
HPC Management and Scheduling Plug-in
Product Overview
The HPC management and scheduling plug-in is an end-to-end one-stop Huawei Cloud cluster resource usage and management platform that is developed based on Slurm. It provides one-click cluster delivery on a visualized interaction interface. It integrates SFS Turbo file systems to provide high-performance shared storage. You can perform operations on cluster users, compute resources, and service jobs on the UI. The plug-in supports quick modeling and computing in scenarios such as structural mechanics, fluid analysis, thermal simulation, and gene sequencing.
Core Functions
|
Function |
Description |
|---|---|
|
Divides logical resource pools and isolates resources of different teams or projects. |
|
|
Creates, destroys, and manages compute resources and monitors cluster metrics. |
|
|
Defines the physical topology structure (such as racks and switches) of a cluster and optimizes job scheduling policies. |
|
|
Submits tasks based on user requirements and queries task logs, job status, completion time, and scheduled nodes. |
|
|
Sets standard job configurations and submits tasks in one click. |
|
|
Configures at least one scaling policy for each partition to automatically scale in or out compute nodes based on the policy. |
|
|
Schedules jobs based on policies, such as by priority, first in, first out (FIFO), and backfill scheduling. |
|
|
Restricts resource usages of users or groups by QoS, accounts, and partitions to ensure fair access and prioritized use. |
|
|
Mounts SFS Turbo file systems to provide high-performance shared storage. Files smaller than 1 GB can be uploaded and downloaded on the cockpit UI. |
|
|
Adds tags to nodes for fine-grained management of resources in the same partition. |
|
|
Logs user operations and resource usages. |
|
|
Allows you to view node processes, system configurations, environment variables, and downloaded logs. |
|
|
Has a built-in administrator account that can be used to create and delete common users. These users are assigned different roles to access the cluster UIs. |
System Architecture and Deployment Requirements
Architecture Topology
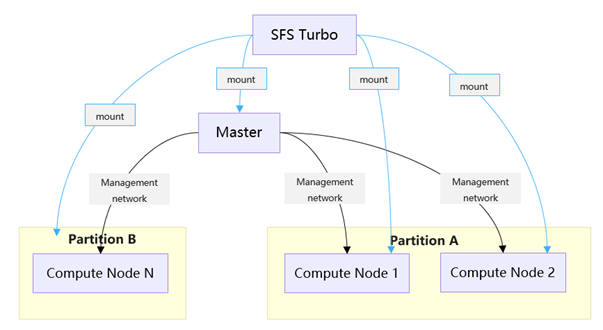
- Management and control nodes
- Master node: has 16 vCPUs, 32-GB memory, and a 300-GB disk and is responsible for cluster scheduling, user management, and audit log storage
- SFS Turbo: provides a shared file system. The mount path is /mnt/sfs_turbo_1.
- Compute nodes: Pay-per-use or yearly/monthly compute nodes are created on the cockpit UI or using elastic policies.
Deployment Requirements
|
Component |
Configuration Requirements |
|---|---|
|
Master node |
16 vCPUs, 32-GB memory, a 300-GB SSD disk, and associated with an EIP |
|
SFS Turbo |
On-demand capacity expansion by at least 1 TB and bandwidth of at least 1 Gbit/s |
|
Compute nodes |
You can create compute nodes on the cockpit UI and select specifications as required. |
Deployment
For details, see Deployment.
Other Advanced Features
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



