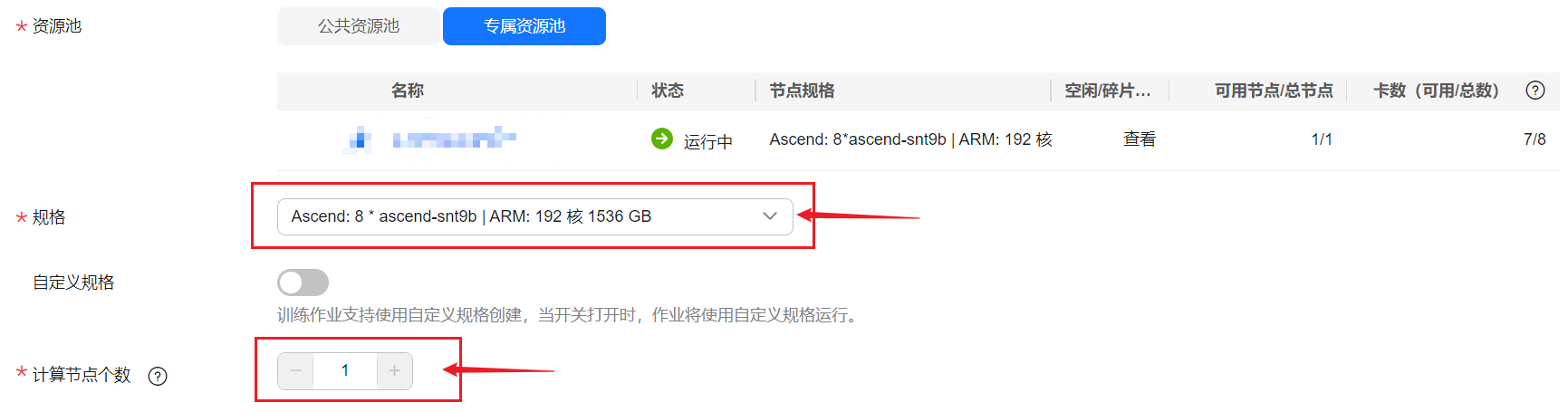
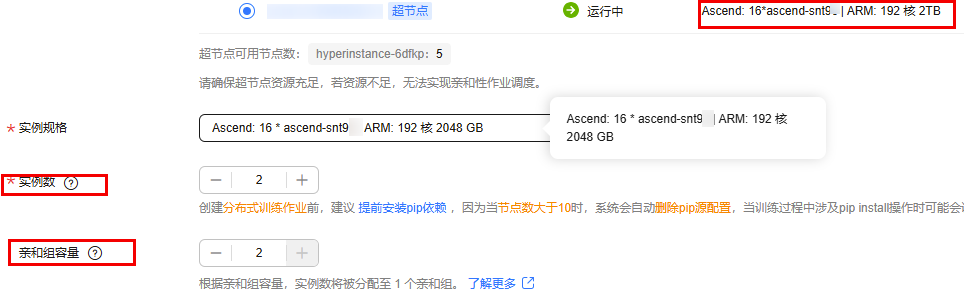
ModelArts Standard环境
前提条件
已上传训练代码、训练权重文件和数据集到OBS或SFS Turbo共享盘中,具体参考OBS桶或SFS Turbo共享盘,根据实际选择所需存储方式。
步骤一:创建训练任务
登录ModelArts管理控制台,在左侧导航栏选择“模型训练 > 训练作业”进入训练作业页面,单击“创建训练作业”,进入创建页面。
创建训练作业,并自定义名称、描述等信息。选择自定义算法,启动方式自定义,以及选择上传的镜像,样例截图如下。
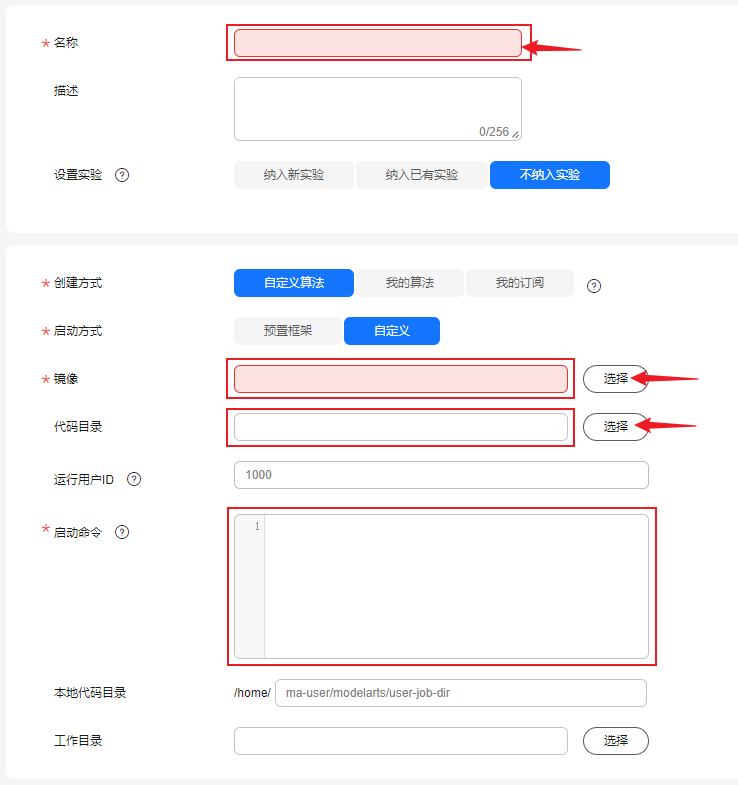
- 代码目录选择【OBS方式】:OBS桶路径obs://<bucket_name>llm_train/AscendFactory代码目录,如使用SFS Turbo共享盘可不设置此参数。
- 镜像选择:基础镜像、DockerFile制作后的训练镜像【二选一】
- 启动命令输入:使用镜像不同,启动命令不同,具体命令详见以下:
- 基础镜像
cd <${AscendFactory_dir}> # 进入代码目录路径 sh install.sh {训练框架名称}; # 可选【mindspeed-llm,llamafactory,verl】 source /usr/local/Ascend/ascend-toolkit/set_env.sh; ascendfactory-cli config --backend=<backend> --af_model_name=<af_model_name> --exp_name=<exp_name> --output_file_path=<output_file_path> && ascendfactory-cli train <output_file_path> - DockerFile制作后镜像
cd <${AscendFactory_dir}> # 进入代码目录路径 source /usr/local/Ascend/ascend-toolkit/set_env.sh; ascendfactory-cli config --backend=<backend> --af_model_name=<af_model_name> --exp_name=<exp_name> --output_file_path=<output_file_path> && ascendfactory-cli train <output_file_path>命令详解如下:- <${AscendFactory_dir}> : 代码目录路径。
- OBS方式路径:/home/ma-user/modelarts/user-job-dir/AscendFactory。
- SFS Turbo方式:根据实际选择,如/mnt/sfs_turbo/llm_train/AscendFactory。
- <backend>:所选框架类型,可选【mindspeed-llm,llamafactory,verl】。
- <af_model_name>:训练模型
- <exp_name>:所选实验类型,MindSpeed-LLM和Llam-Factory微调可选【full-4k, lora-4k, full-8k, lora-8k】,MindSpeed-LLM框架选用预训练【PT】训练类型可选用【full-4k, full-8k】实验类型;VeRL实验类型为【grpo】。
- <output_file_path>:yaml文件输出目录及文件名称,例如/path/to/xxx.yaml。
- <${AscendFactory_dir}> : 代码目录路径。
- 基础镜像
步骤二:配置数据输入和输出【OBS方式】
此小节根据实际选择训练框架不同,设置输入、输出参数不同,根据实际选择,该小节仅为使用OBS桶存储所需,如使用SFS Turbo共享盘忽略此小节。
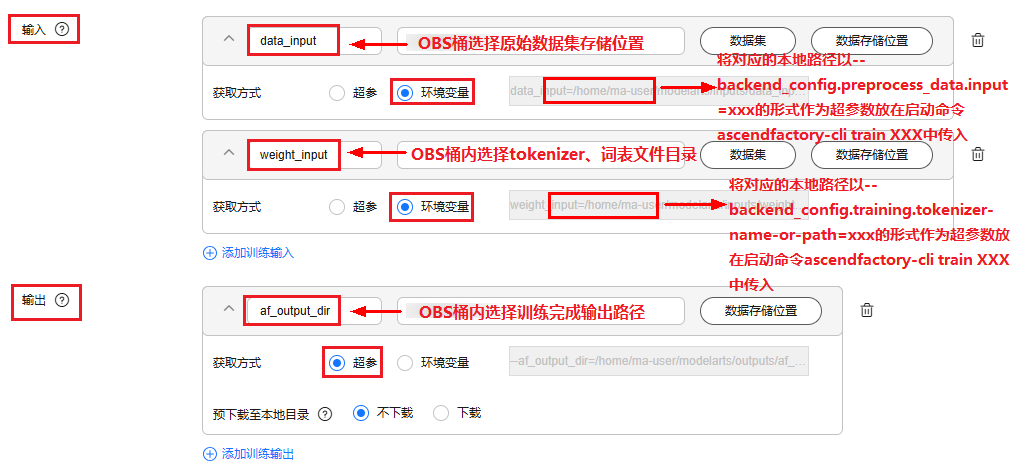
- 单击“增加训练输入”和“增加训练输出”,用于配置训练作业开始时需要输入数据的路径和训练结束后输出数据的路径。
图2 增加训练输入输出

- 在“输入”框内选择环境变量,选择训练框架不同填入不同参数,根据实际选择填入超参。
- MindSpeed-LLM
- 输入数据集参数:是否使用已处理好数据集;
- 是,将对应的本地路径以--backend_config.training.data-path=xxx的形式作为超参数放在启动命令ascendfactory-cli train XXX中传入
- 否,使用原始数据集,将对应的本地路径以--backend_config.preprocess_data.input=xxx的形式作为超参数放在启动命令ascendfactory-cli train XXX中传入
- 输入权重词表超参(tokenizer):将对应的本地路径以--backend_config.training.tokenizer-name-or-path=xxx的形式作为超参数放在启动命令ascendfactory-cli train XXX中传入
- 是否使用已转换Megatron格式权重或训练输出结果权重目录;
- 是,将对应的本地路径以--backend_config.training.load=xxx(已转换Megatron格式权重目录或训练输出结果权重目录)的形式作为超参数放在启动命令ascendfactory-cli train XXX中传入
- 否,使用原始huggingface权重,忽略此步骤
- 输入数据集参数:是否使用已处理好数据集;
- Llama-Factory
- 输入数据集参数:将训练时指定的输入数据集路径以--backend_config.dataset_dir=xxx的形式作为超参数放在启动命令ascendfactory-cli train XXX中传入,一般只有使用自定义数据时需设置,地址为代码包AscendFactory/data目录下。
- 输入权重词表参数:将tokenizer与Hugging Face权重对应的存放地址以--backend_config.model_name_or_path=xxx的形式作为超参数放在启动命令ascendfactory-cli train XXX中传入。
- 将lora训练完成后生成的未合并的权重文件路径以--backend_config.adapter_name_or_path=xxx的形式作为超参数放在启动命令ascendfactory-cli train XXX中传入(基于lora微调后模型进行增量训练时传入)
- MindSpeed-LLM
- 在“输出”框内设置超参key,根据实际选择填入超参。
- 设置af_output_dir参数:训练完成后指定的输出模型路径
- 分别单击“输入”和“输出”的数据存储位置,选择相应OBS路径地址。
- “输出”中的预下载至本地目标选择:下载,此时输出路径中的数据则会下载至OBS中。
图3 MindSpeed-LLM设置输入、输出值样例
步骤三:配置超参和环境变量
作为超参数放在启动命令ascendfactory-cli train XXX中传入,所选训练框架不同配置参数不同,根据实际需求选择MindSpeed-LLM、Llama-Factory或VeRL表格中的配置进行填写。

如果使用MindSpeed-LLM框架则需要配置环境变量 IS_MULTI_EXEC: true
步骤四:开启训练故障自动重启功能
创建训练作业时,可开启自动重启功能。当环境问题导致训练作业异常时,系统将自动修复异常或隔离节点,并重启训练作业,提高训练成功率。为了避免丢失训练进度、浪费算力。此功能已适配断点续训练。

断点续训练是通过checkpoint机制实现。checkpoint机制是在模型训练的过程中,不断地保存训练结果(包括但不限于EPOCH、模型权重、优化器状态、调度器状态)。即便模型训练中断,也可以基于checkpoint继续训练。
当训练作业发生故障中断本次作业时,代码可自动从训练中断的位置接续训练,加载中断生成的checkpoint,中间不需要改动任何参数。MindSpeed-LLM可通过save-interval参数、Llama-Factory可通过save_steps参数,指定间隔多少step保存checkpoint。