

配置模型路由策略
通过配置模型路由策略,您可以将多个已接入的模型服务按规则进行编排,实现模型故障自动切换能力。当主模型因故障、超时或不可用等原因无法正常响应时,系统将根据路由策略自动切换到其他可用模型继续提供服务,从而提升业务的稳定性与可用性。
当模型出现以下情况时触发切换:返回HTTP 5xx错误、响应超时(超过策略总超时时间)、返回空响应等。
路由策略工作流程:调用模型A -> 失败 -> 重试 -> 仍失败 -> 切换模型B -> ...。
例如,某在线客服系统使用DeepSeek-R1作为主模型,当该模型服务因维护或故障不可用时,自动切换至备用模型DeepSeek-V3,确保客服服务不中断。
路由策略创建完成后,可对路由入口进行调测验证,并在智能体中选择使用。
费用说明
路由策略本身不收费,但模型调用按各模型服务的计费规则收费。重试和故障切换产生的调用次数均正常计费,建议根据业务需求合理设置重试次数。
适用场景
- 已接入多个同类型模型服务(例如多个文本对话模型),希望在主模型不可用时自动切换,提升服务连续性。
- 业务对稳定性要求较高,希望降低单一模型服务异常带来的影响。
- 希望在不修改智能体配置的情况下,通过调整路由策略实现模型切换或扩容。
前提条件
创建路由策略
- 登录AgentArts智能体平台。
- 在左侧导航,选择“开发中心 > 开发配置”。
- 选择“路由策略”页签,单击“创建路由策略”。
- 在“创建路由策略”页面,配置参数信息,具体参数说明请参考表1,配置完成后单击“保存”。
界面提示“创建路由策略成功!”,新建的路由策略,显示在路由策略列表中。
图1 创建路由策略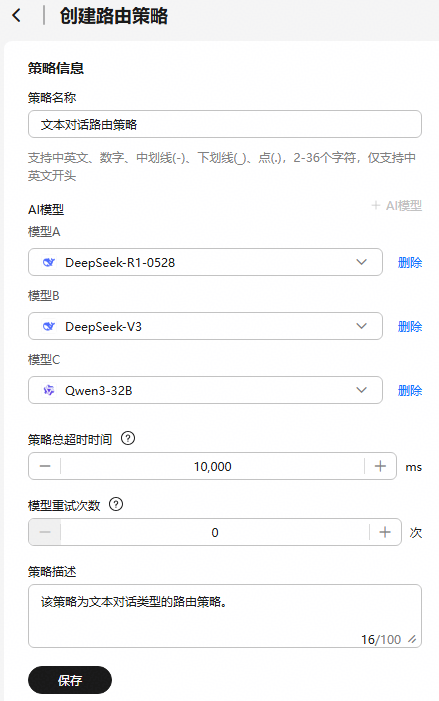
表1 路由策略参数说明 参数
说明
示例
策略名称
自定义路由策略的名称。由2~36个字符组成,包含中英文、数字、中划线(-)、下划线(_)、点(.),仅支持以中英文开头。
文本对话路由策略
AI模型
AI模型即模型服务。
在“模型A”下拉框中选择模型服务。仅支持选择文本对话类型的模型服务。
单击“+ AI模型”,添加模型服务。至少需添加1个模型服务,最多支持3个。
路由策略提供模型服务时,模型调用顺序为:模型A > 模型B > 模型C,当模型A无法正常工作时,可以自动依次切换为模型B、模型C。
验证故障切换:可在模型调测时临时将模型A设为不可用,观察是否自动切换至模型B并正常返回结果。
模型A:DeepSeek-R1
模型B:DeepSeek-V3
模型C:Qwen3-32B
策略总超时时间
模型路由策略的总体超时时间。取值范围为1000~1,000,000ms,默认值为10,000ms。
10000ms
模型重试次数
路由策略中单个模型服务的重试次数。取值范围为0-100次,默认值为0次。
注意:路由策略本身不收费,但模型调用按各模型服务的计费规则收费。重试和故障切换产生的调用次数均正常计费,建议根据业务需求合理设置重试次数。
0
策略描述
路由策略的描述信息。由1~100个字符组成。
该策略为文本对话类型的路由策略。
- 在“模型调测”区域,调测模型,具体参数说明请参考表2。 图2 调测模型
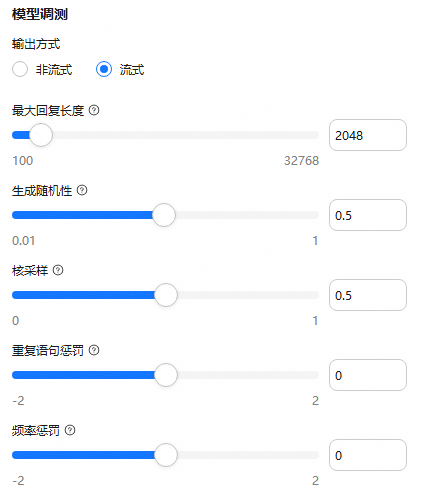
表2 模型调测参数说明 参数
参数
示例
输出方式
可选非流式、流式。
- 非流式:调用大语言模型推理服务时,根据用户问题,获取大语言模型的回答,大语言模型完整生成回答后一次性返回。
- 流式:调用大语言模型推理服务时,根据用户问题,获取大语言模型的回答,逐个字词的快速返回模式,不需等待大语言模型生成完成。默认流式。
流式
最大回复长度
设置模型生成内容的Tokens长度上限。数值越大,支持的回复越长;数值越小,回复可能被截断。取值范围为100~32768,默认值为2048。
2048
生成随机性
生成随机性(temperature)控制模型输出的随机性和创造性,取值范围0.01~1,默认值为0.5。
- 数值越高(接近1)使输出更具多样性和创新性,适合创造性任务如小说创作。
- 数值越低(接近0)使输出更加确定和一致,适合基于事实的问答和售后客服场景。
建议该参数和“核采样”只设置1个,避免同时调整后效果不可控。
0.5
核采样
核采样(Top-P)用于限制模型的选词范围。 取值范围0~1,默认值为0.5。
- 值接近0时,模型只从概率最高的前10%词汇中选择,输出更集中。
- 值接近1时,不做限制,输出更多样。
建议该参数和“生成随机性”只设置1个,避免同时调整后效果不可控。
0.5
重复语句惩罚
用于控制词汇和句式的重复率。取值范围-2.0~2.0,默认值为0。
- 正值鼓励多样化表达,减少重复。
- 负值鼓励复用已出现词汇。
- 设为0则不做干预。
建议发现AI回复频繁重复时适当调高。
0
频率惩罚
频率惩罚(frequency_penalty),正值尽量避免使用常见的单词和短语,而更倾向于生成较少见的单词。取值范围-2.0~2.0,默认值为0。
0
- 在右侧“预览调试”区域,在对话输入框输入测试语句后按Enter键或单击
 ,查看模型响应结果。
,查看模型响应结果。 调测区域显示模型正常返回回复内容,且响应时间在预期范围内,表示路由策略配置正确。
单击
 ,清除本次会话内容,可以开始新的会话。图3 路由调测
,清除本次会话内容,可以开始新的会话。图3 路由调测
常见问题
接入后调测,模型无返回结果或者报错怎么办?
Api-key填写错误,如多填写了Bearer前缀。
API Key本身已过期或无效,需要到模型服务商官网确认API Key状态,必要时重新生成。
相关操作
在“路由策略”列表,支持的其他操作请参考表3。




