

ALTER TABLE PARTITION
功能描述
本章节介绍修改表分区的语法功能,包括增删分区、切割分区、合成分区、从普通表数据迁移到分区表,以及修改分区属性等。
逻辑上的一张表根据某种方案分成几张物理块进行存储,这张逻辑上的表称之为分区表,物理块称之为分区。分区表是一张逻辑表,不存储数据,数据实际是存储在分区上的。
常见的分区策略都是按照某一列或者某几列定义一些数据分布范围,然后每个分区承载一个范围的数据,这些列称之为分区键。
目前DWS行存表、列存表支持的分区类型包括范围分区和列表分区。
- 范围分区(Range Partitioning)
根据表的一列或者多列,将要插入表的记录分为若干个范围,这些范围在不同的分区里没有重叠。为每个范围创建一个分区,用来存储相应的数据。
- 核心特征:数据按连续区间分布,常用于有序且按范围检索的场景。
- 适用场景:分区键具有线性增长或连续区间特征,数据查询常围绕 “某一范围” 展开,且新数据会自然落入新的区间。例如按时间范围进行分区的订单数据,按数值范围分区的用户等级数据等。
- 范围分区策略是指记录插入分区的方式,根据分区键值将记录映射到已创建的某个分区上,如果可以映射到已创建的某一分区上,则把记录插入到对应的分区上,否则给出报错和提示信息,这是最常用的分区策略。目前范围分区仅支持范围分区策略。
- 列表分区(List Partitioning)
根据表的一列,将要插入表的记录通过每一个分区中出现的键值划分到对应的分区中,这些键值在不同的分区里没有重叠。为每组键值创建一个分区,用来存储相应的数据。列表分区仅8.1.3及以上集群版本支持。
- 核心特征:数据按离散的枚举值划分,常用于固定分类或高频过滤的维度。
- 适用场景:分区键值是固定且离散的类别,数据查询常围绕 “某一类别” 展开,键值不会无规律新增。例如按省份分区的用户信息表,每个省份对应一个分区。
- 列表分区策略是根据分区键值将记录映射到已创建的某个分区上,如果可以映射到已创建的某一分区上,则把记录插入到对应的分区上,否则给出报错和提示信息。
注意事项
- 添加分区的名称不能与该分区表已有分区的名称相同。
- 对于范围分区表,要添加的分区的边界值要和分区表的分区键的类型一致,且要大于分区表的最后一个分区的上边界。
- 对于列表分区表,如果已经定义DEFAULT分区,则不能添加新分区。
- 若文档中未特殊注明,则表明范围分区表和列存分区的语法使用相同。
- 如果目标分区表中已有分区数达到了最大值(32767),则不能继续添加分区。
- 当分区表只有一个分区时,不能删除该分区。
- 删除分区(DROP PARTITION)时会连同分区内数据一起删除。
- 选择分区使用PARTITION FOR(),括号里指定值个数应该与定义分区时使用的列个数相同,并且一一对应。
- Value分区表不支持相应的Alter Partition操作。
- OBS冷热表对于move,exchange,merge,split操作,不支持指定分区表的表空间为OBS表空间;执行ALTER语法时,需保持分区数据冷热属性不变(即冷分区操作后为冷分区,热分区操作后为热分区),不支持将冷分区数据切至本地表空间;对于冷分区仅支持默认表空间;merge操作不支持将冷分区与热分区进行合并,exchange操作不支持冷分区交换。

- 避免在业务高峰期执行ALTER TABLE/ALTER TABLE PARTITION(增删改查、DROP PARTITION)、TRUNCATE操作,避免有长SQL阻塞ALTER、TRUNCATE操作或SQL业务被ALTER、TRUNCATE阻塞。
- 更多开发设计规范参见总体开发设计规范。
语法格式
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} action [, ... ]; |
其中action统指如下分区维护子语法。当存在多个分区维护子句时,保证了分区的连续性,无论这些子句的排序如何,DWS总会先执行DROP PARTITION再执行ADD PARTITION操作,最后顺序执行其它分区维护操作。
- MODIFY PARTITION子语法:设置分区索引是否可用
- REBUILD PARTITION子语法:重建分区索引
- EXCHANGE PARTITION(交换分区)子语法:把普通表的数据迁移到指定的分区
- ROW MOVEMENT子语法:设置分区表的行迁移开关
- MERGE PARTITIONS子语法:把多个分区合并成一个分区
- SPLIT PARTITION子语法:把一个分区切割成多个分区
- 增加分区ADD PARTITION子语法:为指定的分区表添加一个或多个分区
- 删除分区DROP PARTITION子语法:删除分区表中的指定分区或多个分区
- TRUNCATE PARTITION子语法:清理表分区的数据
ALTER TABLE PARTITION主句参数说明
| 参数 | 描述 | 取值范围 |
|---|---|---|
| table_name | 需要修改的分区表的名称。 | 已存在的分区表名。 |
| action [, ... ] | action统指分区维护子语法。当存在多个分区维护子句时,保证了分区的连续性,无论这些子句的排序如何,DWS总会先执行DROP PARTITION再执行ADD PARTITION操作,最后顺序执行其它分区维护操作。 | 参见以下各个子语法使用。 |
| partition_name | 需要修改的分区名。 | 已存在的分区名。 |
| partition_value | 分区键值。 通过PARTITION FOR ( partition_value [, ...] )子句指定的这一组值,可以唯一确定一个分区。 | 需要进行重命名分区的分区键的取值范围。 |
MODIFY PARTITION子语法:设置分区索引是否可用
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} MODIFY PARTITION partition_name { UNUSABLE LOCAL INDEXES | REBUILD UNUSABLE LOCAL INDEXES } |
| 参数 | 描述 | 取值范围 |
|---|---|---|
| partition_name | 需要修改的分区名。 | 已存在的分区名。 |
| UNUSABLE LOCAL INDEXES | 设置该分区上的所有索引不可用。 | - |
| REBUILD UNUSABLE LOCAL INDEXES | 重建该分区上的所有索引。 | - |
REBUILD PARTITION子语法:重建分区索引
REBUILD PARTITION是DWS中用于重建分区表索引的操作,主要用于修复因异常操作(如分区数据大量变更、索引损坏等)导致的分区索引不可用状态,或优化分区索引性能。与重建整个表的索引相比,它仅针对指定分区操作,能显著减少资源消耗和执行时间。
典型使用场景:
- 分区索引失效后修复:当分区执行了大量DML操作(如批量删除、更新)或异常中断后,分区索引可能变为 UNUSABLE 状态,需重建恢复可用性。
- 性能优化:长期运行的分区表,索引可能产生碎片,重建可优化索引结构,提升查询效率。
- 分区数据迁移后:通过EXCHANGE PARTITION交换分区数据后,索引可能需要重建以保持一致性。
该语法仅8.3.0.100及以上集群版本支持。
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} REBUILD PARTITION partition_name [ WITHOUT UNUSABLE ] |
| 参数 | 描述 | 取值范围 |
|---|---|---|
| WITHOUT UNUSABLE | 重建该分区上的索引时,忽略UNUSABLE状态的索引。 | - |
EXCHANGE PARTITION(交换分区)子语法:把普通表的数据迁移到指定的分区
EXCHANGE PARTITION(交换分区,或称分区交换)是数据仓库中用于高效管理分区表的关键操作。其核心功能是将分区表中的一个分区与普通表进行元数据层交换,而非物理移动数据。这意味着数据块的所有权快速切换,避免大规模I/O操作,极大提升性能。
使用场景:
- 数据批量加载:将预处理好的数据先加载到临时表,再替换到目标分区,减少业务高峰期对生产表的写入压力。
- 历史数据归档:将不再频繁访问的分区交换到独立表中,便于迁移到低成本存储。
- 分区数据修复:将问题分区的数据交换到临时表进行修正,再重新交换回分区表,降低修复期间的锁竞争。
- 数据迁移:跨表或跨库迁移特定分区数据时,直接交换避免逐条插入。
语法格式:
1 2 3 4 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} EXCHANGE PARTITION { ( partition_name ) | FOR ( partition_value [, ...] ) } WITH TABLE {[ ONLY ] ordinary_table_name | ordinary_table_name * | ONLY ( ordinary_table_name )} [ { WITH | WITHOUT } VALIDATION ] [ VERBOSE ] |
| 参数 | 描述 | 取值范围 |
|---|---|---|
| partition_value | 分区键值。 通过PARTITION FOR ( partition_value [, ...] )子句指定的这一组值,可以唯一确定一个分区。 | 需要进行重命名分区的分区键的取值范围。 |
| ordinary_table_name | 进行迁移的普通表的名称。 | 已存在的普通表名。 |
| { WITH | WITHOUT } VALIDATION | 在进行数据迁移时,是否检查普通表中的数据满足指定分区的分区键范围。默认为WITH。 由于检查比较耗时,特别是当数据量很大的情况下更甚。所以在保证当前普通表中的数据满足分区的分区键范围时,可以加上WITHOUT来指明不进行检查。 |
|
| VERBOSE | 在VALIDATION是WITH状态时,如果检查出普通表有不满足要交换分区的分区键范围的数据,那么把这些数据插入到正确的分区,如果路由不到任何分区,再报错。 注意: 只有在VALIDATION是WITH状态时,才可以指定VERBOSE。 | - |
进行交换的普通表和分区表必须满足如下条件:
- 普通表和分区表的列数目相同,对应列的信息严格一致,包括:列名、列的数据类型、列约束、列的Collation信息、列的存储参数、列的压缩信息、已删除字段的数据类型等。
- 普通表和分区表的表压缩信息严格一致。
- 普通表和分区表的分布列信息严格一致。
- 普通表和分区表的索引个数相同,且对应索引的信息严格一致。
- 普通表和分区表的表约束个数相同,且对应表约束的信息严格一致。
- 普通表不可以是临时表和unlogged表。
- 普通表和分区表应该在同一个逻辑集群或节点组(NodeGroup)中,如果不在同一个逻辑集群或节点组,将会采用将数据插入对方表内方式来实现交换分区,这样交换分区的时间与表数据量有关,对于数据量非常大的表和分区表,交换分区将会非常耗时。
- 在线扩容重分布场景中,如果普通表和分区表正在重分布,交换分区语句有可能中断正在重分布的普通表或分区表(取决于交换分区和重分布语句是否产生锁冲突),通常重分布的普通表或分区表被中断后会重试2次,但同一个表交换分区执行过于频繁可能导致普通表或分区表多次重试重分布都失败。如果普通表重分布过程被交换分区操作打断,在重试重分布时,数据已经被替换为原分区表中的数据,会重新进行全量重分布。
- 如果行存分区表中最后一个有效字段后的其他字段全部被删除,在不考虑这些删除字段的情况下,分区表与普通表字段信息一致时,分区表和普通表可以进行交换。
- 列存普通表和列存分区表的表级参数colversion必须一致:禁止colversion2.0与colversion1.0执行交换分区操作。
完成交换后,普通表和分区表的数据被置换,同时普通表和分区表的表空间信息被置换。此时,普通表和分区表的统计信息变得不可靠,需要对普通表和分区表重新执行analyze。
ROW MOVEMENT子语法:设置分区表的行迁移开关
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} { ENABLE | DISABLE } ROW MOVEMENT |
| 参数 | 描述 | 取值范围 |
|---|---|---|
| ENABLE/DISABLE ROW MOVEMENT | 行迁移开关,当更新表中某行分区键值时,如果新值属于其他分区,则会根据开关给出报错信息或者将该行数据迁移到对应的分区。
默认为DISABLE,关闭。 注意: 开启ROW MOVEMENT则允许跨分区更新,但此时如果有SELECT FOR UPDATE查询该分区表并发执行,存在查询结果瞬时不一致的可能性,需要谨慎使用。 | 举例,某分区表的日期列(分区键),按季度进行分区,分为分区p_2023q1和p_2023q2,某一行的“2023-02-15”原属于第一季度的分区p_2023q1,当更新该值为“2023-05-15”后,对应的这行数据,会根据ROW MOVEMENT开关是否打开而决定是否行数据迁移:
详细示例参见示例:开启和关闭行迁移功能ROW MOVEMENT。 |
MERGE PARTITIONS子语法:把多个分区合并成一个分区
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} MERGE PARTITIONS { partition_name } [, ...] INTO PARTITION partition_name |
- INTO关键字前的分区称为源分区,INTO关键字后的分区称为目标分区。
- 源分区个数不能小于2个。
- 源分区名称不能重复。
- 源分区不能存在unusable的索引,否则执行会报错。
- 目标分区名只能跟最后一个源分区的名称相同,或者跟表的所有分区名都不相同。
- 目标分区的边界是所有源分区边界的并集。
- 对于范围分区表,所有的源分区必须是边界连续的分区。
- 对于列表分区,如果源分区中包含DEFAULT分区,那么目标分区的边界也是DEFAULT。
SPLIT PARTITION子语法:把一个分区切割成多个分区
范围分区的split_clause语法如下:
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} SPLIT PARTITION { partition_name | FOR ( partition_value [, ...] ) } { split_point_clause | no_split_point_clause } |
- 指定切割点split_point_clause的语法为:
1AT ( partition_value ) INTO ( PARTITION partition_name , PARTITION partition_name )

切割点的大小要位于正在被切割分区的分区键范围内,指定切割点的方式只能把一个分区切割成两个新分区。
- 不指定切割点no_split_point_clause的语法为。
1INTO { ( partition_less_than_item [, ...] ) | ( partition_start_end_item [, ...] ) }
- 不指定切割点的方式,partition_less_than_item指定的第一个新分区的分区键要大于正在被切割的分区的前一个分区(如果存在的话)的分区键,partition_less_than_item指定的最后一个分区的分区键要等于正在被切割分区的分区键大小。
- 不指定切割点的方式,partition_start_end_item指定的第一个新分区的起始点(如果存在的话)必须等于正在被切割的分区的前一个分区(如果存在的话)的分区键,partition_start_end_item指定的最后一个分区的终止点(如果存在的话)必须等于正在被切割分区的分区键。
- partition_less_than_item支持的分区键个数最多为4,而partition_start_end_item仅支持1个分区键,其支持的数据类型参见表2中的“PARTITION BY RANGE(partition_key)”参数。
- 在同一语句中partition_less_than_item和partition_start_end_item两者不可同时使用;不同split语句之间没有限制。
- 分区项partition_less_than_item的语法为:
1 2
PARTITION partition_name VALUES LESS THAN ( { partition_value | MAXVALUE } [, ...] )
- 分区项partition_start_end_item的语法为,其约束参见表2中的“partition_start_end_item”参数。
1 2 3 4 5 6
PARTITION partition_name { {START(partition_value) END (partition_value) EVERY (interval_value)} | {START(partition_value) END ({partition_value | MAXVALUE})} | {START(partition_value)} | {END({partition_value | MAXVALUE})} }
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} SPLIT PARTITION { partition_name | FOR ( partition_value [, ...] ) } { split_values_clause | split_no_values_clause } |
- 指定切割点的split_values_clause的语法为:
1VALUES ( { (partition_value) [, ...] | DEFAULT } ) INTO ( PARTITION partition_name , PARTITION partition_name )
- 如果源分区不是DEFAULT分区,那么切割点所指定的边界是源分区边界的一个非空真子集;如果源分区是DEFAULT分区,那么切割点所指定的边界不能和其它非DEFAULT分区的边界存在重叠。
- 切割点的指定的边界是INTO关键字后面的第一个分区的边界,源分区边界与切割点的指定的边界的差集是第二个分区的边界。
- 当源分区是DEFAULT分区时,第二个分区的边界还是DEFAULT。
- 不指定切割点的split_no_values_clause的语法为:
1INTO ( list_partition_item [, ....], PARTITION partition_name )
- 此处的list_partition_item和创建列表分区表的时候指定分区的语法一样,除了此处的分区定义中边界值不能为DEFAULT。
- 除了最后一个分区,其他分区需要显式定义边界,定义的边界不能是DEFAULT,并且必须是源分区边界的非空真子集。最后一个分区的边界是源分区边界与其它分区边界的差集,且最后一个分区的边界为空(即差集不能为空集)。
- 如果源分区是DEFAULT分区,则最后一个分区的边界为DEFAULT。
增加分区ADD PARTITION子语法:为指定的分区表添加一个或多个分区
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} ADD { partition_less_than_item... | partition_start_end_item } |
- 使用partition_less_than_item语法时,分区表必须是范围分区表,否则执行会报错。
- 此处partition_less_than_item和创建范围分区表的时候指定分区的语法一样。
- 当前分区表的最后一个分区的边界为MAXVALUE,不允许添加新的分区,否则执行会报错。
列表分区的add_clause语法如下:
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} ADD list_partition_item |
- 使用list_partition_item语法时,分区表必须是列表分区表,否则执行会报错。
- 此处的list_partition_item和创建列表分区表的时候指定分区的语法一样。
- 当前分区表存在DEFAULT分区时,不允许添加新的分区动作,否则执行会报错。
删除分区DROP PARTITION子语法:删除分区表中的指定分区或多个分区
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} DROP PARTITION { partition_name | FOR ( partition_value [, ...] ) } |
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} DROP PARTITION { partition_name [, ... ] } |
TRUNCATE PARTITION子语法:清理表分区的数据
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} TRUNCATE PARTITION { partition_name | FOR ( partition_value [, ...] ) }; |
- partition_value为分区键值。支持指定多个分区键值,多个分区键值以英文逗号分隔。
- 使用PARTITION FOR子句时,partition_value所在的整个分区会被清空。
修改表分区名称语法
1 2 | ALTER TABLE [ IF EXISTS ] { table_name [*] | ONLY table_name | ONLY ( table_name )} RENAME PARTITION { partition_name | FOR ( partition_value [, ...] ) } TO partition_new_name; |
| 参数 | 描述 | 取值范围 |
|---|---|---|
| partition_new_name | 分区的新名称。 | 字符串,需符合标识符命名规范。 |
示例:创建范围分区表customer_address
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | DROP TABLE IF EXISTS customer_address; CREATE TABLE customer_address ( ca_address_sk INTEGER NOT NULL , ca_address_id CHARACTER(16) NOT NULL , ca_street_number CHARACTER(10) , ca_street_name CHARACTER varying(60) , ca_street_type CHARACTER(15) , ca_suite_number CHARACTER(10) ) DISTRIBUTE BY HASH (ca_address_sk) PARTITION BY RANGE(ca_address_sk) ( PARTITION P1 VALUES LESS THAN(100), PARTITION P2 VALUES LESS THAN(200), PARTITION P3 VALUES LESS THAN(300) ); |
示例:创建list分区表
1 2 3 4 5 6 7 8 9 10 11 12 | DROP TABLE IF EXISTS data_list; CREATE TABLE data_list( id int, time int, salary decimal(12,2) )PARTITION BY LIST (time)( PARTITION P1 VALUES (202209), PARTITION P2 VALUES (202210,202208), PARTITION P3 VALUES (202211), PARTITION P4 VALUES (202212), PARTITION P5 VALUES (202301) ); |
示例:使用MODIFY PARTITION子句设置分区索引是否可用
给分区表customer_address创建LOCAL索引student_grade_index,并指定分区的索引名称。
1 2 3 4 5 6 | CREATE INDEX customer_address_index ON customer_address(ca_address_id) LOCAL ( PARTITION P1_index, PARTITION P2_index, PARTITION P3_index ); |
重建分区表customer_address中分区P1上的所有索引。
1 | ALTER TABLE customer_address MODIFY PARTITION P1 REBUILD UNUSABLE LOCAL INDEXES; |
设置分区表customer_address的分区P3上的所有索引不可用。
1 | ALTER TABLE customer_address MODIFY PARTITION P3 UNUSABLE LOCAL INDEXES; |
示例:使用REBUILD PARTITION子语法重建插入过数据的分区索引
- 创建分区表。
1 2 3 4 5 6 7 8 9 10 11
DROP TABLE IF EXISTS sales; CREATE TABLE sales ( id INT, sale_date DATE, amount DECIMAL(10,2) ) PARTITION BY RANGE (sale_date) ( PARTITION p202310 VALUES LESS THAN ('2023-11-01'), PARTITION p202311 VALUES LESS THAN ('2023-12-01') );
- 创建索引。
1CREATE INDEX idx_sale_date ON sales (sale_date) LOCAL;
- 插入10月、11月分区数据。
1 2 3 4 5 6 7
INSERT INTO sales PARTITION (p202310) VALUES (1, '2023-10-05', 100.50), (2, '2023-10-10', 200.75); INSERT INTO sales PARTITION (p202311) VALUES (3, '2023-11-15', 300.00);
- 重建特定分区p202310的索引。
1ALTER TABLE sales REBUILD PARTITION p202310 WITHOUT UNUSABLE;
示例:使用ADD PARTITION子句为指定的分区表添加一个或多个分区
为范围分区表customer_address增加分区。
1 | ALTER TABLE customer_address ADD PARTITION P5 VALUES LESS THAN (500); |
为范围分区表customer_address增加分区: [500, 600), [600, 700)。
1 | ALTER TABLE customer_address ADD PARTITION p6 START(500) END(700) EVERY(100); |
为范围分区表customer_address增加MAXVALUE分区p7。
1 | ALTER TABLE customer_address ADD PARTITION p7 END(MAXVALUE); |
为列表分区表增加分区P6。
1 | ALTER TABLE data_list ADD PARTITION P6 VALUES (202302,202303); |
示例:使用SPLIT PARTITION子句将一个分区切割成多个分区
将范围分区表customer_address的P7分区以800为分割点切分。
1 | ALTER TABLE customer_address SPLIT PARTITION P7 AT(800) INTO (PARTITION P6a,PARTITION P6b); |
将范围分区表customer_address中400所在的分区分割成多个分区。
1 | ALTER TABLE customer_address SPLIT PARTITION FOR(400) INTO(PARTITION p_part START(300) END(500) EVERY(100)); |
将列表分区表data_list的分区P2分割成p2a和p2b两个分区。
1 | ALTER TABLE data_list SPLIT PARTITION P2 VALUES(202210) INTO (PARTITION p2a,PARTITION p2b); |
示例:使用EXCHANGE PARTITION(交换分区)子句将普通表的数据迁移到指定分区
如下示例将演示一个普通表math_grade数据迁移到分区表student_grade中分区(math)的操作。
- 创建分区表student_grade。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
DROP TABLE IF EXISTS student_grade; CREATE TABLE student_grade ( stu_name char(5), stu_no integer, grade integer, subject varchar(30) ) PARTITION BY LIST(subject) ( PARTITION gym VALUES('gymnastics'), PARTITION phys VALUES('physics'), PARTITION history VALUES('history'), PARTITION math VALUES('math') );
- 插入数据到分区表student_grade中。
1 2 3 4 5 6 7
INSERT INTO student_grade VALUES ('Ann', 20220101, 75, 'gymnastics'), ('Jack', 20220103, 60, 'math'), ('Anna', 20220108, 56, 'history'), ('John', 20220107, 82, 'physics'), ('Molly', 20220104, 91, 'physics'), ('Sam', 20220105, 72, 'math');
- 查询分区表student_grade的math分区记录。
1SELECT * FROM student_grade PARTITION (math);
查询结果如下:

- 创建一个与分区表student_grade定义匹配的普通表math_grade。
1 2 3 4 5 6 7 8
DROP TABLE IF EXISTS math_grade; CREATE TABLE math_grade ( stu_name char(5), stu_no integer, grade integer, subject varchar(30) );
- 插入数据到表math_grade中。数据与分区表student_grade的math分区的分区规则一致。
1 2 3 4 5
INSERT INTO math_grade VALUES ('Ann', 20220101, 75, 'math'), ('Jack', 20220103, 60, 'math'), ('Anna', 20220108, 56, 'math'), ('John', 20220107, 82, 'math');
- 将普通表math_grade数据迁移到分区表student_grade的分区(math)。
1ALTER TABLE student_grade EXCHANGE PARTITION (math) WITH TABLE math_grade;
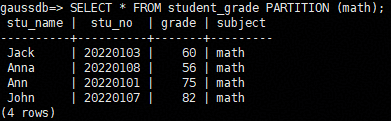
- 查询分区表student_grade,结果显示表math_grade中的数据已和分区表student_grade的分区math中的数据交换。
1SELECT * FROM student_grade PARTITION (math);
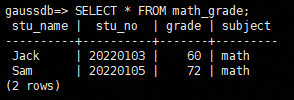
- 查询表math_grade,显示之前存储在分区表student_grade的分区math中的数据已交换到表math_grade中。
1SELECT * FROM math_grade;
示例:使用TRUNCATE PARTITION子语法清理表分区的数据
清空表customer_address分区p1:
1 | ALTER TABLE customer_address TRUNCATE PARTITION p1; |
示例:开启和关闭行迁移功能ROW MOVEMENT
在更新某行的分区键为新值且新值属于其他分区时,如果打开ROW MOVEMENT,则该行数据对应迁移到新的分区中。
频繁更新分区键时,ENABLE ROW MOVEMENT 可能导致额外I/O开销,需评估业务需求。
创建按日期范围分区的表,并启用行迁移。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | DROP TABLE IF EXISTS sale_data; CREATE TABLE sales_data ( sale_id INT, product_name VARCHAR(100), sale_date DATE, amount DECIMAL(10, 2) ) PARTITION BY RANGE (sale_date) ( PARTITION p_2023q1 VALUES LESS THAN ('2023-04-01'), PARTITION p_2023q2 VALUES LESS THAN ('2023-07-01'), PARTITION p_2023q3 VALUES LESS THAN ('2023-10-01'), PARTITION p_2023q4 VALUES LESS THAN ('2024-01-01') ) ENABLE ROW MOVEMENT; |
插入测试数据。
1 2 3 4 | INSERT INTO sales_data (sale_id, product_name, sale_date, amount) VALUES (1, 'Product A', '2023-02-15', 1000.00), -- 属于 p_2023q1 (2, 'Product B', '2023-05-20', 1500.00); -- 属于 p_2023q2 |
查询各分区数据分布。
1 | SELECT tableoid::regclass AS partition, * FROM sales_data ORDER BY sale_id; |

尝试更新分区键值(从 p_2023q1 移动到 p_2023q2)。
1 | UPDATE sales_data SET sale_date = '2023-05-01' WHERE sale_id = 1; |
再次查询各分区数据分布,确认行已移动。
1 | SELECT tableoid::regclass AS partition, * FROM sales_data ORDER BY sale_id; |

关闭行迁移功能。
1 | ALTER TABLE sales_data DISABLE ROW MOVEMENT; |
再次修改分区键(从 p_2023q2 移动回到 p_2023q2)。
1 | UPDATE sales_data SET sale_date = '2023-02-15' WHERE sale_id = 1; |
回显提示,行迁移关闭,不允许更新分区键。

示例:使用MERGE PARTITIONS子句把多个分区合并成一个分区
将范围分区表customer_address的P2,P3两个分区合并为一个分区。
1 2 | ALTER TABLE customer_address MODIFY PARTITION P3 REBUILD UNUSABLE LOCAL INDEXES; --上面的示例设置成P3索引不可用,先执行该语句重建索引再做MERGE,否则下行示例会报错 ALTER TABLE customer_address MERGE PARTITIONS P2, P3 INTO PARTITION P_M; |
示例:使用DROP PARTITION子句删除分区表中的指定分区
删除分区表customer_address的多个分区P6a,P6b。
1 | ALTER TABLE customer_address DROP PARTITION P6a, P6b; |




