

常见错误原因和解决方法
训练中常见错误链接如下,根据实际情况选择相应链接:
- 显存溢出错误
- 网卡名称错误
- 保存ckpt时超时报错
- DockerFile或install.sh安装三方依赖包失败
- Llama-Factory框架数据预处理过大数据集超时
- Llama-Factory框架训练过程中训练至某一步卡死现象
- Llama-Factory环境,运行DockerFile或install.sh中的setup.py失败
- MindSpeed-LLM蒸馏模型训练精度问题
- 问题九 DeepSeek-V3或R1报错“Please install cann-nnal package first”
问题一 显存溢出错误
在训练过程中,常见显存溢出报错,示例如下:
RuntimeError: NPU out of memory. Tried to allocate 1.04 GiB (NPU 4; 60.97 GiB total capacity; 56.45 GiB already allocated; 56.45 GiB current active; 1017.81 MiB free; 56.84 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation.
【解决措施】MindSpeed-LLM和Llama-Factory解决方式有所区别,根据所选框架选择。
- MindSpeed-LLM
- 通过npu-smi info查看是否有进程资源占用NPU,导致训练时显存不足。解决可通过kill掉残留的进程或等待资源释放。
- 可调整参数:TP张量并行(tensor-model-parallel-size) 和PP流水线并行(pipeline-model-parallel-size),可以尝试增加 TP和PP的值,一般TP×PP≤NPU数量,并且要被整除。
- 可调整参数:MBS指最小batch处理的样本量(micro-batch-size)、GBS指一个iteration所处理的样本量(global-batch-size)。可将MBS参数值调小至1,但需要遵循GBS/MBS的值能够被NPU/(TP×PP)的值进行整除。
- 可调整参数:SEQ_LEN要处理的最大的序列长度(seq-length),参数值过大很容易发生显存溢出的错误。
- 可添加参数:在3_training.sh文件中添加开启重计算的参数。其中recompute-num-layers的值为模型网络中num-layers的参数值。
--recompute-granularity full \ --recompute-method block \ --recompute-num-layers {NUM_LAYERS} \
- Llama-Factory
- 调整参数:per_device_train_batch_size(MBS)指最小batch处理的样本量,可将MBS参数值调小至1。
- 调整参数:deepspeed,调整zero级别,依次递增。
- - ZeRO-0: 数据分布到不同的NPU
- - ZeRO-1: Optimizer States分布到不同的NPU
- - ZeRO-2: Optimizer States、Gradient分布到不同的NPU
- - ZeRO-2-Offload: Optimizer States分布到不同的NPU且开启Offload
- - ZeRO-3: Optimizer States、Gradient、Model Parameter分布到不同的NPU
- - ZeRO-3-Offload: Optimizer States、Gradient、Model Parameter分布到不同的NPU且开启Offload。
- 增大卡数,依次递增。
问题二 网卡名称错误
当训练开始时提示网卡名称错误或者通信超时,可以使用ifconfig命令检查网卡名称配置是否正确。
比如,ifconfig看到当前机器IP对应的网卡名称为enp67s0f5,则可以设置环境变量指定该值。
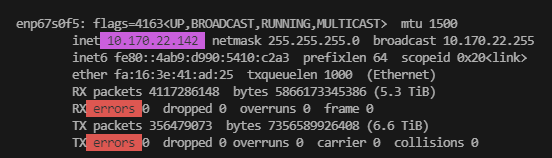
export GLOO_SOCKET_IFNAME=enp67s0f5 # 多机之间使用gloo通信时需要指定网口名称, export TP_SOCKET_IFNAME=enp67s0f5 # 多机之间使用TP通信时需要指定网口名称 export HCCL_SOCKET_IFNAME=enp67s0f5 # 多机之间使用HCCL通信时需要指定网口名称
关于环境变量的解释可以参考:Distributed communication package - torch.distributed — PyTorch 2.3 documentation
问题三 保存ckpt时超时报错
在多节点集群训练完成后,只有部分节点会保存权重,而其他节点会一直在等待通信。当等待时间超过36分钟时,会发生超时的错误。

【解决措施】
- 需要保证磁盘IO带宽正常,可以在36分钟内将文件保存到磁盘。单个节点内,最大只有60G(实际应该在40G以下)的文件内容,只要在36分钟内保存完成,就不会报超时错误。
- 忽略该报错,因为报错不影响实际报错的权重。
问题四 DockerFile或install.sh安装三方依赖包失败
【问题现象】
下载安装AscendFactory/dependences.yaml中三方依赖包:Llama-Factory、MindSpeed-LLM等失败。

【问题根因】
无法连接公网导致拉取git失败。
【解决措施】
配置代理或使用有公网权限的机器手动拉取AscendFactory/dependences.yaml中的三方依赖包,命名、版本与dependences.yaml中${save_name}、${version}值保持一致,并将其复制至AscendFactory/third-party目录下,重新DockerFile或执行install.sh命令。
问题五 Llama-Factory框架数据预处理过大数据集超时
【问题根因】
Llama-Factory框架处理数据默认先处理0卡,再依次处理1~7卡,串行处理数据导致时间占用过大导致超时。
【解决措施】
- 方案A:修改LLamaFactory barrier策略,将0卡先处理,1~7卡再处理方案修改为0~7卡同步处理,训练前执行以下命令:
export DISABLE_MAIN_PROCESS_FIRST = True
- 方案B:默认处理策略不变,将训练作业运行超时时间修改为2小时,训练前执行以下命令:
export ACL_DEVICE_SYNC_TIMEOUT=7200
方案B操作简单,但数据集过大时,有可能2个小时也会超时,可以继续修改延长超时时间。
问题六 Llama-Factory框架训练过程中训练至某一步卡死现象
【问题现象】
多节点训练任务,运行至某一个steps时训练任务卡死2H,导致任务超时

【问题根因】
ascend_trace线程抓取调用栈时对相关资源加锁,dataloader_worker进程在被fork拉起时继承了锁状态,导致dataloader_worker进程因无法获取到锁而卡死。
【解决措施】
训练作业前,先通过加载环境变量export ASCEND_COREDUMP_SIGNAL=none关闭ascend的堆栈跟踪。
export ASCEND_COREDUMP_SIGNAL=none
问题七 Llama-Factory环境,运行DockerFile或install.sh中的setup.py失败
【问题现象】
执行Llama-Factory代码目录下setup.py失败,报错:“SetuptoolsDeprecationWarning: License classifiers are deprecated.”

【问题根因】
pip依赖包版本过低导致与其他依赖包冲突。
【解决措施】

问题八 MindSpeed-LLM蒸馏模型训练精度问题
【问题根因】
MindSpeed-LLM框架中某些参数值为固定值,与蒸馏后模型配置不一致,导致训练结果精度问题。
【解决措施】
训练前修改代码包目录下scripts_modellink/{model}/3_training.sh文件参数值与蒸馏模型权重目录下config.json参数值保持一致,参数表格如下:
|
蒸馏模型 |
原模型 |
3_training.sh文件参数 |
|---|---|---|
|
DeepSeek-R1-Distill-Qwen-7B |
qwen2.5-7b |
--rotary-base 10000 |
|
DeepSeek-R1-Distill-Qwen-14B/32B |
qwen2.5-14b/32b |
--norm-epsilon 1e-5 |
问题九 DeepSeek-V3或R1报错“Please install cann-nnal package first”
【问题现象】
MindSpeed-LLM框架基于Snt9B23环境训练DeepSeek-V3或DeepSeek-R1报错“Please install cann-nnal package first”。
【问题根因】
MindSpeed-LLM框架训练镜像中未安装“cann-nnal ”包,需手动安装。
【解决措施】
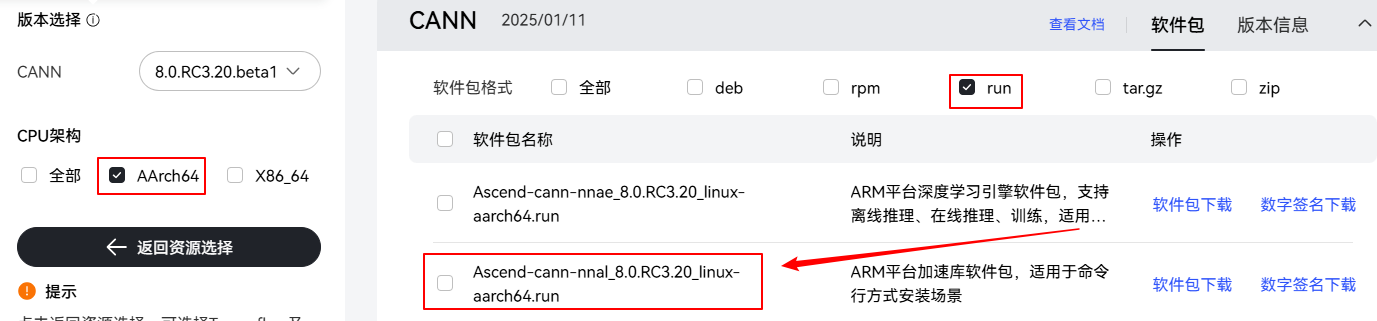
- 下载“cann-nnal_8.0.RC3.20”软件包:Ascend-cann-nnal_8.0.RC3.20_linux-aarch64.run并解压上传到容器内,如下图所示。
图4 下载“cann-nnal_8.0.RC3.20”软件包
- 根据训练场景选择执行以下步骤:
- Lite Server环境:在启动任务前进入“cann-nnal_8.0.RC3.20”软件包父目录,执行以下命令安装“cann-nnal ”包。
source /usr/local/Ascend/ascend-toolkit/set_env.sh # 安装cann-nnal包需要source环境变量 bash Ascend-cann-nnal_8.0.RC3.20_linux-aarch64.run --install # 设置环境变量 source /usr/local/Ascend/nnal/atb/set_env.sh
- ModelArts Standard环境
- 本地上传“cann-nnal_8.0.RC3.20”软件包,可参考上传代码包【OBS桶或SFS Turbo共享盘】将软件包解压并放置在代码包的AscendFactory目录下。
- 在创建训练任务时,在启动命令的最前面加入以下命令:
cd <${AscendFactory_dir}> # 进入代码目录路径,参考代码路径解释。 source /usr/local/Ascend/ascend-toolkit/set_env.sh # 安装cann-nnal包需要source环境变量 bash Ascend-cann-nnal_8.0.RC3.20_linux-aarch64.run --install # 设置环境变量 source /usr/local/Ascend/nnal/atb/set_env.sh
- Lite Server环境:在启动任务前进入“cann-nnal_8.0.RC3.20”软件包父目录,执行以下命令安装“cann-nnal ”包。




