
What Is Data Lake Insight
DLI Introduction
Data Lake Insight (DLI) is a serverless data processing and analysis service fully compatible with Apache Spark, HetuEngine, and Apache Flink ecosystems. It frees you from managing any servers.
DLI supports multiple querying methods including standard SQL, Spark SQL, and Flink SQL, with compatibility with mainstream data formats. You can use standard SQL or Spark and Flink applications to query mainstream data formats without data ETL. DLI supports SQL statements and Spark applications for heterogeneous data sources, including RDS, DWS, CSS, OBS, custom databases on ECSs, and offline databases.
Video Introduction
This video introduces what DLI is.
DLI Compute Engines
DLI offers multiple compute engines, including Spark, HetuEngine, and Flink, each suited for different data processing scenarios.
Spark is better suited for batch processing and complex analysis of large-scale data, while Flink excels in real-time stream processing. HetuEngine is a high-performance interactive SQL analytics and data virtualization engine.
- Features:
Spark is a unified analytics engine designed for large-scale data processing, focusing on query, compute, and analysis.
DLI has undergone extensive performance optimization and service-oriented enhancements over the open-source Spark, maintaining compatibility with the Apache Spark ecosystem and APIs while boosting performance by 2.5 times, enabling exabyte-scale data queries and analyses within hours.
DLI's Spark engine supports batch processing and interactive analysis of large-scale data and provides high-performance distributed computing capabilities.
- Use cases
- Suitable for scenarios requiring large-scale batch processing and complex data analysis.
- Ideal for deep mining and analysis of historical data, such as querying data in a data warehouse and generating reports.
- Features
- Flink is a distributed computing engine that can be used for both batch processing and stream processing.
- DLI has enhanced features and security based on the open-source Flink and offers the Stream SQL feature needed for data processing.
- It supports real-time stream processing, capable of handling large-scale real-time data streams, with support for event time processing and state management.
- Use cases
- Suitable for scenarios requiring real-time data stream processing, such as real-time monitoring systems and real-time recommender systems.
- Ideal for fast analysis and response to real-time data, such as financial transaction monitoring and IoT device data processing.
- Features
HetuEngine is a high-performance interactive SQL analysis and data virtualization engine, seamlessly integrating with the big data ecosystem to achieve second-level interactive queries on massive datasets.
HetuEngine + LakeFormation can quickly handle query requests on large-scale datasets, swiftly and efficiently extracting information from big data, significantly simplifying data management and analysis processes, and enhancing indexing and query performance in a big data environment.
For more information about HetuEngine, see HetuEngine Syntax Reference.
Figure 1 DLI supporting HetuEngine + LakeFormation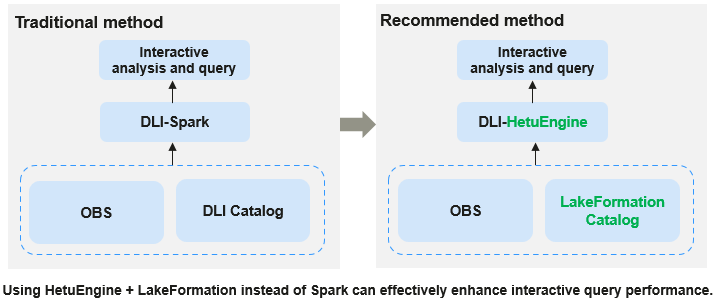
- Responses to terabytes of data within mere seconds:
Through automatic optimization of resource and load balancing, HetuEngine can respond to TB-level data within seconds, significantly improving the efficiency of data queries.
- Serverless resources ready to use:
The serverless service model requires no attention to underlying configurations, software updates, or failure issues, making resources easy to maintain and expand.
- Multiple resource types to meet various service requirements:
Shared resource pool: pay-per-use billing, providing more cost-effective compute resources.
Dedicated resource pool: offers a dedicated resource pool to meet high-performance resource requirements.
- Data ecosystem enhancement:
HetuEngine and LakeFormation can connect to mainstream BI tools, such as Yonghong BI, FineBI, and DBeaver, to enhance the application capabilities in the data analysis field.
- 5x real-time data processing performance
HetuEngine + LakeFormation supports Apache Hudi's copy-on-write (COW) and merge-on-read (MOR) tables. The vertex query performance is 5 times better compared to open-source Trino, enabling faster response to query requests and providing real-time data access.
- Responses to terabytes of data within mere seconds:
- Use cases
Suitable for data query and analysis in large-scale data storage.
Core Functions
For details about DLI functions, see Features.
|
Function |
Description |
|---|---|
|
DLI is a data processing and analytics service built on the serverless architecture. |
DLI is a serverless big data query and analytics service. With DLI, you only pay for the actual compute resources used, with no need to maintain or manage cloud servers.
|
|
DLI supports multiple compute engines. |
DLI is fully compatible with ecosystems like Apache Spark, HetuEngine, and Apache Flink, and supports standard SQL, Spark SQL, and Flink SQL. It is compatible with mainstream data formats such as CSV, JSON, Parquet, and ORC.
|
|
DLI supports multiple connection methods. |
DLI provides multiple connection methods to meet diverse user needs and scenarios. Connection methods:
For more DLI connection methods, see Development Tools Supported by DLI. |
|
DLI can connect to multiple data sources for cross-source data analysis. |
|
|
Three basic job types supported by DLI |
|
|
DLI supports decoupled storage and compute. |
After storing data in OBS, you can connect DLI to OBS for data analysis. Under the decoupled storage and compute architecture, storage resources and compute resources can be requested and billed separately, reducing costs and improving resource utilization. You can choose single-AZ or multi-AZ storage when creating an OBS bucket for storing redundant data on the DLI console. The differences between the two storage policies are as follows:
|
|
DLI manages and schedules resources in a unified manner using elastic resource pools. |
The backend of elastic resource pools adopts a CCE cluster architecture, supporting heterogeneous resources, so you can manage and schedule resources in a unified manner. For details, see Overview of DLI Elastic Resource Pools and Queues. |
DLI Product Architecture
The DLI product architecture is as follows:
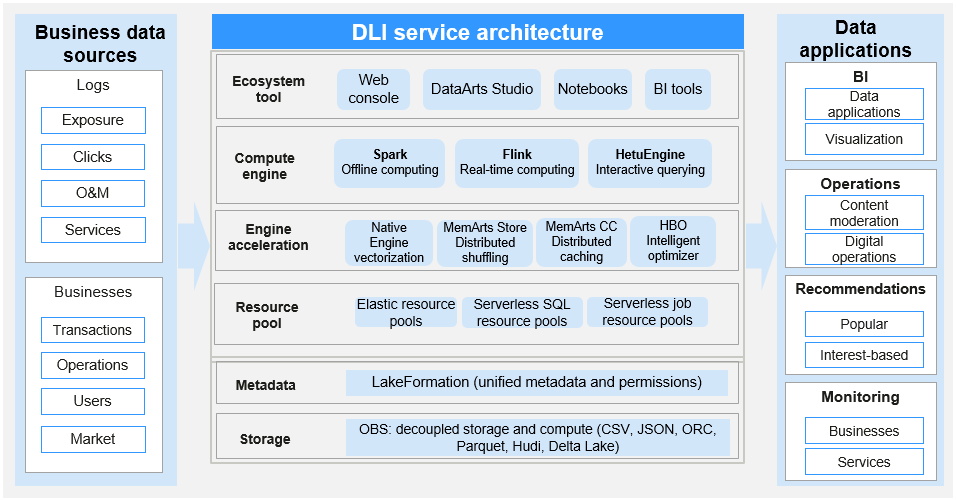
DLI includes the following core modules:
|
Module |
Description |
|---|---|
|
Ecosystem tools |
DLI leverages its robust serverless architecture and multimodal engine support to fulfill the diverse needs of various industries, driving their digital transformation and fostering innovation. |
|
Compute engine |
|
|
Unified resource management |
|
|
Unified metadata management |
|
|
Storage service |
OBS and databases are used to store structured or unstructured data for data analysis, providing persistent data storage services. |
|
Data source connection |
|
|
Data applications |
DLI can connect to mainstream BI tools in the industry to flexibly meet data presentation needs. |
Accessing DLI
A web-based service management platform is provided. You can access DLI using the management console or HTTPS-based APIs, or connect to the DLI server through the JDBC client.
For more DLI connection methods, see Development Tools Supported by DLI.
- Using the management console
You can submit SQL, Spark, or Flink jobs on the DLI management console.
Log in to the management console. Choose EI Enterprise Intelligence > Data Lake Insight from the service list.
- Using APIs
If you need to integrate DLI into a third-party system for secondary development, you can call DLI APIs to use the service.
For details, see Data Lake Insight API Reference.
- JDBC
You can use JDBC to connect to the server for data query. For details, see Obtaining the Server Connection Address.
- DataArts Studio
DataArts Studio is a one-stop data operations platform that provides intelligent data lifecycle management. It supports intelligent construction of industrial knowledge libraries and incorporates data foundations such as big data storage, computing, and analysis engines. With DataArts Studio, your company can easily construct end-to-end intelligent data systems. These systems can help eliminate data silos, unify data standards, accelerate data monetization, and promote digital transformation.
Create a data connection on the DataArts Studio management console to access DLI for data analysis.
For how to use DataArts Studio, see DataArts Studio Product Documentation.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



