

文档首页/ 魔坊(ModelArts)模型训推平台/ 最佳实践/ LLM大语言模型推理/ 主流开源大模型基于轻量算力节点适配Ascend-vLLM框架NPU推理指导(6.5.907)/ 推理服务部署/ 准备推理环境
更新时间:2026-07-04 GMT+08:00
准备推理环境
前提条件
- 准备一台Linux服务器用于构建镜像。
- 安装过程需要连接互联网git clone,确保容器可以访问公网。
步骤一:检查环境
- SSH登录机器后,检查NPU设备状态。运行如下命令,返回NPU设备信息。
npu-smi info # 在每个实例节点上运行此命令可以看到NPU卡状态 npu-smi info -l | grep Total # 在每个实例节点上运行此命令可以看到总卡数,用来确认对应卡数已经挂载 npu-smi info -t board -i 1 | egrep -i "software|firmware" #查看驱动和固件版本
如出现错误,可能是机器上的NPU设备没有正常安装,或者NPU镜像被其他容器挂载。请先正常安装驱动和固件,或释放被挂载的NPU。
驱动版本要求如表1。如果不符合要求请参考安装驱动和固件章节升级驱动。
表1 HDK固件驱动 NPU
HDK 固件&驱动
Snt9b23(标准版本)
25.2.1
Snt9b(标准版本)
24.1.0.6
- 检查docker是否安装。
docker -v #检查docker是否安装
如尚未安装,运行以下命令安装docker。
yum install -y docker-engine.aarch64 docker-engine-selinux.noarch docker-runc.aarch64
步骤三:上传代码包和权重文件
步骤四:制作推理镜像
按照以下脚本执行解压操作,请保证环境联网,并支持git clone。
# 移动软件包上传目录(该目录下除了软件包不能有其他内容),依次执行解压,构建生产镜像
unzip AscendCloud-*.zip -d AscendCloud && cd AscendCloud \
&& unzip AscendCloud-OPP-*.zip && unzip AscendCloud-OPP-*-torch-*-py*.zip -d ./AscendCloud-OPP \
&& unzip AscendCloud-LLM*.zip -d ./AscendCloud-LLM \
&& cp AscendCloud-LLM/llm_inference/ascend_vllm/Dockerfile . \
&& docker build -t ${image} --build-arg BASE_IMAGE=$base_image . 参数说明:
- ${base_image}:为基础镜像名称,即{image_url},取值来源于表2。
- $image:为制作完成的镜像名称,名字可自定义,需要满足镜像命名规则 image_name:image_tag。 例如:
pytorch_ascend:pytorch_2.5.1-cann_8.1.rc2-py_3.11-hce_2.0.2503-aarch64-snt9b23
运行完后,会生成推理所需镜像。执行docker images可以找到生成的镜像。
步骤五:启动容器
启动容器镜像前请先按照参数说明修改${}中的参数。docker启动失败会有对应的error提示,启动成功会有对应的docker id生成,并且不会报错。
docker run -itd \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
-v /etc/localtime:/etc/localtime \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /etc/ascend_install.info:/etc/ascend_install.info \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /var/log/npu/:/usr/slog \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /sys/fs/cgroup:/sys/fs/cgroup:ro \
-v ${dir}:${container_model_path} \
--net=host \
--name ${container_name} \
${image_id} \
/bin/bash 参数说明:
- --device=/dev/davinci0,..., --device=/dev/davinci7:挂载NPU设备。示例中是Snt9b机型,挂载了8张卡davinci0~davinci7。Snt9b23机型设置为--device=/dev/davinci0,..., --device=/dev/davinci15。
- -v ${dir}:${container_model_path} 表示将宿主机上模型权重目录挂载到容器中模型权重目录。

- 容器不能挂载到/home/ma-user目录,此目录为ma-user用户家目录。如果容器挂载到/home/ma-user下,拉起容器时会与基础镜像冲突,导致基础镜像不可用。
- driver及npu-smi需同时挂载至容器。
- 不要将多个容器绑到同一个NPU上,会导致后续的容器无法正常使用NPU功能。
- --name ${container_name}:容器名称,进入容器时会用到,此处可以自己定义一个容器名称。
- {image_id} 为docker镜像的ID,即步骤四:制作推理镜像中生成的新镜像id,在宿主机上可通过docker images查询得到。
步骤六:进入容器
- 进入容器。
docker exec -it -u ma-user ${container_name} /bin/bash执行以下命令,确保ma-user用户有权限操作容器中${container_model_path} 路径下的所有文件。${container_model_path} 参数取值和步骤五:启动容器保持一致。
sudo chown -R ma-user:ma-group ${container_model_path} - 评估推理资源。在容器中运行如下命令,返回NPU设备信息可用的卡数。
npu-smi info # 启动推理服务之前检查卡是否被占用、端口是否被占用,是否有对应运行的进程
如出现错误,可能是机器上的NPU设备没有正常安装,或者NPU镜像被其他容器挂载。请先正常安装驱动固件,或释放被挂载的NPU。
如果不符合要求请参考安装驱动和固件章节升级驱动。启动后容器默认端口是8080。
- 配置需要使用的NPU卡为容器中的第几张卡。例如:实际使用的是容器中第1张卡,此处填写“0”。
export ASCEND_RT_VISIBLE_DEVICES=0
如果启动服务需要使用多张卡,则按容器中的卡号依次编排。例如:实际使用的是容器中第1张和第2张卡,此处填写为“0,1”,以此类推。
export ASCEND_RT_VISIBLE_DEVICES=0,1
可以通过命令npu-smi info查询NPU卡为容器中的第几张卡。例如下图查询出两张卡,如果希望使用第一和第二张卡,则“export ASCEND_RT_VISIBLE_DEVICES=0,1”,注意编号不是填4、5。图1 查询结果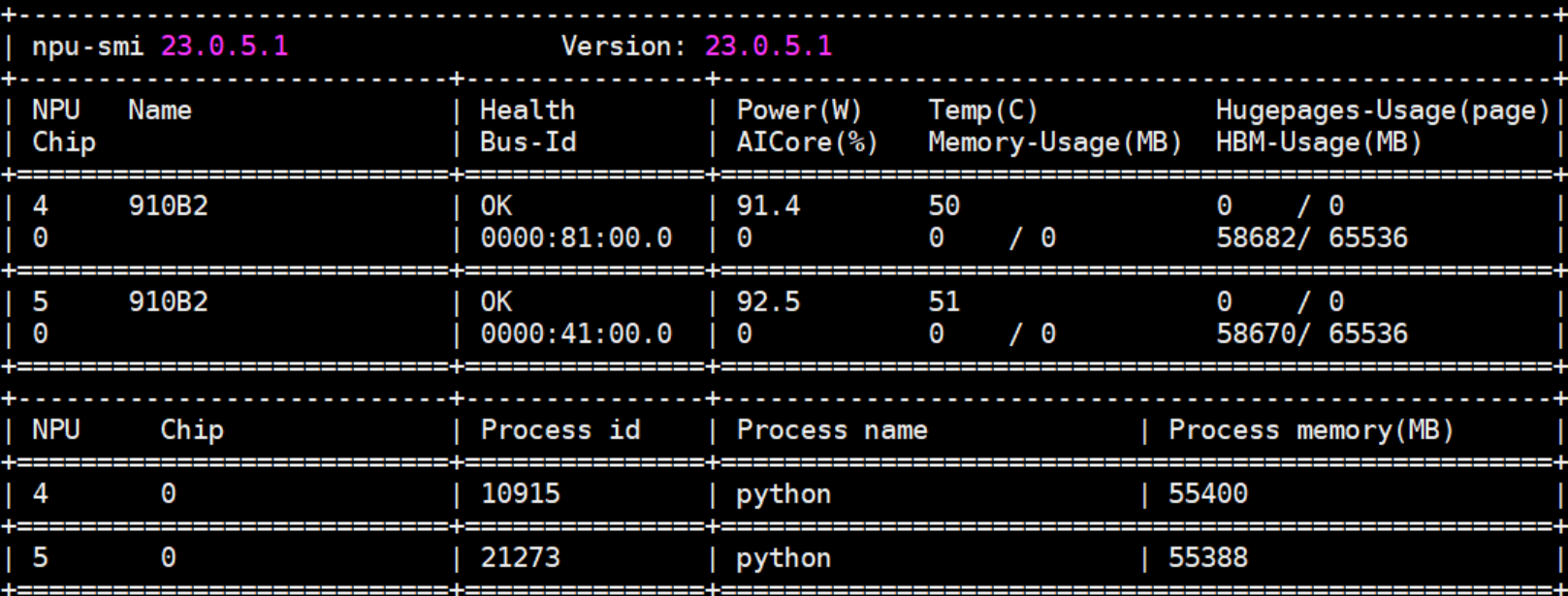
启动推理服务的具体操作步骤请参见启动推理服务(大语言模型)。
父主题: 推理服务部署




