

查看评估任务详情
查看评估任务详情
- 登录盘古大模型套件平台。
- 在左侧导航栏中选择“模型开发 > 模型评估”。
- 单击任务名称查看模型评估任务详情。包含基本信息、评估详情、评估报告、评估日志以及数据配置。
图1 任务详情界面
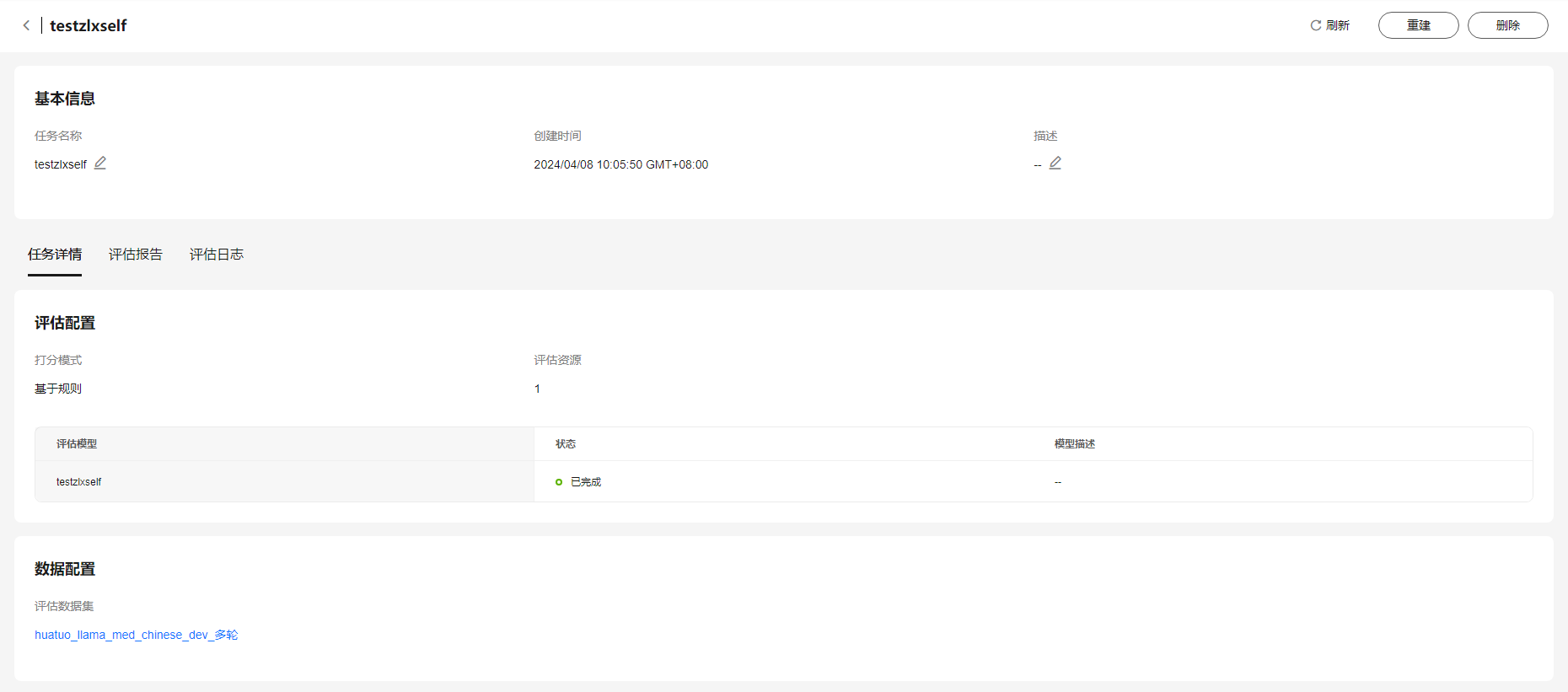
- 任务详情:
任务详情中包含打分模式、评估资源、评估模型、任务状态以及模型描述。
图2 任务详情
- 评估报告:
任务状态为“已完成”时,查看评估报告。评估报告中包含困惑度、评估概览以及模型结果分析。
- 困惑度:分数越低,评估结果越好。
- 评估概览:查看此次评估任务的各个规则指标评分情况。
- 模型结果分析:查看各个模型此次评估任务的基于各个指标的评分情况,以及具体到某条数据的打分情况。
图3 评估报告页面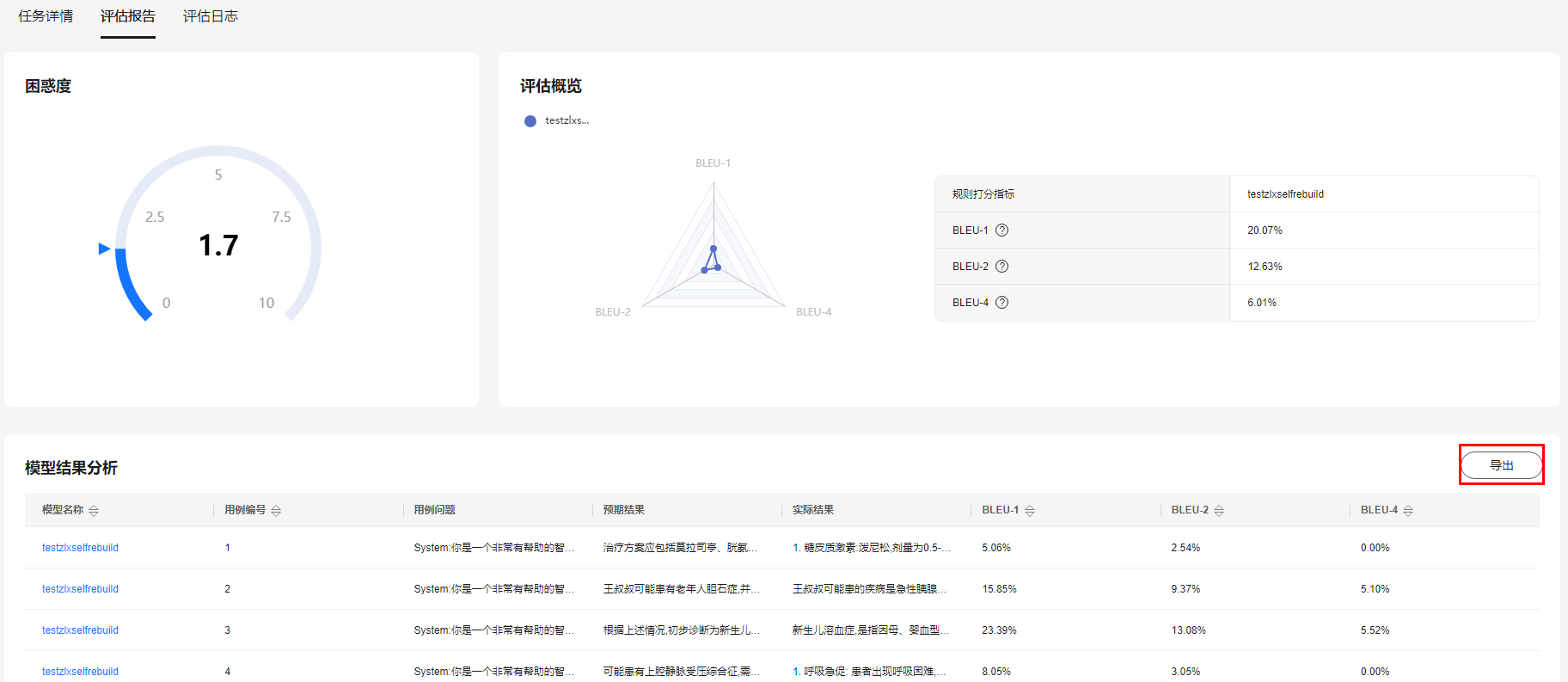
- 评估日志:
平台支持查看本次模型评估任务的详细日志。选择评估的模型后,可以查看其从创建开始到任务结束的日志内容,支持下载并保存到本地(log格式)。可通过日志查看报错,调整任务配置重新发起。
图4 评估日志页面
- 任务详情:
评估指标说明
模型训练完成后,可以通过一系列的评估方法来衡量模型的性能。当前支持基于规则打分,即基于相似度/准确率进行打分,对比模型预测结果与标注数据的差异,从而计算模型指标。支持的模型指标请参见下表。
表1 规则打分指标
|
指标名称 |
说明 |
|---|---|
|
BLEU-1 |
模型生成句子与实际句子在单字层面的匹配度,数值越高,表明模型性能越好。 |
|
BLEU-2 |
模型生成句子与实际句子在中词组层面的匹配度,数值越高,表明模型性能越好。 |
|
BLEU-4 |
模型生成结果和实际句子的加权平均精确率,数值越高,表明模型性能越好。 |
|
困惑度 |
用来衡量大语言模型预测一个语言样本的能力,数值越低,准确率也就越高,表明模型性能越好。 |
- 指标适用的任务场景
任务答案是相对比较确定的,例如固定答案的问答任务、NL2SQL、NL2JSON、文本分类等。
- 指标不适用的任务场景
文案创作、聊天等符合要求即可的场景,该类场景的创作型更强,不存在唯一答案。
- 指标与模型能力的关系
BLEU指标用于评估模型生成句子(candidate)与实际句子(reference)差异的指标。取值范围在0.0到1.0之间,值越高说明模型生成和实际答案匹配度越高。
可以作为模型能力的参考指标,当两个模型进行比较时,BLEU指标越大的模型效果一般更好。但是模型的能力还是需要通过人工评测来评判,BLEU指标只能作为参考。
- 指标的缺陷
BLEU指标只考虑n-gram词的重叠度,不考虑句子的结构和语义。
模型优化建议
如何基于指标的分值对训练任务进行调整:一般横向比较两个模型时,可以参考该指标。然而,指标没有一个明确的阈值来指示何时模型效果差。因此,单靠该指标无法直接决定任务的调整策略。
如果指标低是由于提示词(prompt)设置不合理,可以通过在模型训练阶段扩大训练集和验证集来优化模型,从而改善评估结果。另外,还可以将评估数据集设计得更接近训练集的数据,以提升评估结果的准确性。





