Qwen-VL基于DevServer适配Pytorch NPU的推理指导(6.3.906)
Qwen-VL是规模视觉语言模型,可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。具有强大的性能、多语言对话、多图交错对话、支持中文开放域定位、细粒度识别和理解等特点。
本文档主要介绍如何利用训练框架PyTorch_npu + 华为自研Ascend Snt9B硬件,完成Qwen-VL推理。
资源规格要求
推荐使用“西南-贵阳一”Region上的DevServer资源和Ascend Snt9B。
|
名称 |
版本 |
|---|---|
|
PyTorch |
pytorch_2.1.0 |
|
驱动 |
23.0.5 |
获取镜像
|
分类 |
名称 |
获取路径 |
|---|---|---|
|
基础镜像 |
西南-贵阳一:swr.cn-southwest-2.myhuaweicloud.com/atelier/pytorch_2_1_ascend:pytorch_2.1.0-cann_8.0.rc2-py_3.9-hce_2.0.2312-aarch64-snt9b-20240528150158-b521cc0 |
从SWR拉取。 |
约束限制
- 推理需要单机单卡。
- 确保容器可以访问公网。
Step1 检查环境
- 请参考DevServer资源开通,购买DevServer资源,并确保机器已开通,密码已获取,能通过SSH登录,不同机器之间网络互通。

购买DevServer资源时如果无可选资源规格,需要联系华为云技术支持申请开通。
当容器需要提供服务给多个用户,或者多个用户共享使用该容器时,应限制容器访问Openstack的管理地址(169.254.169.254),以防止容器获取宿主机的元数据。具体操作请参见禁止容器获取宿主机元数据。
- SSH登录机器后,检查NPU卡状态。运行如下命令,返回NPU设备信息。
npu-smi info # 在每个实例节点上运行此命令可以看到NPU卡状态 npu-smi info -l | grep Total # 在每个实例节点上运行此命令可以看到总卡数
如出现错误,可能是机器上的NPU设备没有正常安装,或者NPU镜像被其他容器挂载。请先正常安装固件和驱动,或释放被挂载的NPU。
- 检查是否安装docker。
docker -v #检查docker是否安装
如尚未安装,运行以下命令安装docker。
yum install -y docker-engine.aarch64 docker-engine-selinux.noarch docker-runc.aarch64
- 配置IP转发,用于容器内的网络访问。执行以下命令查看net.ipv4.ip_forward配置项的值,如果为1,可跳过此步骤。
sysctl -p | grep net.ipv4.ip_forward
如果net.ipv4.ip_forward配置项的值不为1,执行以下命令配置IP转发。sed -i 's/net\.ipv4\.ip_forward=0/net\.ipv4\.ip_forward=1/g' /etc/sysctl.conf sysctl -p | grep net.ipv4.ip_forward
Step2 启动镜像
- 获取基础镜像。建议使用官方提供的镜像。镜像地址{image_url}参见获取镜像。
docker pull {image_url} - 启动容器镜像。启动前请先按照参数说明修改${}中的参数。可以根据实际需要增加修改参数。推理默认使用单机单卡。
docker run -itd --net=host \ --device=/dev/davinci0 \ --device=/dev/davinci_manager \ --device=/dev/devmm_svm \ --device=/dev/hisi_hdc \ --shm-size=32g \ -v /usr/local/dcmi:/usr/local/dcmi \ -v /usr/local/Ascend/driver:/usr/local/Ascend/driver \ -v /var/log/npu/:/usr/slog \ -v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \ -v ${work_dir}:${container_work_dir} \ --name ${container_name} \ ${image_id} \ /bin/bash参数说明:
- device=/dev/davinci0:挂载NPU设备,示例中挂载了1张卡davinci0。
- ${work_dir}:${container_work_dir} 代表需要在容器中挂载宿主机的目录。宿主机和容器使用不同的文件系统,work_dir为宿主机中工作目录,目录下存放着训练所需代码、数据等文件。container_dir为要挂载到的容器中的目录。为方便两个地址可以相同。
- shm-size:共享内存大小。
- ${container_name}:容器名称,进入容器时会用到,此处可以自己定义一个容器名称。
- ${image_id}:镜像ID,通过docker images查看刚拉取的镜像ID。
- 容器不能挂载到/home/ma-user目录,此目录为ma-user用户家目录。如果容器挂载到/home/ma-user下,拉起容器时会与基础镜像冲突,导致基础镜像不可用。
- driver及npu-smi需同时挂载至容器。
- 不要将多个容器绑到同一个NPU上,会导致后续的容器无法正常使用NPU功能。
- 进入容器。需要将${container_name}替换为实际的容器名称。启动容器默认使用ma-user用户,后续所有操作步骤都在ma-user用户下执行。
docker exec -it ${container_name} bash
Step3 准备推理环境
- 在容器工作目录下载Qwen-VL模型源码。
git clone https://github.com/QwenLM/Qwen-VL.git cd Qwen-VL && git checkout aa00ed04091eea5fcdd32985e7915f1c53e7d599
- 安装依赖。在模型源码包根目录下执行命令,安装模型需要的依赖。
#安装依赖包 pip install -r requirements.txt
- 下载权重。从HuggingFace下载Qwen-VL-Chat,或将您已下载的权重文件上传到容器工作目录${container_work_dir}中。
# 模型结构如下: Qwen-VL-Chat/ ├── config.json ├── configuration_qwen.py ├── generation_config.json ├── modeling_qwen.py ├── pytorch_model-00001-of-00010.bin ├── pytorch_model-00002-of-00010.bin ├── pytorch_model-00003-of-00010.bin ├── pytorch_model-00004-of-00010.bin ├── pytorch_model-00005-of-00010.bin ├── pytorch_model-00006-of-00010.bin ├── pytorch_model-00007-of-00010.bin ├── pytorch_model-00008-of-00010.bin ├── pytorch_model-00009-of-00010.bin ├── pytorch_model-00010-of-00010.bin ├── pytorch_model.bin.index.json ├── qwen_generation_utils.py ├── qwen.tiktoken ├── README.md ├── SimSun.ttf ├── tokenization_qwen.py ├── tokenizer_config.json └── visual.py
- 赋予容器访问权重文件的权限。上传代码和数据到宿主机时使用的是root用户,此处需要执行如下命令统一文件属主为ma-user用户。
#统一文件属主为ma-user用户 sudo chown -R ma-user:ma-group ${container_work_dir} # ${container_work_dir}:/home/ma-user/ws 容器内挂载的目录 #例如:sudo chown -R ma-user:ma-group /home/ma-user/ws - 修改Qwen-VL-Chat/modeling_qwen.py。
# 模型下载后,需修改Qwen-VL-Chat/modeling_qwen.py 36~37行,否则推理时会报cuda错误 sed -i "s/SUPPORT_FP16 =.*/SUPPORT_FP16 = SUPPORT_CUDA/g" modeling_qwen.py sed -i "s/SUPPORT_BF16 =.*/SUPPORT_BF16 = SUPPORT_CUDA/g" modeling_qwen.py
modeling_qwen.py修改前第36~37行样例如下。
SUPPORT_BF16 = SUPPORT_CUDA and torch.cuda.is_bf16_supported() SUPPORT_FP16 = SUPPORT_CUDA and torch.cuda.get_device_capability(0)[0] >= 7
modeling_qwen.py修改后第36~37行样例如下。
SUPPORT_BF16 = SUPPORT_CUDA SUPPORT_FP16 = SUPPORT_CUDA
Step4 开始推理
在容器工作目录下创建推理脚本文件infer.py,文件内容如下。
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
import os
os.environ['CURL_CA_BUNDLE'] = ''
import torch
import torch_npu
from torch_npu.contrib import transfer_to_npu
torch.manual_seed(1234)
# 模型权重路径按实际填写
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL-Chat", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat", device_map="cuda", trust_remote_code=True, bf16=True).eval()
# 第一轮对话
query = tokenizer.from_list_format([
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'}, # Either a local path or an url
{'text': '这是什么?'},
])
response, history = model.chat(tokenizer, query=query, history=None)
print(response)
# 图中是一名女子在沙滩上和狗玩耍,旁边是一只拉布拉多犬,它们处于沙滩上。
# 第二轮对话
response, history = model.chat(tokenizer, '框出图中击掌的位置', history=history)
print(response)
# <ref>击掌</ref><box>(536,509),(588,602)</box>
image = tokenizer.draw_bbox_on_latest_picture(response, history)
if image:
image.save('1.jpg')
else:
print("no box")
运行推理脚本。
python infer.py
推理结果如下所示。


Step5 调用API接口推理
进入源码根目录,安装依赖。
cd Qwen-VL pip install -r requirements_openai_api.txt
修改openai_api.py脚本,适配NPU。
# 在openai_api.py脚本的import torch下新增两行 import torch_npu from torch_npu.contrib import transfer_to_npu
启动API Server。执行命令前请先修改参数。
python openai_api.py -c ${model-path} --server-name=${server-name} --server-port=${server-port}
参数说明
- model-path: 模型权重路径,例:/home/ma-user/Qwen-VL-Chat
- server-name:进程监听IP或者域名
- server-port:进程监听端口,如果不配置该参数,启动端口默认是8000。
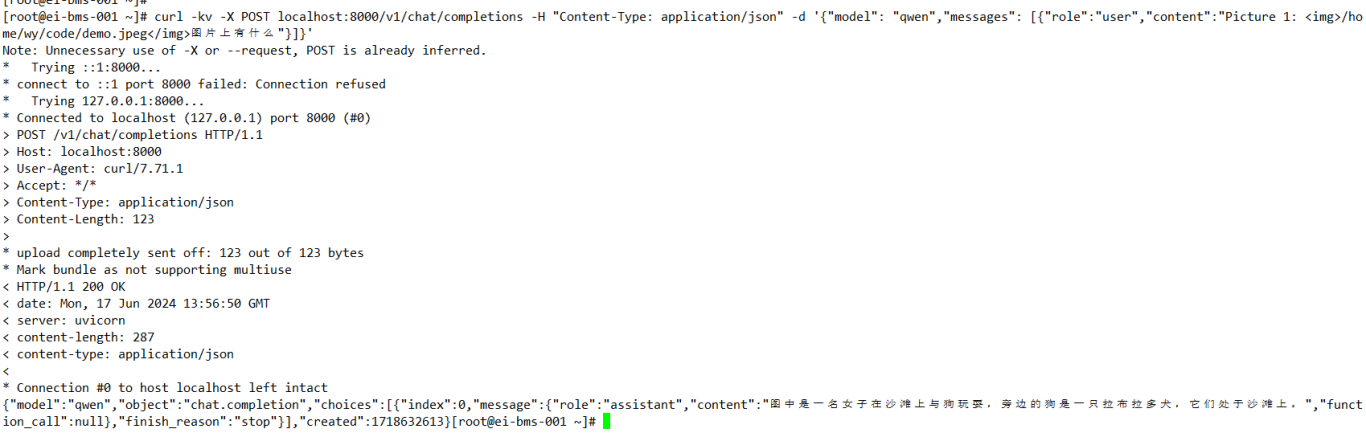
本地调用
本地调用命令如下。
# 调用地址以实际为准
curl -kv -X POST localhost:{server_port}/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "qwen","messages": [{"role":"user","content":"Picture id: <img>img_path/</img>\n{your prompt}"}]}'
参数说明:
- {server_port}:启动服务端时配置的监听端口
- content:对于带图像输入的内容可表示为 Picture id: <img>img_path</img>\n{your prompt},其中id表示对话中的第几张图片。"img_path"可以是本地的图片或网络地址。如果是本地图片,容器需要有权限读取图片。网络图片服务端会自动下载。
messages的样例如下:
# body参考
# 图片存放本地示例
{
"messages": [
{
"role": "user",
"content": "Picture 1: <img>/tmp/upload/demo.jpg</img>图片上有什么"
}
],
"model": "qwen"
}
远程调用
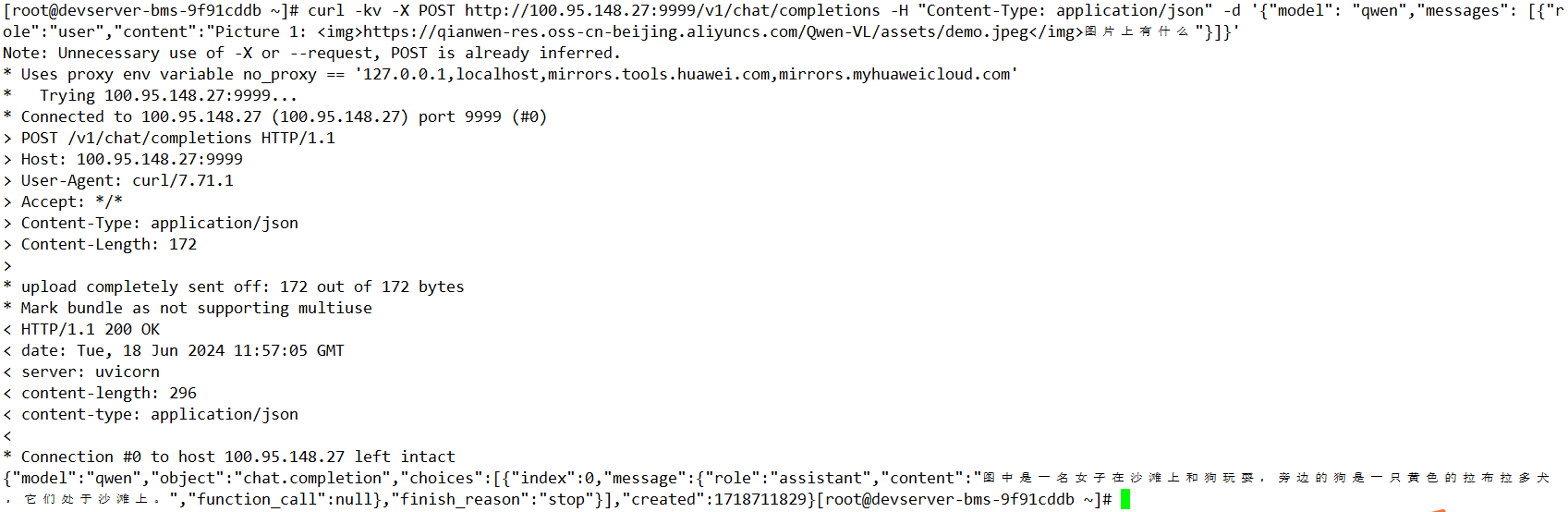
远程调用命令如下:
# endpoint以实际为准,图片为远程网络上的url
curl -kv -X POST http://{server_name}:{server_port}/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "qwen","messages": [{"role":"user","content":"Picture 1: <img>https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg</img>图片上有什么"}]}'
参数说明
- {server_name}:配置为服务端启动时监听的IP地址或者域名。
- {server_port}:配置为服务端启动时监听的端口。