
Uso de un clúster de RegionlessDB para DR multiactiva remota
Escenarios
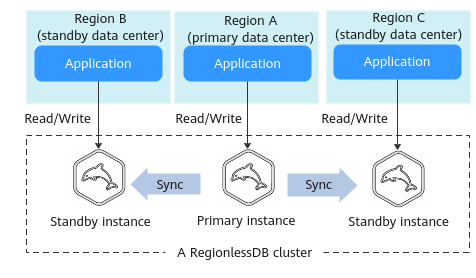
Si sus cargas de trabajo se despliegan en varias regiones, puede crear un clúster de RegionlessDB para acceder a las bases de datos desde la región más cercana. Como se muestra en la Figura 1, un clúster de RegionlessDB contiene una instancia principal y dos instancias de en espera. Las solicitudes de lectura se envían a una instancia de en espera en la región más cercana y las solicitudes de escritura se reenvían automáticamente desde la región más cercana a la instancia principal. Después de escribir los datos en la instancia principal, los datos se sincronizan con todas las instancias de en espera, lo que reduce la latencia de red entre regiones.
Restricciones
Para más detalles, véase Restricciones.
Procedimiento
Paso 1: Crear un clúster de RegionlessDB
- Inicie sesión en la consola de gestión.
- Haga clic en
 en la esquina superior izquierda y seleccione una región y un proyecto.
en la esquina superior izquierda y seleccione una región y un proyecto. - Haga clic en
 en el extremo superior izquierdo de la página y seleccione Databases > TaurusDB.
en el extremo superior izquierdo de la página y seleccione Databases > TaurusDB. - En la página RegionlessDB, haga clic en Create RegionlessDB en el extremo superior derecho. Figura 2 Creación de un clúster de RegionlessDB

- En el cuadro de diálogo Create RegionlessDB, configure RegionlessDB Name, Primary Instance Region y Primary Instance. Figura 3 Configuración de la información del clúster de RegionlessDB

Tabla 1 Descripción del parámetro Parámetro
Descripción
RegionlessDB Name
El nombre debe comenzar con una letra y debe contener entre 4 y 64 caracteres. Solo se permiten letras (distinguen mayúsculas de minúsculas), dígitos, guiones (-) y guiones bajos (_).
Primary Instance Region
Seleccione una región en la que se encuentra la instancia principal.
Primary Instance
Seleccione una instancia de BD existente como instancia principal del clúster RegionlessDB.
- Haga clic en OK.
- Una vez creada la instancia principal, véala y gestiónela.
Durante el proceso de creación, el estado de la instancia es Creating. Para ver el progreso detallado y el resultado de la creación, vaya a la página Task Center. Una vez que el estado de la instancia principal es Available, puede utilizar la instancia.
Paso 2: Agregar una instancia en espera
- En la página RegionlessDB, localice el clúster de RegionlessDB.
- Haga clic en Add Standby Instance en la columna Operation. Figura 4 Adición de una instancia de en espera

- En la página mostrada, configure los parámetros relacionados.
Tabla 2 Información básica Parámetro
Descripción
Region
Región donde se despliega la instancia en espera.
AVISO:Los productos de diferentes regiones no pueden comunicarse entre sí a través de una red privada. Después de comprar una instancia de BD, la región no se puede cambiar.
Creation Method
Crear nuevo
DB Instance Name
El nombre debe comenzar con una letra y debe contener entre 4 y 64 caracteres. Solo se admiten letras, dígitos, guiones (-) y guiones bajos (_).
DB Engine
TaurusDB
DB Engine Version
MySQL 8.0
Kernel Version
Versión del kernel de la instancia en espera. La versión del kernel debe ser 2.0.46.231000 o posterior.
Para obtener detalles sobre las actualizaciones en cada versión menor del kernel, véase Historial de versiones del kernel TaurusDB.
NOTA:Para configurar la versión del kernel, póngase en contacto con el servicio al cliente.
DB Instance Type
Solo se pueden seleccionar Cluster. Hay de 2 a 10 réplicas de lectura en una instancia de clúster en el clúster de RegionlessDB.
Storage Type
Compartido
AZ Type
Una AZ es una región física donde los recursos tienen su propia fuente de alimentación y redes independientes. Las AZ están físicamente aisladas, pero se interconectan a través de una red interna. Algunas regiones admiten el despliegue de una sola AZ y varias AZ y algunas solo admiten el despliegue de una sola AZ.
- Single AZ: El nodo primario y las réplicas de lectura se despliegan en la misma AZ.
- Multi-AZ: El nodo primario y las réplicas de lectura se despliega en diferentes zonas de disponibilidad para garantizar una alta confiabilidad.
Time Zone
Debe seleccionar una zona horaria para la instancia en función de la región que alberga la instancia. La zona horaria se selecciona durante la creación de la instancia y no se puede cambiar después de crear la instancia.
Instance Specifications
Para obtener detalles sobre las especificaciones admitidas por TaurusDB, véase Especificaciones de instancia.
TaurusDB es una base de datos nativa de la nube que utiliza el almacenamiento compartido. Para garantizar la estabilidad de la carga de trabajo en alta presión de lectura/escritura, el sistema controla los picos de lectura/escritura de las instancias de BD según las especificaciones de la instancia. Para obtener más información sobre cómo seleccionar especificaciones, véase Nota técnica de rendimiento.
CPU Architecture
La arquitectura de CPU puede ser x86 o Kunpeng. En una arquitectura de CPU, debe seleccionar las vCPU y la memoria de la instancia.
Nodes
Todos los nodos de la instancia en espera son réplicas de lectura. Puede solicitar un máximo de 10 réplicas de lectura a la vez para una instancia de pago por uso.
Después de crear una instancia, puede agregar réplicas de lectura según sea necesario. Se pueden crear hasta 15 réplicas de lectura para una instancia de en espera en un clúster.
Storage
El almacenamiento se ampliará dinámicamente en función de la cantidad de datos que se deben almacenar, y se facturará por hora sobre una base de pago por uso.
VPC
- Una red virtual dedicada en la que se encuentra su instancia de TaurusDB. Aísla las redes para diferentes cargas de trabajo. Puede seleccionar una VPC existente o crear una VPC. Para obtener más información sobre cómo crear una VPC, véase Creación de una VPC.
Si no hay ninguna VPC disponible, TaurusDB le asigna una VPC de forma predeterminada.
AVISO:- Asegúrese de que la VPC seleccionada para la instancia en espera esté conectada a la VPC seleccionada para la instancia principal con una VPN.
- Después de crear una instancia de TaurusDB, la VPC no se puede cambiar.
- Una subred proporciona los recursos de red dedicados que están lógicamente aislados de otras redes para la seguridad de la red.
Una dirección IP privada se asigna automáticamente cuando se crea una instancia de BD. También puede introducir una dirección IP privada inactiva en el bloque CIDR de subred.
Security Group
Puede mejorar la seguridad al controlar el acceso a TaurusDB desde otros servicios. Cuando selecciona un grupo de seguridad, debe asegurarse de que permite que el cliente acceda a las instancias.
Si no hay ningún grupo de seguridad disponible o se ha creado, TaurusDB le asigna un grupo de seguridad de forma predeterminada.
NOTA:- Para garantizar la conexión y el acceso a la base de datos posteriores, debe permitir que todas las direcciones IP accedan a su instancia de BD a través del puerto 3306 y con ICMP.
- Configure reglas de grupo de seguridad de red privada para garantizar que las instancias principal y en espera de un clúster puedan comunicarse entre sí.
Parameter Template
Contiene valores de configuración del motor que se pueden aplicar a una o más instancias. Puede modificar los parámetros de instancia según sea necesario después de crear la instancia.
AVISO:Si utiliza una plantilla de parámetros personalizada al crear una instancia de base de datos, no se aplican los siguientes parámetros relacionados con la especificación en la plantilla personalizada. En su lugar, se utilizan los valores predeterminados.
innodb_buffer_pool_size
innodb_log_buffer_size
max_connections
innodb_buffer_pool_instances
innodb_page_cleaners
innodb_parallel_read_threads
innodb_read_io_threads
innodb_write_io_threads
threadpool_size
Después de crear una instancia de BD, puede ajustar sus parámetros según sea necesario. Para más detalles, consulte Modificación de parámetros en una plantilla de parámetros.
Enterprise Project
Solo disponible para usuarios de empresa. Si desea utilizar esta función, póngase en contacto con el servicio de atención al cliente.
Un proyecto empresarial proporciona una manera de gestionar los recursos de la nube y los miembros de la empresa en una base de proyecto por proyecto.
Puede seleccionar un proyecto de empresa en la lista desplegable. El proyecto predeterminado es default.
Tag
Este parámetro es opcional. Agregar etiquetas le ayuda a identificar y gestionar mejor sus instancias de base de datos. Cada instancia de BD puede tener hasta 20 etiquetas.
Después de crear una instancia de base de datos, puede ver los detalles de su etiqueta en la pestaña Tags. Para obtener más información, véase Gestión de etiquetas.
La contraseña de instancia y el nombre de tabla distinguen entre mayúsculas y minúsculas y minúsculas que las de la instancia principal. No es necesario configurarlos por separado.
- Haga clic en Next.
- Confirme la información y haga clic en Submit.
- Vaya a la página Instances para ver y gestionar la instancia.
Durante el proceso de creación, el estado de la instancia es Creating. Para ver el progreso detallado y el resultado de la creación, vaya a la página Task Center. Después de que el estado de la instancia sea Available, puede utilizar la instancia.
Si hay una gran cantidad de datos en la instancia principal, puede llevar mucho tiempo completar una copia de respaldo completo durante la creación de la instancia de en espera.
Paso 3: Habilitar el reenvío de escritura
En casos normales, después de crear un clúster de RegionlessDB, la instancia principal recibe y procesa solicitudes de lectura y escritura, y las instancias de en espera solo reciben solicitudes de lectura. Después de habilitar el reenvío de escritura, las instancias de en espera pueden recibir solicitudes de escritura y luego reenviarlas a la instancia principal para su procesamiento. Después de escribir los datos en la instancia principal, los datos se sincronizan con todas las instancias de en espera. El reenvío de escritura simplifica el proceso de escritura de datos. Puede conectar directamente un servicio de base de datos con la dirección IP de una instancia de en espera para realizar operaciones de lectura y escritura. Además, se garantiza la coherencia y la lectura cercana no se ve afectada.

- El reenvío de escritura solo está disponible cuando el nivel de aislamiento de transacciones de las instancias en espera es RR.
- En la versión actual, la información de WARNING y RECORD no se puede mostrar cuando una instancia de en espera reenvía solicitudes de escritura.
- En la versión actual, las solicitudes SQL que se están ejecutando no se pueden interrumpir cuando una instancia de en espera reenvía solicitudes de escritura.
- Cuando el reenvío de escritura está habilitado, se crea el usuario _@gdb_WriteForward@_. No modifique ni elimine el usuario o el reenvío de escritura no se ejecutará correctamente.
- Se admiten los siguientes comandos para el reenvío de escritura:
- SQLCOM_UPDATE
- SQLCOM_INSERT
- SQLCOM_DELETE
- SQLCOM_INSERT_SELECT
- SQLCOM_REPLACE
- SQLCOM_REPLACE_SELECT
- SQLCOM_DELETE_MULTI
- SQLCOM_UPDATE_MULTI
- SQLCOM_ROLLBACK
Si se ejecuta un comando no admitido, se muestra la siguiente información de error.ERROR xxx (yyy): This version of MySQL doesn't yet support 'operation with write forwarding'.
operation indica el tipo de operación que no se soporta.
- No se admiten los siguientes escenarios:
- Existen instrucciones SELECT FOR UPDATE.
- Hay sentencias de reenvío de escritura EXPLAIN.
- Las sentencias para el reenvío de escritura contienen SET VARIABLE.
- SAVEPOINT no se admite cuando se habilita el reenvío de escritura.
- El reenvío de escritura no se admite en las transacciones XA.
- Actualmente, no se admite START TRANSACTION READ WRITE. Puede utilizar directamente START TRANSACTION para probar el reenvío de escritura.
- Los procedimientos almacenados no admiten el reenvío de escritura.
- Cuando el reenvío de escritura está habilitado, no se pueden crear tablas temporales. Para crear tablas temporales, deshabilite temporalmente el reenvío de escritura.
- Para los comandos que se pueden confirmar implícitamente, si no se admite el reenvío de escritura, las transacciones correspondientes al nodo actual y al nodo primario se confirman automáticamente.
- Para el nivel de consistencia global, antes de acceder a los datos por primera vez, cada transacción necesita usar una conexión en la sesión grupo para obtener un punto de datos (LSN) del nodo primario. Si no hay sesiones disponibles, el comando para leer datos puede fallar.
- Si se produce un error de conexión cuando un usuario utiliza una sesión para reenvío de escritura y el usuario está en una transacción de varias instrucciones, el servidor cierra de forma proactiva las conexiones con el cliente y el nodo principal, lo que garantiza que el cliente puede detectar el error.
- Las versiones de las instancias primaria y en espera deben ser las más recientes.
- Las operaciones de escritura se reenvían finalmente al nodo primario y son procesadas por este. Si existe una tabla temporal con el mismo nombre en la base de datos dada de las réplicas principal y de lectura, se utilizan los datos del nodo principal.
- Si hay una conmutación primaria/en espera o conmutación por error para una instancia de en espera en un clúster de RegionlessDB, los parámetros de reenvío de escritura (rds_open_write_forwarding y rds_write_forward_read_consistency) se restauran a los valores predeterminados.
- En la página RegionlessDB, localice el clúster de RegionlessDB.
- Haga clic en Set Write Forwarding en la columna Operation para crear una cuenta de reenvío de escritura. Figura 5 Crear una cuenta de reenvío de escritura

El sistema crea automáticamente una cuenta interna (_@gdb_WriteForward@_) para que las solicitudes de escritura se puedan reenviar a la instancia principal para su procesamiento. No puede modificar ni eliminar la cuenta interna, ya que el reenvío de escritura se verá afectado.
- En el cuadro de diálogo Set Write Forwarding, confirme la información y haga clic en OK. Figura 6 Establecer reenvío de escritura

- En la página Instances, haga clic en el nombre de la instancia en espera en el clúster de RegionlessDB.
- En el panel de navegación, elija Parameters.
- Busque rds_open_write_forwarding en la esquina superior derecha de la página Parameters y cambie su valor a ON.
- Haga clic en Save en el extremo superior izquierdo para habilitar el reenvío de escritura.
- Busque rds_write_forward_read_consistency en la esquina superior derecha de la página Parameters y cambie el nivel de coherencia de lectura del reenvío de escritura.
Puede modificar los parámetros para configurar el rango de consistencia de lectura. Para más detalles, véase Tabla 3.
Tabla 3 Descripción del parámetro Parámetro
Descripción
NONE
Reenvío de escritura deshabilitado.
EVENTUAL
Los resultados de las operaciones de escritura no son visibles hasta que se realizan las operaciones de escritura en la instancia principal. La consulta no espera a que se complete la sincronización de datos entre las instancias principal y en espera, por lo que es posible que se lean los datos no actualizados.
SESSION
Todas las consultas ejecutadas por una instancia de en espera con reenvío de escritura habilitado ven los resultados de todas las escrituras de datos realizadas en esta sesión. Las consultas esperan a que se repliquen los resultados de las operaciones de escritura reenviadas.
GLOBAL
Una sesión puede ver todos los cambios confirmados de todas las sesiones e instancias en un clúster de RegionlessDB. La consulta puede esperar un cierto período, que está relacionado con la latencia de la réplica.
- Si se requiere coherencia de lectura, se recomienda establecer el nivel de coherencia en SESSION. El nivel de consistencia GLOBAL causará un gran costo extra para todas las solicitudes de lectura. Por ejemplo, si se utiliza cualquier cliente para conectarse a TaurusDB y se utiliza el nivel GLOBAL, el tiempo para acceder a la línea de comandos de MySQL se prolonga.
- El nivel de consistencia de lectura en el reenvío de escritura no se puede cambiar a SESSION en una transacción.
- Antes de habilitar el reenvío de escritura, asegúrese de que los niveles de aislamiento de transacciones de las instancias de en espera sean RR.
- Cuando el reenvío de escritura está habilitado, el nivel de aislamiento de transacciones de la sesión actual no se puede cambiar.
- El nivel de coherencia de lectura no se puede cambiar en una transacción.
- Haga clic en Save en la esquina superior izquierda.




