

更新时间:2024-10-16 GMT+08:00
压缩盘古大模型
N2基础功能模型、N4基础功能模型、经有监督微调训练以及RLHF训练后的N2、N4模型可以通过模型压缩技术在保持相同QPS目标的情况下,降低推理时的显存占用。
采用INT8的压缩方式,INT8量化可以显著减小模型的存储大小与降低功耗,并提高计算速度。
模型经过量化压缩后,不支持评估操作,但可以进行部署操作。
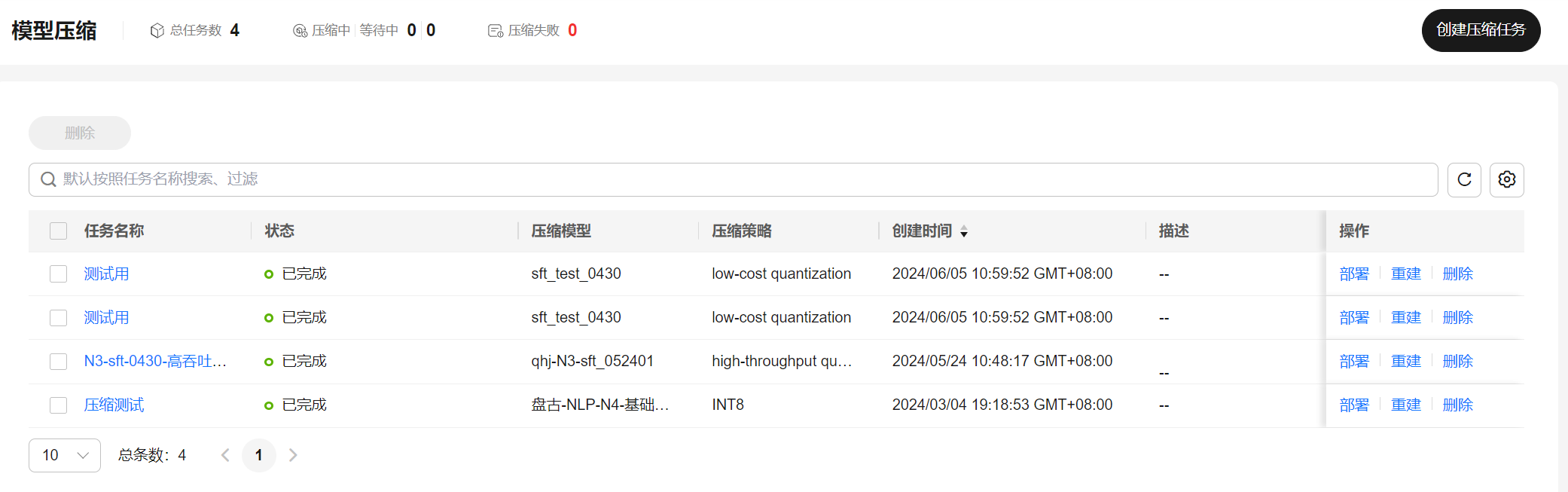
创建模型压缩任务
- 登录盘古大模型套件平台。
- 在左侧导航栏中选择“模型开发 > 模型压缩”。
- 单击界面右上角“创建压缩任务”,进入创建压缩任务页面。
图1 模型压缩
- 选择需要进行压缩的模型执行模型压缩,压缩策略为“INT8”。当压缩模型为N2基础功能模型,或是经有监督微调训练和RLHF训练后的N2模型,支持选择“低消耗模式”,减少推理资源的消耗。
图2 创建压缩任务
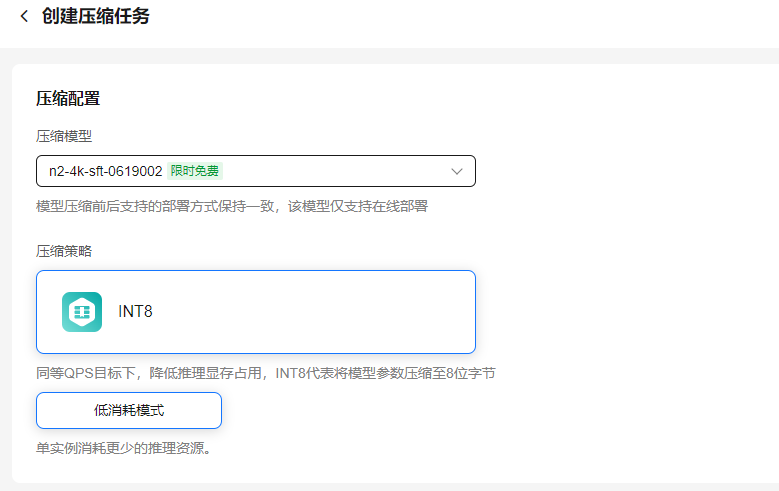
- 输入任务名称和描述,单击“立即创建”,即可下发压缩模型任务。模型压缩任务完成后,可以使用压缩后的模型进行部署操作。





