

文档首页/
AI开发平台ModelArts/
最佳实践/
LLM大语言模型训练/
LLM大语言模型训练其它版本/
主流开源大模型基于ModelArts Standard&Lite Server适配AscendFactory PyTorch NPU训练指导(6.5.905)/
准备工作/
ModelArts Lite Server
更新时间:2025-12-15 GMT+08:00
ModelArts Lite Server
前提条件
- 已开通Lite Server资源,并确保机器已开通,密码已获取,能通过SSH登录,不同机器之间网络互通。
- (多机运行分布式训练)已购买可挂载的存储硬盘资源,以实现多机共同访问同一存储硬盘资源,存储方案请参考配置Lite Server存储;支持在裸金属服务器中挂载的有弹性文件服务SFS和云硬盘EVS。
- 安装过程需要连接互联网git clone,确保容器可以访问公网。

当容器需要提供服务给多个用户,或者多个用户共享使用该容器时,应限制容器访问Openstack的管理地址(169.254.169.254),以防止容器获取宿主机的元数据。具体操作请参见禁止容器获取宿主机元数据。
步骤一:检查环境
- SSH登录机器后,检查NPU设备状态。运行如下命令,返回NPU设备信息。
npu-smi info # 在每个实例节点上运行此命令可以看到NPU卡状态 npu-smi info -l | grep Total # 在每个实例节点上运行此命令可以看到总卡数,用来确认对应卡数已经挂载 npu-smi info -t board -i 1 | egrep -i "software|firmware" #查看驱动和固件版本
如出现错误,可能是机器上的NPU设备没有正常安装,或者NPU镜像被其他容器挂载。请先正常安装固件和驱动,或释放被挂载的NPU。
- 检查docker是否安装。
docker -v #检查docker是否安装
如尚未安装,运行以下命令安装docker。
yum install -y docker-engine.aarch64 docker-engine-selinux.noarch docker-runc.aarch64
- 配置IP转发,用于容器内的网络访问。执行以下命令查看net.ipv4.ip_forward配置项的值,如果为1,可跳过此步骤。
sysctl -p | grep net.ipv4.ip_forward
如果net.ipv4.ip_forward配置项的值不为1,执行以下命令配置IP转发。sed -i 's/net\.ipv4\.ip_forward=0/net\.ipv4\.ip_forward=1/g' /etc/sysctl.conf sysctl -p | grep net.ipv4.ip_forward
步骤二:获取基础镜像
建议使用官方提供的镜像部署训练服务。镜像地址{image_url}参见表2获取。
docker pull {image_url}
步骤三:上传代码包和权重文件
- 上传安装依赖软件训练代码AscendCloud-LLM-6.5.905-xxx.zip到主机中并解压,包获取路径请参见表1,解压详解如下:
unzip AscendCloud-*.zip && unzip ./AscendCloud/AscendCloud-LLM-*.zip
- 将权重文件上传到Lite Server机器中。权重文件的格式要求为Huggingface格式。开源权重文件获取地址请参见支持的模型列表。
- 权重要求放在磁盘的指定目录,保证模型文件、权重文件(如LFS文件)已完整下载。
- 修改权重(tokenizer)文件,以下模型需修改,根据所选框架及模型修改相应文件,详情参考tokenizer文件说明。
步骤四:制作训练镜像
进入解压后代码包目录下的Dockerfile文件同级目录,通过DockerFile文件构建训练镜像制作训练镜像。安装过程需要连接互联网git clone,请确保机器环境可以访问公网。详解操作如下:
- 进入代码包Dockerfile文件同级目录,{work_dir}指宿主机存放代码目录,根据实际修改:
cd {work_dir}/llm_train/AscendFactory - 构建新镜像:
docker build --build-arg install_type=xxx -t <镜像名称>:<版本名称> .
如无法访问公网则需配置代理,增加`--build-arg`参数指定代理地址确保访问公网。docker build --build-arg "https_proxy=http://xxx.xxx.xxx.xxx" --build-arg "http_proxy=http://xxx.xxx.xxx.xxx" --network=host --build-arg install_type=xxx -t <镜像名称>:<版本名称> .
<镜像名称>:<版本名称>:定义镜像名称。示例:pytorch_2_3_ascend:20241106
install_type:安装类型,可选mindspeed-llm、llamafactory、verl,根据实际要求选择。

步骤五:上传数据到指定目录
MindSpeed-LLM和Llama-Factory数据要求有细小差异,如Llama-Factory框架自定义数据集或下载其他数据集要求更新dataset_info.json文件;数据可参考数据说明,数据集准备具体步骤如下:
将下载的原始数据存放在{work_dir}/llm_train/AscendFactory/data目录下。具体步骤如下:
- 解压data.tgz压缩包。
tar -zxvf /home/ma-user/ws/llm_train/AscendFactory/data.tgz
- 进入到/home/ma-user/ws/llm_train/AscendFactory/data目录下。
cd /home/ma-user/ws/llm_train/AscendFactory/data
- 将原始数据或处理好的数据按照下面的数据存放目录要求放置,数据存放参考目录结构如下。
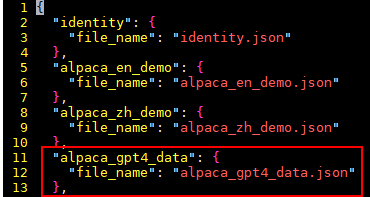
${workdir}(例如/home/ma-user/ws/llm_train ) |── AscendFactory/data |── alpaca_en_demo.json # 代码原有数据集 |── identity.json # 代码原有数据集 ... |── alpaca_gpt4_data.json # 自定义样例数据集 - 是否使用Llama-Factory框架训练。
- 是,更新代码目录下data/dataset_info.json文件。如使用以下示例数据集则命令如下。关于数据集文件格式及配置,更多样例格式信息请参考README_zh.md 的内容。
vim dataset_info.json
新加配置参数如下:
"alpaca_gpt4_data": { "file_name": "alpaca_gpt4_data.json" },样例截图:
- 否,数据准备结束。
- 是,更新代码目录下data/dataset_info.json文件。如使用以下示例数据集则命令如下。关于数据集文件格式及配置,更多样例格式信息请参考README_zh.md 的内容。
多机情况下,只有在rank_0节点进行数据预处理,转换权重等工作,所以原始数据集和原始权重,包括保存结果路径,都应该在共享目录下。
步骤六:启动容器镜像
- 启动容器镜像前请先按照参数说明修改${}中的参数,可以根据实际需要增加修改参数,启动容器命令如下,Snt9B环境为例:
export work_dir="自定义挂载的工作目录" #容器内挂载的目录,例如/home/ma-user/ws export container_work_dir="自定义挂载到容器内的工作目录" export container_name="自定义容器名称" export image_name="镜像名称" docker run -itd \ --device=/dev/davinci_manager \ --device=/dev/devmm_svm \ --device=/dev/hisi_hdc \ -v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \ -v /usr/local/dcmi:/usr/local/dcmi \ -v /usr/local/Ascend/driver:/usr/local/Ascend/driver \ --cpus 192 \ --memory 1000g \ --shm-size 1024g \ --net=host \ -v ${work_dir}:${container_work_dir} \ --name ${container_name} \ $image_name \ /bin/bash
参数说明:
- --name ${container_name} 容器名称,进入容器时会用到,此处可以自己定义一个容器名称,例如ascendspeed。
- -v ${work_dir}:${container_work_dir} 代表需要在容器中挂载宿主机的目录。宿主机和容器使用不同的文件系统。work_dir为宿主机中工作目录,目录下存放着训练所需代码、数据等文件。container_work_dir为要挂载到的容器中的目录。为方便两个地址可以相同。
- 容器不能挂载/home/ma-user目录,此目录为ma-user用户家目录。
- driver及npu-smi需同时挂载至容器。
- 不要将多个容器绑到同一个NPU上,会导致后续的容器无法正常使用NPU功能。
- ${image_name} 为docker镜像的ID,在宿主机上可通过docker images查询得到。
- --shm-size:表示共享内存,用于多进程间通信。由于需要转换较大内存的模型文件,因此大小要求1024g及以上。
- --cpus:宿主机的 CPU 核心数,一般Snt9B机型设置为192,Snt9B23机型设置为320。
- --e ASCEND_VISIBLE_DEVICES=0-7 :设置卡号ID,一般Snt9B机型设置0-7,Snt9B23机型设置为0-15。
- --memory:一般Snt9B机型设置为1024g,Snt9B23机型设置为2048g
- 通过容器名称进入容器中。启动容器时默认用户为ma-user用户。
docker exec -it ${container_name} bash
父主题: 准备工作




