

使用行列分流实现OLAP的复杂查询
操作场景
OLTP类业务一般包含读和写的请求,写请求统一由主节点处理,读请求由只读节点或主节点处理。OLAP类业务一般仅包含读请求,读请求统一由HTAP节点处理。
如果您的业务中既包含OLTP类业务又包含OLAP类业务,为了实现业务的最大性能,您可以基于列存索引特性,通过数据库代理地址实现OLAP查询引流到HTAP节点、OLTP查询引流到只读节点。
- 只读节点:该类型的只读节点基于行存储处理读请求。行存节点在处理OLTP读请求时具有更高的性能。
- HTAP节点:该类型的只读节点基于列存储处理读请求。HTAP在处理OLAP读请求(如复杂的SQL和分析型SQL)时,具有远超只读节点的性能。
行列分流介绍
行列分流支持自动分流和手动分流两种方式。
| 行列分流方式 | 描述 | 约束与限制 |
|---|---|---|
| 自动分流 | 自动分流功能开启后,数据库代理基于业务流入的SQL语句的实际执行代价来实现自动分流,从而实现SQL查询的最大性能。 自动分流判断标准:
|
|
| 手动分流 | 如果使用行存和列存自动分流没有达到预期效果,您可以使用HINT语法强制执行行存或列存执行计划。 | - |
使用须知
不支持数据库名称为中文的库同步,目标库、任务名不支持中文,且目标库最少三个字符。
前提条件
- TaurusDB实例需要按照如下表格进行参数设置。
表2 参数说明 参数名称
参数值
修改方式
说明
binlog_expire_logs_seconds
86400
Binlog的保留时间建议大于1天:60(秒)*60(分钟)*24(小时)=86400,防止由于binlog时间设置过短,导致增量复制失败。
rds_global_sql_log_bin
ON
TaurusDB内核版本大于或等于2.0.45.230900时,使用该参数。
内核版本的查询方法请参见如何查看云数据库 TaurusDB实例的版本号。
- TaurusDB实例已创建数据库和表。
操作步骤
步骤1:购买HTAP标准版实例
- 登录TaurusDB管理控制台。
- 单击管理控制台左上角的
 ,选择区域。
,选择区域。 - 在“实例管理”页面的实例列表中,选择目标实例,单击实例名称,进入实例概览页面。
- 在左侧导航栏选择“HTAP实时分析”,单击“创建HTAP实例”,进入创建HTAP实例页面。
- 配置HTAP标准版实例参数。
- 基础配置 图1 基础配置

表3 基础配置 参数
参数说明
计费模式
支持“按需计费”及“包年/包月”。
- 资源选配 图2 资源选配

表4 资源选配参数说明 参数
说明
实例系列
标准版:基于开源StarRocks进行深度二次开发的版本。
HTAP实例类型
支持单机和集群。
- 单机:只有一个FE节点与一个BE节点。单机版仅适用于功能体验和测试,不承诺SLA。
- 集群:最少三个FE节点和BE节点,最多10个FE节点和BE节点。
存储类型
支持极速型SSD和超高IO。
- 极速型SSD:极速型SSD云盘,结合25GE网络和RDMA技术,为您提供单盘最大吞吐量达1000 MB/s,并具有亚毫秒级低时延性能。
- 超高IO:采用多磁盘条带化技术,将IO负载均衡到多块磁盘上以提升读写带宽,最大吞吐量为1.7GB/s。
可用区类型
目前支持单可用区类型。
可用区
选择目标可用区。
时区
由于世界各国家与地区经度不同,地方时也有所不同,因此会划分为不同的时区。时区可在创建实例时选择,后期不可修改。
内网安全组
默认为TaurusDB内网安全组,建议与TaurusDB保持一致。
- 实例选配 图3 实例选配

表5 实例选配参数说明 参数
说明
性能规格
支持通用增强型。
BE节点规格
选择BE节点规格。
BE节点是标准版HTAP的后端节点,主要负责数据存储和SQL计算等工作。
BE节点存储
设置BE节点能够使用的存储空间。默认存储空间为50GB,最大可扩容至32000GB。
BE节点数量
- 单机版实例只有1个BE节点。
- 集群版实例可设置3~10个BE节点,单次最多可批量申请10个节点。
FE节点规格
选择FE节点规格。
FE节点是标准版HTAP的前端节点,主要负责管理元数据、管理客户端连接、进行查询规划、查询调度等工作。
FE节点存储
设置FE节点能够使用的存储空间。默认存储空间为50GB,最大可扩容至1000GB。
FE节点数量
- 单机版实例只有1个FE节点。
- 集群版实例可设置3~10个FE节点,单次最多可批量申请10个节点。
- 实例配置 图4 实例配置

表6 实例配置参数说明 参数
说明
实例名称
实例名称长度最小为4个字符,最大为64个字符,必须以字母开头,区分大小写,可以包含字母、数字、中划线、下划线或中文,不能包含其他特殊字符。
管理员密码
所设置的密码长度为8~32个字符,至少包含大写字母、小写字母、数字、特殊字符三种字符的组合,其中允许输入~!@#%^*-_=+?,()&$|.特殊字符。请您输入高强度密码并定期修改,以提高安全性,防止出现密码被暴力破解等安全风险。
如果后续计划使用行列自动分流功能,则在HTAP实例上创建的账户名和密码必须与连接数据库代理时使用的账户名和密码一致,否则无法通过数据库代理将请求分流至HTAP实例。
确认密码
必须和管理员密码相同。
- 购买时长与数量 图5 购买时长与数量

表7 购买时长与数量参数说明 参数
说明
购买时长(包年/包月)
选择所需的时长,系统会自动计算对应的配置费用,时间越长,折扣越大。
自动续费(包年/包月)
- 默认不勾选,不进行自动续费。
- 勾选后实例自动续费,自动续费周期与原订单周期一致。
购买数量
当前仅支持购买1个实例,不支持批量购买。
- 基础配置
- 参数配置完成后,单击右下角“立即创建”。
- 确认信息无误后,单击“提交”。
- 进行订单确认。
- 如果需要重新修改实例信息,单击“上一步”。
- 如果订单确认无误,单击“去支付”,在订单页面完成支付即可。
- 实例创建成功后,用户可在“HTAP实时分析”页面对其进行查看和管理。
步骤2:将TaurusDB数据同步至HTAP标准版实例
- 在“实例管理”页面的实例列表中,选择目标TaurusDB实例,单击实例名称,进入实例概览页面。
- 在左侧导航栏选择“HTAP实时分析”。
- 单击目标HTAP实例名称,进入实例的“基本信息”页面。
- 在左侧导航栏选择“数据同步”,单击“创建数据同步”。
- 在创建数据同步页面,进行参数设置。 图6 创建数据同步

表8 创建数据同步参数 参数
说明
从只读节点同步数据
是否从目标只读节点进行全量数据同步。全量同步过程中需保证只读节点可用,否则全量同步失败后需重新开始同步。
- 是:会从目标只读节点进行全量数据同步,以避免全量同步阶段对主节点产生查询压力。如果仅有一个只读节点,默认选择该节点为目标节点。
- 否:不进行同步。
实例级同步
同步一个或多个数据库。
- 是:一个数据同步任务可以同步多个库或者全部库。
- 否:一个数据同步任务仅仅只同步一个数据库。
库同步范围
仅在“实例级同步”选择“是”时显示。
- 所有库:默认同步所有数据库,不需要指定任何数据库名。
- 部分库:需要指定2个及以上的数据库名。
同步参数配置
根据业务需求修改,其他情况保持默认即可。
同步任务名
同步任务名在3到128个字符之间,由字母、数字、下划线组成,不能包含其他特殊字符。
目标库
目标库在3到128个字符之间,由字母、数字、下划线组成,不能包含其他特殊字符。
当“库同步范围”选择“所有库”时,“目标库”选项不展示。
开启行列自动分流时,源库名称和目标库名称需保持一致。
库同步设置
单击下拉列表选择需要进行数据同步的目标库,可根据实际需求修改HTAP节点的数据库参数。当“库同步范围”选项选择“所有库”时,下拉列表将隐藏。
同步范围
根据实际情况选择同步范围,支持对所有表或部分表进行同步。
在实例级同步时选择部分表进行同步,需要自行输入同步表的范围,可以使用表名通配符简化操作。
表名支持通配符
只有在“实例级同步”选择“是”,同步范围选择“部分表”时显示,库名/表名支持通配符。
实例级同步场景可以选择黑白名单中表名是否支持通配符,通配符只支持“*”和“?”字符。
“*”通配符表示匹配零个或多个任意字符,“?”通配符表示匹配一个任意字符。
同步范围 : 白名单
当同步范围选择部分表时,需要设置黑白名单的同步范围。
- 白名单和黑名单设置可根据实际需要选择其一进行设置,无法同时配置。如配置白名单,则只同步白名单中选择的表。如配置黑名单,则不同步黑名单中选择的表。
- 需要同步的表,需要包含主键或非空unique key,否则无法同步到HTAP节点。
- 后台数据合并任务及查询过程中可能额外使用磁盘空间,建议保留50%的空闲磁盘空间供系统额外使用。
- 在设置表黑白名单时可以在搜索框中一次性输入多张表,表之间可以通过逗号(“,”)、空格(“ ”)、换行(“\n”)分隔。在多表输入之后,单击
 ,与库中表相匹配的表会被默认勾选,出现在已选表中。
,与库中表相匹配的表会被默认勾选,出现在已选表中。
表同步设置
开启或关闭表同步设置。
- 开启:左侧选择已经同步的表进行相应的列操作,支持order by,key columns,distributed by,partition by,data_model,buckets,replication_num,enable_persistent_index,如果同时设置多个操作,操作之间通过分号连接。
详细的语法可以参考表9。
- 关闭:不需要进行“表同步设置”。
注意:默认情况下,表从TP同步到AP时,使用TP表的主键作为主键,排序键,并且使用主键做Hash分桶,不同步分区。
如果默认设置不满足AP业务的性能要求时,可以参考HTAP标准版性能调优进行调优,调整AP中表的排序键,分桶键,分区等。对具体表的调整可以通过表同步设置来进行配置。
表9 操作语法 操作类型
具体语法
order by
order by(column1, column2)或者order by column1,column2
key columns
key columns(column1, column2)或者key columns column1,column2
distributed by
distributed by (column1, column2) buckets 3
说明:buckets可选,如果不设置采用默认值。
partition by
分为表达式分区,List分区等。详见表同步设置支持的分区语法介绍。
data_model
用于指定表类型,取值范围可以是主键表(primary key),明细表(duplicate key)或者更新表(unique key)。
具体语法如下:
data_model=primary key或者data_model=duplicate key或者data_model=unique key
replication_num
replication_num=3
说明:取值不能超过BE节点数,否则会校验失败。
enable_persistent_index
表示是否持久化索引,具体语法如下:
enable_persistent_index=true或者enable_persistent_index=false
组合场景
data_model=duplicate key;key columns column1, column2;
- 配置完成后,单击“创建同步任务”。
- 操作成功后,单击“返回同步列表”,返回数据同步页面。会生成一条待同步的数据同步任务。此时该任务的状态为“同步阶段:等待同步”。 图7 查看任务状态

- 如需启动此任务,需单击操作列“同步”。
当HTAP实例的状态显示为“同步阶段:增量同步中”,表示该实例数据同步状态完成。

- 在全量同步过程中,若部分表同步异常,实例会产生告警,同时跳过异常表,继续同步后续的表,同步完成后进入增量同步状态。可在增量同步阶段修复异常表。
- 同步任务启动后先进行全量同步,全量同步时会通过FLUSH TABLES WITH READ LOCK进行锁表,为减少对业务的影响,请确保在业务低峰期进行。
- 业务测试时,若想暂停数据同步可以通过暂停按钮暂停任务,但暂停的时间不能超过源TaurusDB主实例的Binlog保留时长。若超过,则同步任务不能继续同步,只能删除重建。生产环境禁止暂停同步任务,防止导致OLTP和OLAP数据不一致。
步骤3:开启行列分流功能
行列分流支持自动分流和手动分流两种方式。
方式一:自动分流
- 在HTAP实例列表页面,单击目标实例的名称,进入实例的“基本信息”页面。
- 在左侧导航栏中,单击“数据库代理”,进入数据库代理页面。 图8 数据库代理页面

- 单击“新增代理”。
- 在“新增数据库代理服务”弹框中,设置相关参数。
表10 参数说明 参数名称
说明
代理实例名称
代理实例名称长度最小为4个字符,最大为64个字符且不超过64个字节(一个中文字符占用3个字节),必须以字母或中文开头,区分大小写,可以包含字母、数字、中划线、下划线或中文,不能包含其他特殊字符。
代理模式
仅支持读写模式。
读写模式:所有写请求只发往主节点,所有读请求按照读权重配比分发到已选节点。主节点的读权重值默认为100。
一致性级别
仅支持最终一致性。
最终一致性:如果需要减轻主节点压力,让尽量多的读请求路由到只读节点,您可以选择最终一致性。对数据的读取仅保证最终的结果是一致的,不保证能立即读取更新后的数据。对主节点的压力最小,性能最好。只读模式由于无法进行写操作,仅支持最终一致性。
路由模式
仅支持权重负载,根据您设置的读权重比例分发读请求。
代理实例规格
根据实际需要选择代理实例规格。
- 鲲鹏通用计算增强型:2 vCPUs | 4 GB、4 vCPUs | 8GB、8 vCPUs | 16 GB
- 通用增强型:2 vCPUs | 4 GB、4 vCPUs | 8 GB、8 vCPUs | 16 GB
子网
开通读写分离时支持指定子网。
- 如需开通开启读写分离指定子网的权限,请提交工单。
- 如果TaurusDB实例所在子网为扩展网段,则不支持跨子网开启读写分离,需要与TaurusDB实例在同一子网。
代理实例节点数量
默认为2个节点。最小支持2个节点,最大支持16个节点。
推荐代理实例节点数量 =(主节点CPU核数+所有只读节点CPU核数总和)/(4*代理实例CPU核数),计算结果向上取整。
新节点自动加入
开启新节点自动加入开关后,新增的只读节点会自动添加到该数据库代理实例中。
新节点权重
当路由模式为权重负载时,需要设置新节点的读权重。节点的读权重默认为100,读权重越高,处理的读请求越多。
行存/列存自动引流
打开列存/行存自动引流功能后,您需要设置SQL语句的执行代价阈值,数据库代理将此阈值作为判断依据。
若业务侧请求的SQL语句的预估执行代价大于该阈值,则将该请求引流至列存节点(HTAP节点)执行;若小于或等于该阈值,则将该请求引流至行存节点(只读节点)执行。
代理模式为读写模式、一致性级别为最终一致性、路由模式为权重负载且子网与TaurusDB实例一致时,才允许设置行存/列存自动引流。
选择数据库节点
选择主节点和需要参与处理请求的只读节点和HTAP节点。
至少需要选择一个只读节点和一个HTAP节点。
示例:
已选择1个主节点、1个只读节点、2个HTAP实例,读权重配置为100、100、100、300。
开启行存/列存自动引流后,写请求将引流至主节点,当请求SQL语句的预估执行代价小于或等于阈值(假设当前阈值为50000)时,读请求将按照1:1的比例引流到主节点和只读节点,即主节点和只读节点分别处理50%的读请求;当请求SQL语句的预估执行代价大于阈值(假设当前阈值为50000)时,将按照1:3的比例分别引流到两个HTAP节点,即两个HTAP实例分别处理25%和75%的读请求。
- 单击“确定”。
- 设置自动引流阈值。
开启了列存/行存自动引流功能后,您需要设置SQL语句的实际执行代价阈值。阈值配置完成后,数据库代理将此阈值作为判断依据。若业务侧请求的SQL语句的预估执行代价大于该阈值,则将该请求引流至列存节点(HTAP)执行;若小于或等于该阈值,则将该请求引流至行存节点(只读节点)执行。
当前SQL语句的实际执行代价阈值由下表中的参数决定,您可以在数据库代理的参数修改页面,根据自身业务情况修改参数的值,从而调整自动分流效果。
表11 参数说明 参数名称
描述
looseImciApThreshold
分发至列存节点的SQL语句的执行代价阈值,默认为50000。
说明:开启列存/行存自动引流功能后,如果SQL语句的执行代价大于阈值,则路由至HTAP节点。
您可以通过直连主节点执行如下命令,精确查询上一条SQL语句的执行代价,从而判断如何调整上表中的参数值。
explain format=json SQL命令
示例:
explain format=json select sbtest1.*,sbtest2.* from sbtest1 inner join sbtest2 where sbtest1.id < 100 and sbtest2.k > 11;
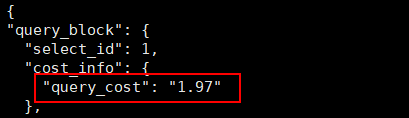
从以上查询结果可以看出,该SELECT语句的执行代价为1.97。
此时若要实现将该SQL查询分流至列存节点的列存计划执行,则需要将“looseImciApThreshold”参数的值设置为“1”。
方式二:手动分流
如果使用行存和列存自动分流没有达到预期效果,您可以使用HINT语法强制执行行存或列存执行计划。
- HINT语法仅对指定的SQL语句生效,对其它连接或同一个连接下的其它SQL语句没有影响
- 如果在5.7.7版本之前的MySQL客户端执行HINT语法,则在连接数据库引擎时需要添加--comments选项。您可以使用mysql --version命令来查看MySQL客户端版本。
- 使用数据库代理进行行存和列存自动分流时,还可以通过HINT语法使得数据库代理将SQL语句强制分发至列存节点执行,而不受“looseImciApThreshold”的影响。
具体方式为:在SQL关键字前添加/* FORCE_IMCI_NODES */。
例如:
/*FORCE_IMCI_NODES*/ SELECT COUNT(*) FROM t1;
- 使用数据库代理进行行存和列存自动分流时,还可以通过HINT语法使得数据库代理将SQL语句强制分发至行存节点执行,而不受“looseImciApThreshold”的影响。
具体方式为:在SQL关键字前添加/*FORCE_SLAVE*/或/*FORCE_MASTER*/。
示例:
发往只读行存节点:
/*FORCE_SLAVE*/ SELECT COUNT(*) FROM t1;
发往主节点:
/*FORCE_MASTER*/ SELECT COUNT(*) FROM t1;




