

创建自监督微调训练任务
创建自监督微调训练任务
- 登录盘古大模型套件平台。
- 在左侧导航栏中选择“模型开发 > 模型训练”,单击界面右上角“创建训练任务”。
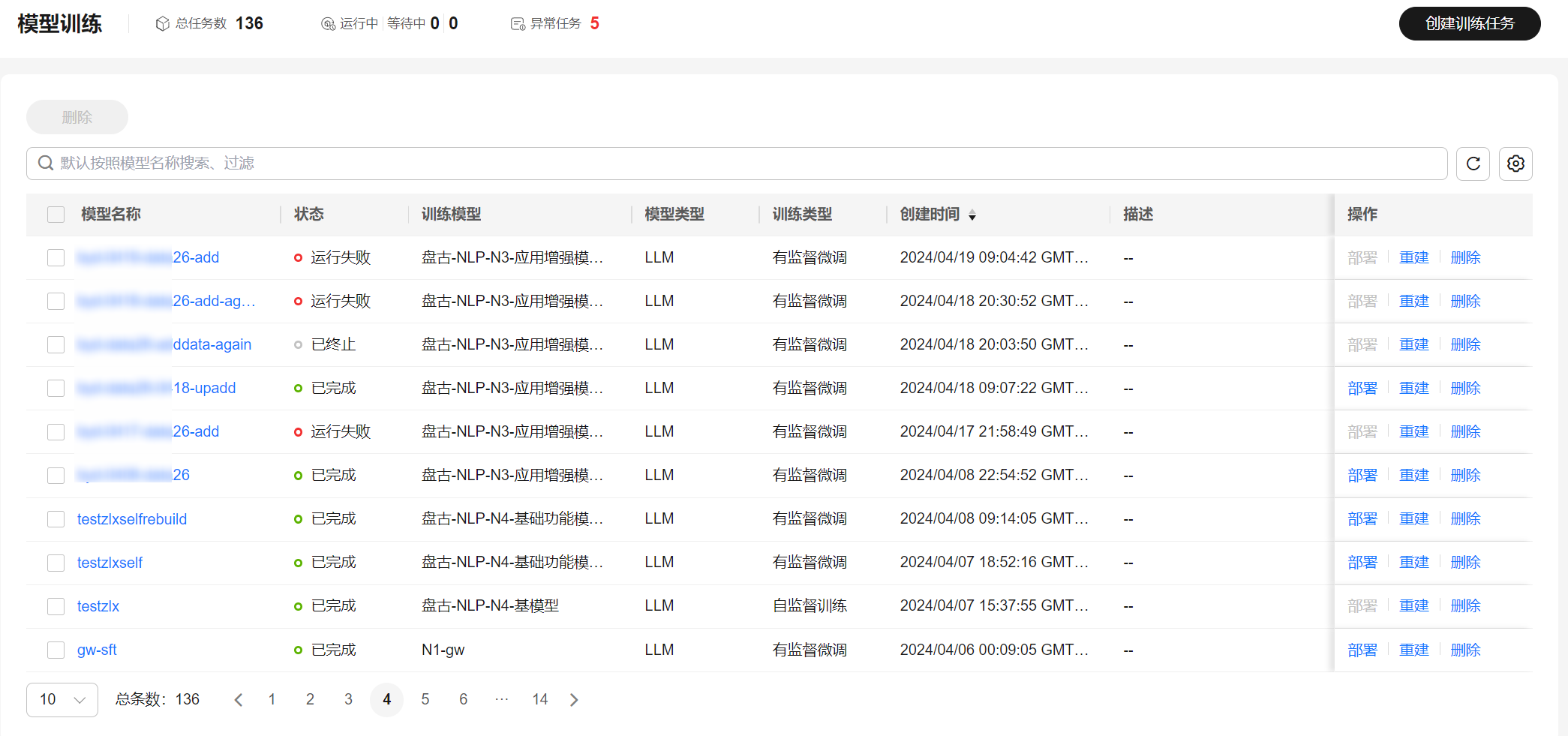
图1 模型训练列表
- 在训练配置中,设置模型类型、训练类型、训练模型、训练参数和checkpoints等参数。
其中,训练配置选择LLM(大语言模型),训练类型选择自监督训练,根据所选模型配置训练参数。
表1 自监督训练参数说明 参数名称
说明
模型类型
选择“LLM”。
训练类型
选择“自监督训练”。
训练模型
选择训练所需要的模型,模型详细介绍请参见选择模型与训练方法。
训练参数
指定用于训练模型的超参数。
训练参数说明和调参策略请参见自监督微调训练参数说明。
checkpoints
模型训练任务过程中,checkpoints用于保存模型权重和状态的机制,以便故障场景及用户主动终止训练任务后,能够基于中间checkpoints继续训练。
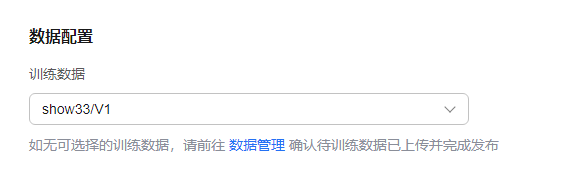
- 在数据配置中,选择训练模型所需的数据集。
图2 数据配置
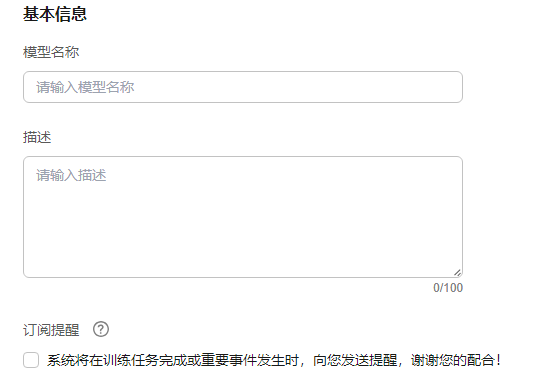
- 完成训练任务基本信息。设置模型的名称、描述以及订阅提醒。
- 单击“立即创建”,创建自监督训练任务。
自监督微调训练参数说明
不同模型训练参数默认值存在一定差异,请以前端页面展示的默认值为准。
|
训练参数 |
默认值 |
范围 |
说明 |
|---|---|---|---|
|
数据批量大小 |
8 |
>=1 |
数据集进行分批读取训练,设定每个批次数据的大小。 一般来说,批大小越大,训练速度越快,但会占用更多的内存资源,且可能导致收敛困难或过拟合。批大小越小,训练速度越慢,但会减少内存消耗,且可能提高泛化能力。因此,批大小需要根据数据集的规模和特点,以及模型的复杂度和性能进行调整。同时,批大小还与学习率相关。学习率是指每次更新参数时,沿着梯度方向移动的步长。一般来说,批大小和学习率成正比。如果批大小增大,学习率也相应增大;如果批大小减小,那么学习率也应减小。 |
|
训练轮数 |
1 |
1~50 |
完成全部训练数据集训练的次数。 |
|
学习率 |
0.0001 |
0~1 |
学习率用于控制每个训练步数(step)参数更新的幅度。需要选择一个合适的学习,因为学习率过大会导致模型难以收敛,学习率过小会导致收敛速度过慢。 |
|
模型保存步数 |
500 |
10的倍数 |
每训练一定数量的步骤(或批次)后,模型的状态就会被保存下来。 可以通过token_num = step * batch_size * sequence公式进行预估。其中:
数据量以token为单位。 |
|
优化器 |
adamw |
adamw |
优化器参数指的是用于更新模型权重的优化算法的相关参数,可以选择adamw。
|
|
学习率衰减比率 |
0.00001 |
0~1 |
学习率衰减后,最小不会低于的学习率,计算公式为:学习率*学习率衰减比率。 |
|
热身比例 |
0.1 |
0~1 |
热身阶段占整体训练的比例。 模型刚开始训练时,如果选择一个较大的学习率,可能导致模型训练不稳定。选择使用warmup热身的方式,可以使开始训练的热身阶段内学习率较小,模型可以慢慢趋于稳定,待模型相对稳定后再逐渐提升至预设的最大学习率进行训练。使用热身可以使得模型收敛速度更快,效果更佳。 |

当前盘古-NLP-N4-基模型支持自监督训练。
|
训练参数 |
推荐值 |
|---|---|
|
数据批量大小 |
4 |
|
训练轮数 |
1 |
|
学习率 |
0.00001 |
|
模型保存步数 |
5000 |
|
优化器 |
adamw |
|
学习率衰减比率 |
0.01 |
|
热身比例 |
0.1 |





