

数据dump指导
msprobe是MindStudio Training Tools工具链下精度调试部分的工具包,主要包括精度预检、溢出检测、精度比对和梯度监控等功能,目前适配PyTorch和MindSpore框架。这些子工具侧重不同的训练场景,可以定位模型训练中的精度问题。
前提条件
- 已安装msprobe工具,建议使用官方支持的版本。
- 具备相应的系统权限,可执行数据dump操作。
- 了解msprobe工具的基本工作原理和相关数据结构。
在代码中添加dump配置
下文以一个简单的训练网络为例,说明如何在代码中添加dump配置。
import torch
import torch.nn as nn
import torch.nn.functional as F
# 导入工具的数据采集接口。
from msprobe.pytorch import PrecisionDebugger, seed_all
# 在模型训练开始前固定随机性。
seed_all()
# 在模型训练开始前实例化PrecisionDebugger
debugger = PrecisionDebugger(config_path='./config.json')
# 定义网络。
class ModuleOP(nn.Module):
def __init__(self) -> None:
super().__init__()
self.linear_1 = nn.Linear(in_features=8, out_features=4)
self.linear_2 = nn.Linear(in_features=4, out_features=2)
def forward(self, x):
x1 = self.linear_1(x)
x2 = self.linear_2(x1)
r1 = F.relu(x2)
return r1
if __name__ == "__main__":
module = ModuleOP()
# 开启数据dump。
debugger.start(model=module)
x = torch.randn(10, 8)
out = module(x)
loss = out.sum()
loss.backward()
# 关闭数据dump。
debugger.stop() 此处PrecisionDebugger通过传入config.json文件解析做初始化,然后使用debugger.start()和debugger.stop()控制采集数据的启停位置。
配置文件说明
以下是一个常用的采集统计量模式的config.json配置文件示例。该采集模式较为轻量级,一般采集数据量在几MB到几十MB,推荐在大多数场景下使用该配置。
{
"task": "statistics",
"dump_path": "/home/ma-user/msprobe_base_L1",
"rank": [],
"step": [],
"level": "L1",
"seed": 1234,
"is_deterministic": false,
"statistics": {
"scope": [],
"list": [],
"data_mode": ["all"],
"summary_mode": "statistics"
}
} 此外,mprobe还支持tensor模式的数据dump,这种模式数据量较大,一般在单卡小规模网络场景使用,数据量大小在GB级别。根据task参数取值的不同,也可以配置不同场景参数,配置方式介绍请参见配置文件说明。
训练场景注意事项
大多数训练场景(如huggingface transformers )一般是包含多个step及epoch的多轮迭代。需要注意如下内容:
- debugger.start()和debugger.stop()需要添加在训练的内层迭代逻辑中。
- 工具通过感知优化器的迭代次数进行step的计数。在某些场景下,根据优化器的step更新逻辑可能不一定准确(例如开启梯度累计时模型前向计算多次才进行反向计算)。这种情况推荐使用debugger.step()进行step计数。该函数需要配合debugger.start()和debugger.stop()函数使用,尽量添加在反向计算代码(如loss.backward)之后,否则可能会导致反向数据丢失。伪代码添加逻辑如下:
step = -1 for epoch in range(epochs_trained, num_train_epochs): # epoch循环epoch_iterator在该层初始化。 for step, inputs in enumerate(epoch_iterator): PrecisionDebugger.start() # step 内的训练核心代码 PrecisionDebugger.stop() PrecisionDebugger.step()
数据采集的添加位置
下文针对几种常见训练框架,说明数据采集的添加位置。
| 训练框架 | 修改位置 |
|---|---|
| 昇腾云(ModelLink) | 修改training.py中的train()函数。 |
| transformers | 修改Trainer._inner_training_loop()函数。 |
| megatron-LM | 修改training.py中的train()函数。 |
| MindSpeed-LLM | 修改training.py中的train()函数。 |
| mmpretrain | 修改EpochBasedTrainLoop.run_epoch()函数。 |
- 昇腾云(ModelLink):昇腾云发布的适配ModelLink的版本。具体信息,请参见主流开源大模型基于Lite Server适配ModelLink PyTorch NPU训练指导。
修改/home/ma-user/AscendSpeed/ModelLink/modellink/training/training.py脚本中的train()函数。
图1 ModelLink示例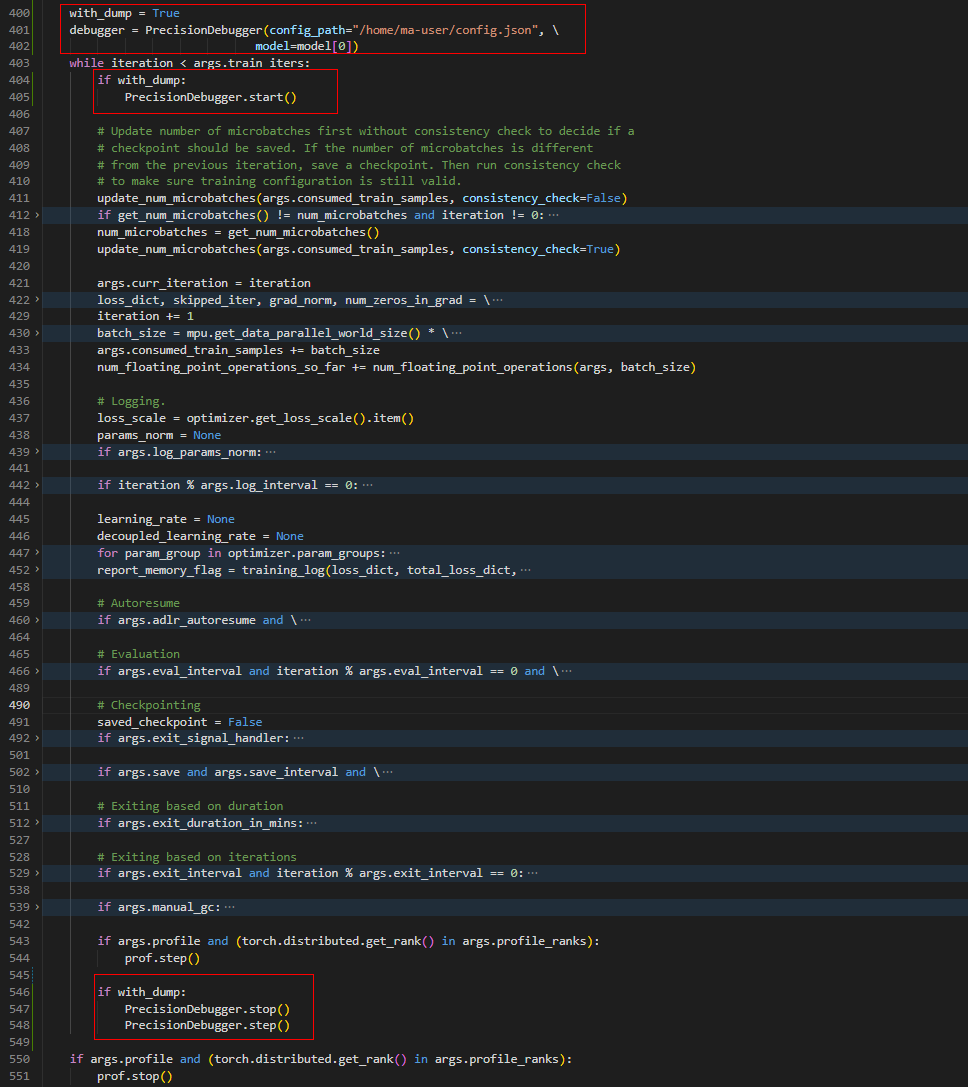
- transformers:修改src/transformers/trainer.py脚本中的Trainer._inner_training_loop()函数。 图2 transformers示例
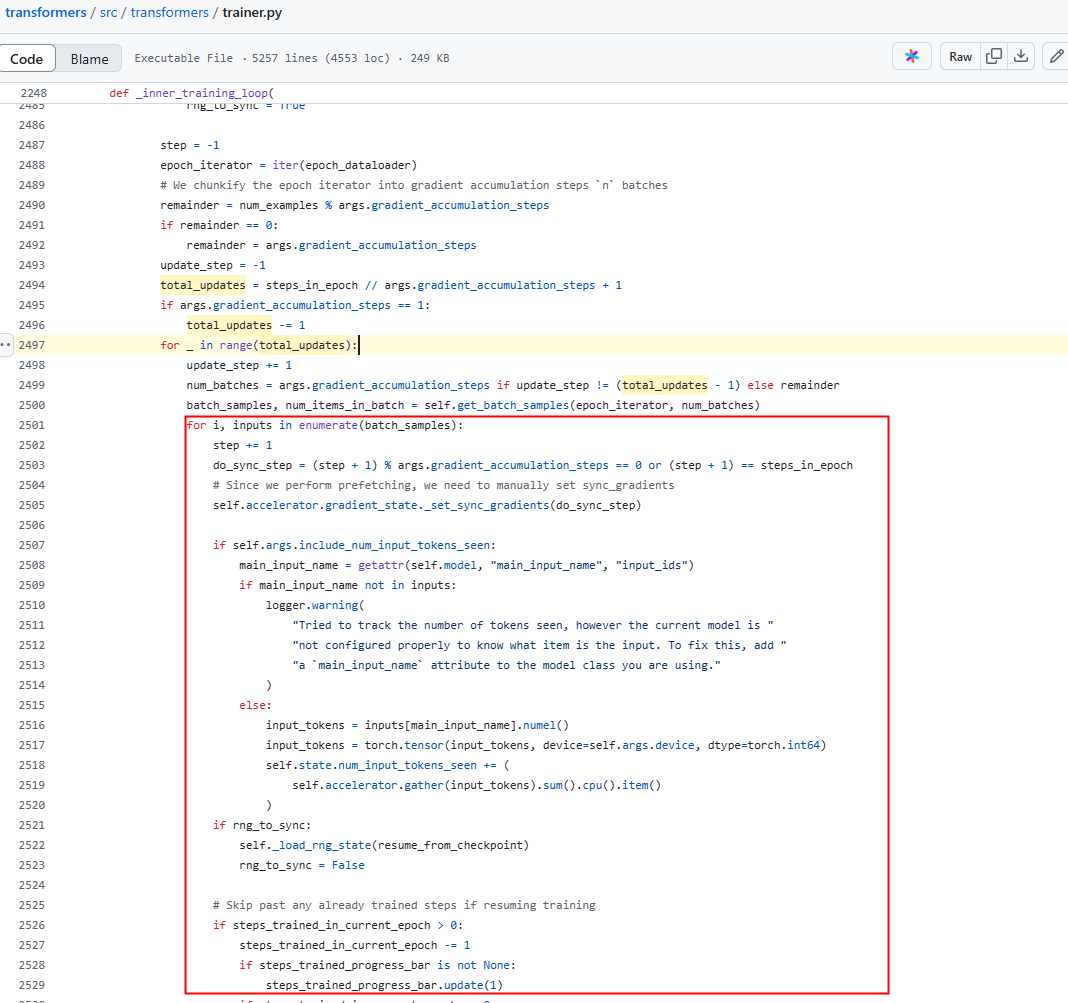
- megatron-LM:修改megatron/training/training.py脚本中的train()函数。 图3 megatron-LM示例
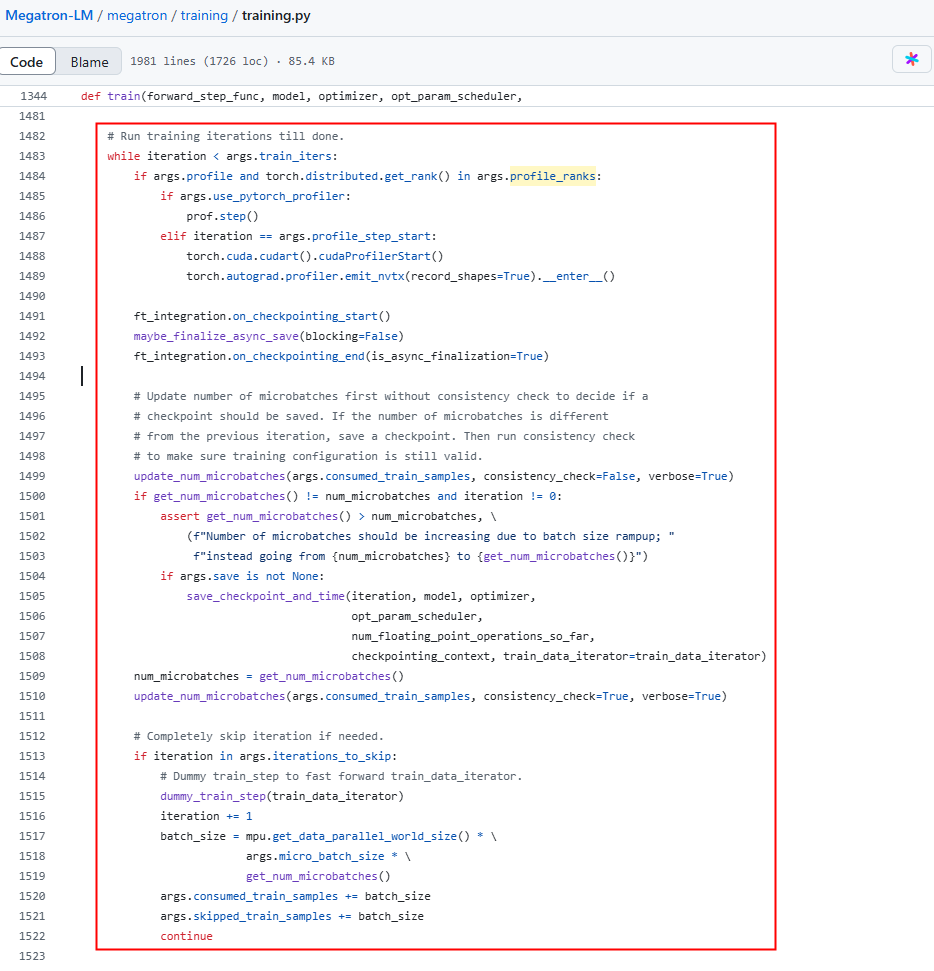
- MindSpeed-LLM:修改mindspeed_llm/training/training.py脚本中的train()函数。 图4 MindSpeed-LLM示例
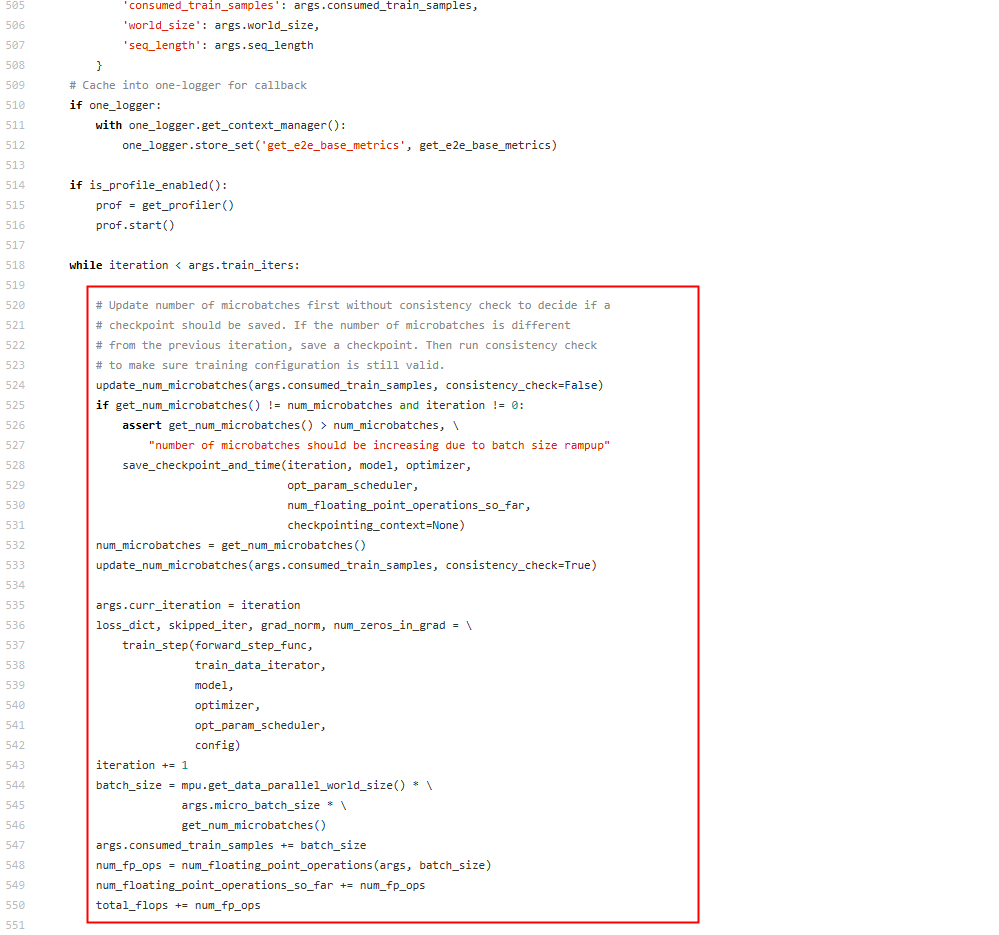
- mmpretrain:修改mmengine/runner/loops.py脚本中的EpochBasedTrainLoop.run_epoch()函数。 图5 mmpretrain示例

在线推理场景示例
from transformers import BertLMHeadModel, BertTokenizer
from msprobe.pytorch import PrecisionDebugger
# 加载预训练模型和tokenizer。
tokenizer = BertTokenizer.from_pretrained('/xxx/bert-tiny-chinese/')
model = BertLMHeadModel.from_pretrained('/xxx/bert-tiny-chinese/')
# 初始化PrecisionDebugger。
debugger = PrecisionDebugger(config_path="./config.json", \
dump_path="/home/ma-user/task_greedy_search_generate_token_0_Level1", \
model=model
)
# 定义要生成的文本的起始输入。
prompt = "The quick brown fox"
# 编码输入文本。
input_ids = tokenizer.encode(prompt, return_tensors="pt")
# 生成新的文本。
output_ids = model.generate(
input_ids,
max_length=30, # 生成的最大长度。
do_sample=True, # 使用采样策略生成。
top_k=50, # 采样时考虑概率最高的50个Token。
top_p=0.95, # 采样时考虑概率累计达到0.95的Token。
num_beams=1, # 使用贪婪搜索,而不是束搜索。
early_stopping=True # 当生成的文本达到最大长度时停止。
)
# 解码生成的文本。
generated_texts = [tokenizer.decode(output_id, skip_special_tokens=True) for output_id in output_ids]
# 打印生成的文本。
for text in generated_texts:
print(text) 注意事项:
- 推理模式:model.generate()方法在不同参数配置下会有不同的推理模式,支持的一些推理模式如下,详情请参见HuggingFace文档。
- 贪心解码(greedy decoding):num_beams=1且do_sample=False
- 对比搜索(contrastive search):penalty_alpha>0且top_k>1
- 多项式采样(multinomial sampling):num_beams=1且do_sample=True
- 束搜索(beam-search decoding):num_beams>1且do_sample=False
- 束搜索采样(beam-search multinomial sampling):num_beams>1且do_sample=True
- 多样性束搜索(diverse beam-search decoding):num_beams>1且num_beam_groups>1
- 约束搜索(constrained beam-search decoding):constraints!=None或force_words_ids!=None
- 辅助解码(assisted decoding):assistant_model或prompt_lookup_num_tokens被传递给.generate()
- 数据采集位置:以当前配置(num_beams=1且do_sample=False)为例,推理过程采用贪心解码方式。一般单条请求推理过程涉及多个Token输出, debugger启停入口如果设置在model.generate前后,会对整个推理过程的所有Token进行dump。在实际应用中,如果需要采集特定Token的数据,可以将推理过程的多个Token输出理解为训练过程的多个step。
修改源码脚本以采集特定Token数据
下文以当前配置方式下(num_beams=1且do_sample=False)第一个Token为例,说明msprobe采集统计量信息的修改方式。修改transformers/src/transformers/generation/utils.py源码脚本中的GenerationMixin._sample函数:
# utils.py GenerationMixin._sample()
from msprobe.pytorch import PrecisionDebugger
while self._has_unfinished_sequences(this_peer_finished, synced_gpus, device=input_ids.device):
PrecisionDebugger.start()
# 当前Token计算logits及更新迭代。
PrecisionDebugger.stop()
PrecisionDebugger.step() 其中config.json的文件配置示例如下:
{
"task": "statistics",
"dump_path": "/xxx/msprobe_base_L1",
"rank": [],
"step": [0],
"level": "L1",
"seed": 1234,
"is_deterministic": false,
"statistics": {
"scope": [],
"list": [],
"data_mode": ["all"],
"summary_mode": "statistics"
},
} 对于其他推理模式,可以按照以下步骤进行数据采集:
- 根据generation_mode参数分析走到了哪种decoding/sampling计算分支下。
- 追踪_has_unfinished_sequences函数的调用位置。
- 在Token的遍历迭代前后添加debugger.start()、debugger.stop()和debugger.step()配置进行数据的采集。
常见问题
- 使用dataloader后,raise异常:Exception("msprobe: exit after iteration {}". format(max(self.config.step)))。
- 添加msprobe工具后截取操作报错:IndexError: too many indices for tensor of dimension x或TypeError: len() of a 0-d tensor。
此错误通常是由于msprobe工具在处理张量时超出维度限制。解决方法如下:
- 注释工具文件:在mstt/debug/accuracy_tools/msprobe/pytorch/hook_module/support_wrap_ops.yaml文件中,注释掉Tensor:<span></span> 下的 - __getitem__ 工具,以跳过采集该API。
- 根据报错堆栈信息注释:如果需要采集关键位置的API,可以根据报错堆栈信息注释引发错误的类型检查。
- 使用msprobe工具数据采集功能后,模型出现报错:activation_func must be F.gelu或ValueError(Only support fusion of gelu and swiglu)。
此问题常见于Megatron/MindSpeed/ModelLink等加速库或模型仓中,原因是msprobe工具本身会封装torch的API(API类型和地址会发生改变),而部分API在工具使能前类型和地址就已确定,导致工具无法对这类API再进行封装。加速库中会对某些API进行类型检查,即会把工具无法封装的原始的API和工具封装之后的API进行判断,所以会报错。
规避方式有以下三种:- 将PrecisionDebugger的实例化放在文件的开始位置(导包后),确保所有API都被封装。
- 编辑配置文件mstt/debug/accuracy_tools/msprobe/pytorch/hook_module/support_wrap_ops.yaml,注释-gelu或-silu操作,工具会跳过采集该API。
- 根据报错堆栈信息注释引发报错的类型检查。




