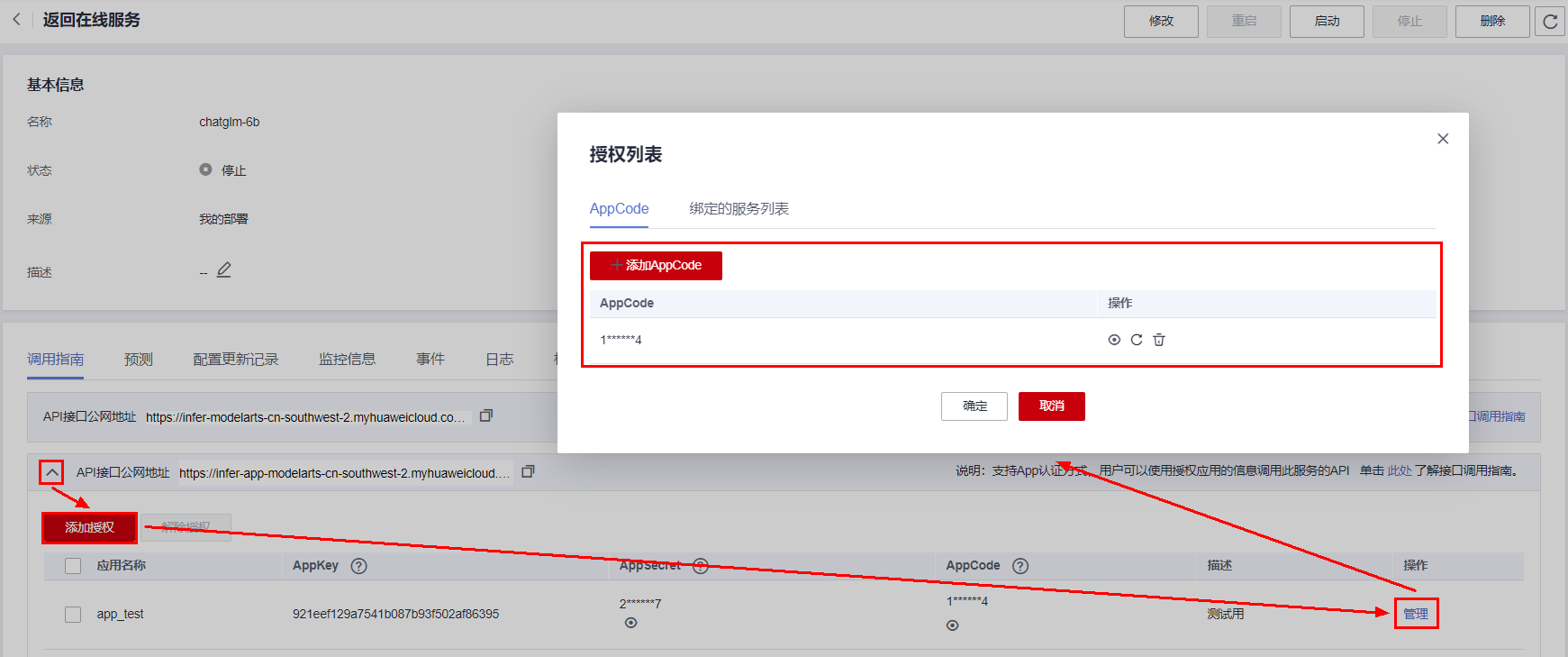
将在ModHeader插件中添加Key值和Value值。
进入在线服务详情页,查看APP认证方式的服务API。
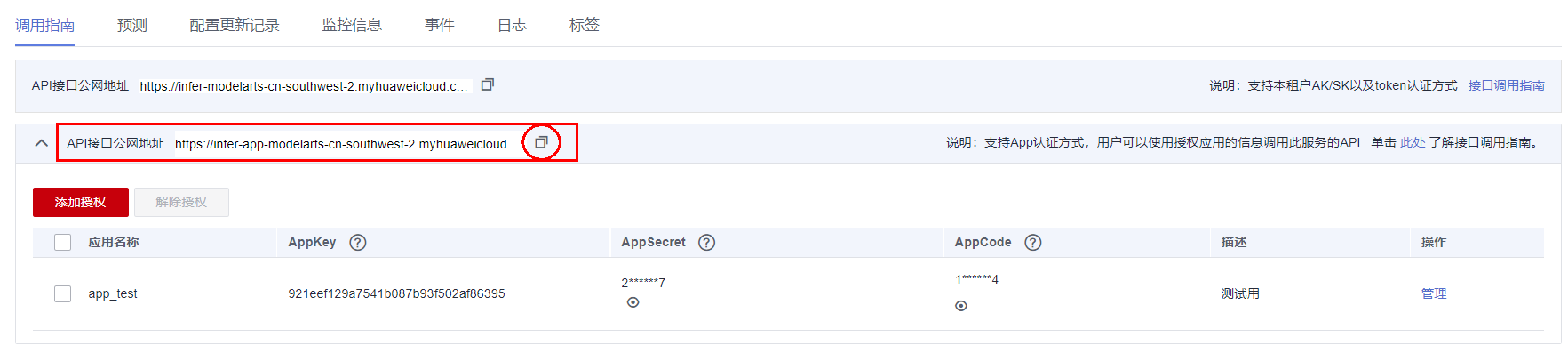
复制API接口公网地址,并在地址后添加"/",进行页面访问,例如:
https://infer-app-modelarts-cn-southwest-2.myhuaweicloud.com/v1/infers/abc104bb-d303-4ffb-a8fa-XXXXXXXXX/
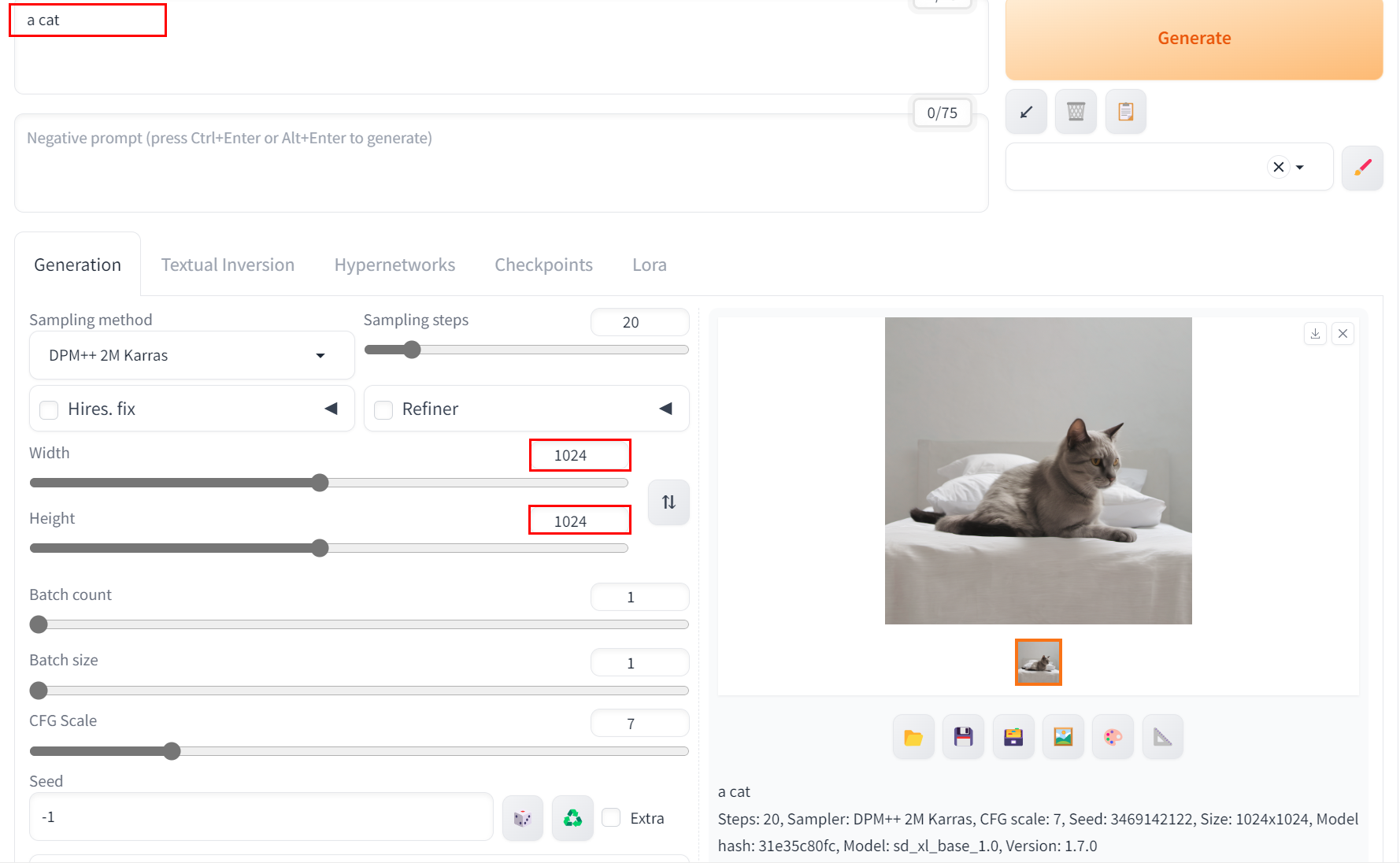
输入Promt,修改所需要的请求参数(如Width、Height),进行Promt请求。
|
参数名称 |
说明 |
是否必选 |
默认值 |
|---|---|---|---|
|
prompt |
提示词,根据提示词生成含有对应内容的图像 |
是 |
无 |
|
negative_prompt |
反向提示词,图像生成过程中应避免的提示 |
否 |
无 |
|
num_inference_steps |
推理步骤数,控制推理的步数 |
否 |
40 |
|
height |
生成图像的纵向分辨率 |
否 |
1024 |
|
width |
生成图像的横向分辨率 |
否 |
1024 |
|
high_noise_frac |
高噪声比例,即基础模型跑的步数占总步数的比例 |
否 |
0.8 |
|
refiner_switch |
是否使用细化模型refiner |
否 |
true(使用) |
|
seed |
随机种子,控制生成图像的多样性 |
否 |
无 |
您可在ModelArts控制台查看相关日志。

首次请求时会进行模型加载,耗时较长,因此第一个请求可能超时,第二个请求将会正常,请耐心等待。





