

更新时间:2024-11-12 GMT+08:00
步骤6:数据开发处理
DataArts Studio数据开发模块可管理多种大数据服务,提供一站式的大数据开发环境、全托管的大数据调度能力,极大降低用户使用大数据的门槛,帮助您快速构建大数据处理中心。
使用DataArts Studio数据开发,用户可进行数据管理、数据集成、脚本开发、作业开发、版本管理、作业调度、运维监控等操作,轻松完成整个数据的处理分析流程。
在DataArts Studio数据开发模块中,您将完成以下步骤:
- 数据管理
- 脚本开发
- 作业开发
- 历史数据到源数据表,使用数据集成将历史数据从OBS导入到SDI贴源层的原始数据表。
- 历史数据清洗,使用数据开发的MRS Hive SQL脚本将源数据表清洗之后导入DWI层的标准出行数据表。
- 将基础数据插入维度表中。
- 将DWI层的标准出行数据导入DWR层的事实表中。
- 数据汇总,通过Hive SQL将出租车行程订单事实表中的数据进行汇总统计并写入汇总表。
- 运维调度
数据管理
数据管理功能可以协助用户快速建立数据模型,为后续的脚本和作业开发提供数据实体。主要包含建立数据连接、新建数据库、新建数据表等操作。
在本例中,相关数据管理操作已经在步骤2:数据准备中完成,本步骤可跳过。
脚本开发
- 在DataArts Studio控制台首页,选择对应工作空间的“数据开发”模块,进入数据开发页面。
- 在左侧导航栏中,单击“脚本开发”,再右键单击“脚本”选择,在弹出框中输入目录名称例如“transport”,然后单击“确定”。
- 在脚本目录树中,右键单击目录名称transport,选择菜单“新建Hive SQL脚本”。
- 在新建的HIVE_untitled脚本中,选择数据连接mrs_hive_link,选择数据库demo_dwr_db,然后输入脚本内容。 图1 编辑脚本

该脚本用于将付款方式、费率代码、供应商的基本信息写入到相应的维度表中。脚本内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
truncate table dim_payment_type; truncate table dim_rate_code; truncate table dim_vendor; INSERT INTO dim_payment_type VALUES ("1","Credit card"); INSERT INTO dim_payment_type VALUES ("2","Cash"); INSERT INTO dim_payment_type VALUES ("3","No charge"); INSERT INTO dim_payment_type VALUES ("4","Dispute"); INSERT INTO dim_payment_type VALUES ("5","Unknown"); INSERT INTO dim_payment_type VALUES ("6","Voided trip"); INSERT INTO dim_rate_code VALUES ("1","Standard rate"); INSERT INTO dim_rate_code VALUES ("2","JFK"); INSERT INTO dim_rate_code VALUES ("3","Newark"); INSERT INTO dim_rate_code VALUES ("4","Nassau or Westchester"); INSERT INTO dim_rate_code VALUES ("5","Negotiated fare"); INSERT INTO dim_rate_code VALUES ("6","Group ride"); INSERT INTO dim_vendor VALUES ("1","A Company"); INSERT INTO dim_vendor VALUES ("2","B Company");
- 单击“运行”按钮,测试脚本是否正确。 图2 运行脚本

- 测试通过后,单击“保存”按钮,在弹出框中输入脚本名称如:demo_taxi_dim_data,选择保存的脚本路径并单击“提交”按钮提交版本。 图3 保存脚本
 图4 提交脚本版本
图4 提交脚本版本
- 重复4~6的步骤,完成如下脚本的创建。
- 脚本名称:demo_etl_sdi_dwi,该脚本用于将SDI贴源层的原始数据写入到DWI层的标准出行数据表中。脚本内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49
INSERT INTO demo_dwi_db.dwi_taxi_trip_data SELECT `vendorid`, cast( regexp_replace( `tpep_pickup_datetime`, '(\\d{2})/(\\d{2})/(\\d{4}) (\\d{2}):(\\d{2}):(\\d{2}) (.*)', '$3-$1-$2 $4:$5:$6' ) as TIMESTAMP ), cast( regexp_replace( `tpep_dropoff_datetime`, '(\\d{2})/(\\d{2})/(\\d{4}) (\\d{2}):(\\d{2}):(\\d{2}) (.*)', '$3-$1-$2 $4:$5:$6' ) as TIMESTAMP ), `passenger_count`, `trip_distance`, `ratecodeid`, `store_fwd_flag`, `pulocationid`, `dolocationid`, `payment_type`, `fare_amount`, `extra`, `mta_tax`, `tip_amount`, `tolls_amount`, `improvement_surcharge`, `total_amount` FROM demo_sdi_db.sdi_taxi_trip_data WHERE trip_distance > 0 and total_amount > 0 and payment_type in (1, 2, 3, 4, 5, 6) and vendorid in (1, 2) and ratecodeid in (1, 2, 3, 4, 5, 6) and tpep_pickup_datetime < tpep_dropoff_datetime and tip_amount >= 0 and fare_amount >= 0 and extra >= 0 and mta_tax >= 0 and tolls_amount >= 0 and improvement_surcharge >= 0 and total_amount >= 0 and (fare_amount + extra + mta_tax + tip_amount + tolls_amount + improvement_surcharge) = total_amount;
- 脚本名称:demo_etl_dwi_dwr_fact,该脚本用于将DWI层的标准出行数据写入到DWR层的事实表中。脚本内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
INSERT INTO demo_dwr_db.fact_stroke_order SELECT rate_code_id, vendor_id, payment_type, tpep_dropoff_datetime, tpep_pickup_datetime, pu_location_id, do_location_id, fare_amount, extra, mta_tax, tip_amount, tolls_amount, improvement_surcharge, total_amount FROM demo_dwi_db.dwi_taxi_trip_data;
- 脚本名称:demo_etl_sdi_dwi,该脚本用于将SDI贴源层的原始数据写入到DWI层的标准出行数据表中。脚本内容如下:
作业开发
- 在DataArts Studio数据开发控制台的左侧导航栏中,单击“作业开发”,然后右键单击“作业”选择菜单“新建目录”,在目录树下根据需要创建作业目录,例如“transport”。
- 右键单击作业目录,在弹出菜单中单击。 图5 作业

- 在弹出弹框中输入“作业名称”如demo_taxi_trip_data,“作业类型”选择“批处理”,其他参数保留默认值,单击“确定”完成批作业创建。 图6 新建批处理作业

- 如下图所示,编排批作业。 图7 编排作业

每个节点配置如下:
- source_sdi节点:为CDM Job节点,通过CDM节点将OBS上的数据导入到MRS Hive的原始表中。其中CDM集群名称和作业名称分别选择在步骤3:数据集成中的集群和迁移作业(图中仅为示例,以实际集群名和迁移作业名为准)。 图8 source_sdi节点属性

- demo_etl_sdi_dwi节点:为MRS Hive SQL节点,用于清洗过滤SDI贴源层上原始表中的数据,将合法数据写入数据架构中DWI层标准出行数据表dwi_taxi_trip_data中。其中,“SQL脚本”请选择在脚本开发中创建的脚本demo_etl_sdi_dwi。 图9 demo_etl_sdi_dwi节点属性

- dwi数据监控节点:为Data Quality Monitor节点,用于监控DWI层的标准出行数据的质量。其中,“数据质量规则名称”请选择发布DWI层标准出行数据表时自动生成的质量规则“标准出行数据”。 图10 dwi数据监控节点

- demo_etl_dwi_dwr_fact节点:为MRS Hive SQL节点,用于将DWI上的原始数据写入DWR层的事实表fact_stroke_order中。其中,“SQL脚本”请选择在脚本开发中创建的脚本demo_etl_dwi_dwr_fact。 图11 demo_etl_dwi_dwr_fact节点属性

- 码表维度数据填充节点:为MRS Hive SQL节点,用于将付款方式、费率代码和供应商的集成数据写入DWR层相应的维度表中。其中,“SQL脚本”请选择在脚本开发中创建的脚本demo_taxi_dim_data。 图12 码表维度数据填充节点属性

- 等待节点:不做任何事情,等待前面的节点运行结束。 图13 等待节点

- 按付款方式汇总统计节点:为MRS Hive SQL节点,按付款方式维度统计汇总截止到当前日期的收入。该节点是从发布汇总表“付款方式统计汇总”时自动生成的数据开发作业(作业名称以demo_dm_db_dws_payment_type_开头,命名规则为“数据库名称_汇总表编码”)中复制的,复制节点后需手动配置该节点的“数据连接”和“数据库”参数,“数据库”需设置为事实表所在的数据库。 图14 按付款方式汇总统计节点属性

- 按费率汇总统计节点:为MRS Hive SQL节点,按费率代码维度统计汇总截止到当前日期的收入。该节点是从发布汇总表“费率统计汇总”时自动生成的数据开发作业(作业名称以demo_dm_db_dws_rate_code_开头,命名规则为“数据库名称_汇总表编码”)中复制的,复制节点后需手动配置该节点的“数据连接”和“数据库”参数,“数据库”需设置为事实表所在的数据库。 图15 按费率汇总统计节点属性

- 按供应商汇总统计节点:为MRS Hive SQL节点,按供应商维度统计汇总截止到当前日期各时间维度的收入。该节点是从发布汇总表“供应商统计汇总”时自动生成的数据开发作业(作业名称以demo_dm_db_dws_vendor_开头,命名规则为“数据库名称_汇总表编码”)中复制的,复制节点后需手动配置该节点的“数据连接”和“数据库”参数,“数据库”需设置为事实表所在的数据库。 图16 按供应商汇总统计节点属性

- Dummy_finish节点:不做任何事情,作为作业结束的标记。 图17 Dummy_finish节点

- source_sdi节点:为CDM Job节点,通过CDM节点将OBS上的数据导入到MRS Hive的原始表中。其中CDM集群名称和作业名称分别选择在步骤3:数据集成中的集群和迁移作业(图中仅为示例,以实际集群名和迁移作业名为准)。
- 作业编排好之后,您可以通过测试运行来测试作业编排是否正确。
- 您可以根据需要,配置作业的调度方式。单击右侧“调度配置”页签,展开配置页面。当前支持单次调度、周期调度和事件驱动调度作业。 图18 配置作业的调度方式
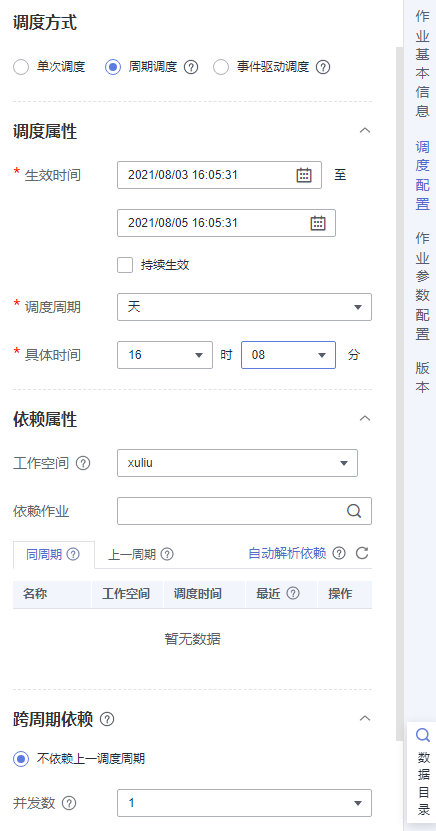
- 调度配置完成后,您需要单击“保存”按钮保存作业并单击“提交”按钮提交作业版本。然后单击“执行调度”来启动作业的调度。 图19 保存并提交作业与执行调度


运维调度
您可以通过运维调度功能,查看作业以及作业实例的运行状态。
- 在数据开发主界面的左侧导航栏,选择。
- 单击“批作业监控”页签,进入批作业监控界面。
- 批作业监控提供了对批处理作业的状态进行监控的能力。您可以查看批作业的调度状态、调度频率、调度开始时间等信息,勾选作业名称前的复选框,并进行“执行调度”/“停止调度”/“通知配置”,相应操作。 图20 批量处理作业

- 单击左侧导航栏,选择“运维调度 > 实例监控”,进入实例监控界面。
- 作业运行成功后,您可以在DataArts Studio数据目录中查看汇总表的数据预览,具体操作请参见步骤8:数据资产查看。您也可以在数据开发的“脚本开发”页面新建一个Hive SQL脚本,执行以下命令查询结果,执行成功后返回类似如下的结果:
1SELECT * FROM demo_dm_db.dws_payment_type;
图22 查询结果





