

启动推理服务(多模态模型)
什么是多模态
多模态(Multimodality)是集成和处理两种或两种以上不同类型的信息或数据的方法和技术。具体来说,在机器学习和人工智能领域,多模态涉及的数据类型通常包括但不限于文本、图像、视频、音频和传感器数据。
多模态的主要目标是利用来自多种模态的信息来提升任务的表现力,提供更丰富的用户体验,或是获取更全面的数据分析结果。例如,在实际应用场景中,可以通过结合图像和文本信息来进行更好的对象识别或情感分析。
此外,多模态还可以细分为以下几个方面:
- 多模态理解:如何让计算机从不同种类的数据源中抽取有用的信息,并将其综合起来形成有意义的知识。
- 视觉大模型:这类模型专门针对图像和其他视觉数据设计,帮助计算机更好地理解和解释视觉世界。
- 多模态检索:这是指利用多种数据模态(如文本、图像、视频、音频等)进行信息检索的技术,旨在通过整合不同形式的数据,提供更精准的结果。
综上所述,多模态不仅仅是简单的特征融合,而是涵盖了广泛的理论基础及实践应用。这里的多模态是指多模态理解。
约束限制
机器以及最大卡数见各模型支持的最小卡数和最大序列。

离线推理
使用如下脚本https://github.com/vllm-project/vllm/blob/v0.7.2/examples/offline_inference/vision_language.py进行多模态离线推理
- 找到对应系列模型的入口函数,修改模型权重位置,例如qwen2.5-vl,将下图红框修改为模型权重位置:
图1 修改模型权重位置

- 修改模型参数,在对应系列模型的入口函数中的LLM中设置参数。
- model:模型地址,模型格式是huggingface的目录格式
- max_num_seqs:最大同时处理的请求数
- max_model_len:推理时最大输入+最大输出tokens数量,输入超过该数量会直接返回
- max_num_batched_tokens:prefill阶段,最多会使用多少token,必须大于或等于--max-model-len,推荐使用4096或8192
- dtype:模型推理的数据类型
- tensor_parallel_size:模型并行数(即使用几卡)
- block_size:PagedAttention的block大小,推荐设置为128
- gpu_memory_utilization:NPU使用的显存比例,复用原vLLM的入参名称,默认为0.9
- trust_remote_code:是否相信远程代码
- distributed_executor_backend="ray":使用ray通信
- 修改模型参数,在SamplingParams中设置参数。
图2 在SamplingParams中设置参数

表1 参数说明 参数
是否必选
默认值
参数类型
描述
max_tokens
否
16
Int
每个输出序列要生成的最大tokens数量。
top_k
否
-1
Int
控制要考虑的前几个tokens的数量的整数。设置为-1表示考虑所有tokens。适当降低该值可以减少采样时间。
top_p
否
1.0
Float
控制要考虑的前几个tokens的累积概率的浮点数。必须在 (0, 1] 范围内。设置为1表示考虑所有tokens。
temperature
否
1.0
Float
控制采样的随机性的浮点数。较低的值使模型更加确定性,较高的值使模型更加随机。0表示贪婪采样。
stream
否
False
Bool
是否开启流式推理。默认为False,表示不开启流式推理。
ignore_eos
否
False
Bool
ignore_eos表示是否忽略EOS并且继续生成token。
repetition_penalty
否
1.0
Float
减少重复生成文本的概率。
stop_token_ids
否
None
Int
停止tokens列表。Internvl2.5需要传入,参考离线推理脚本examples/offline_inference_vision_language.py的stop_token_ids。
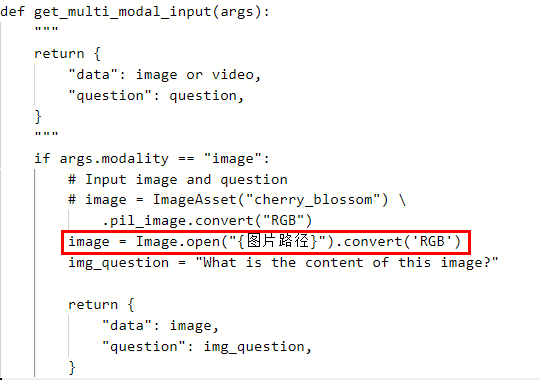
- 指定图片路径。指定本地图片路径需在文件开头增加代码from PIL import Image,在get_multi_modal_input函数中新增如下代码image = Image.open("{图片路径}").convert('RGB')。
图3 指定图片路径
- 指定输入文本。
图4 指定输入文本

- 启动推理脚本
python vision_language.py --model-type qwen2_5_vl
脚本运行参数说明:
--model-type:模型类型,目前可选参数为internvl_chat、qwen2_5_vl。
--num-prompts:单次运行输入的prompt的数量,默认为4。
--modality:输入类型,目前可选参数为image、video,默认为image。
--num-frames:从视频中提取的帧数,默认为16。
在线推理
export VLLM_IMAGE_FETCH_TIMEOUT=100
export VLLM_ENGINE_ITERATION_TIMEOUT_S=600
# PYTORCH_NPU_ALLOC_CONF优先设置为expandable_segments:True
# 如果有涉及虚拟显存相关的报错,可设置为expandable_segments:False
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
python -m vllm.entrypoints.openai.api_server --model ${container_model_path} \
--max-num-seqs=256 \
--max-model-len=4096 \
--max-num-batched-tokens=4096 \
--tensor-parallel-size=1 \
--block-size=128 \
--chat-template ${chat_template_path} \
--dtype ${dtype} \
--host=${docker_ip} \
--port=${port} \
--gpu-memory-utilization=0.9 \
--trust-remote-code
多模态推理服务启动模板参数说明如下,其余参数设置参考启动推理服务(大语言模型)基础参数说明。
- VLLM_IMAGE_FETCH_TIMEOUT:图片下载时间环境变量。
- VLLM_ENGINE_ITERATION_TIMEOUT_S:服务间隔最大时长,超过会报timeout错误。
- PYTORCH_NPU_ALLOC_CONF=expandable_segments:True;允许分配器最初创建一个段,然后在以后需要更多内存时扩展它的大小。开启时可能提升模型性能。报错则关闭。
- --model ${container_model_path}:模型地址,模型格式是HuggingFace的目录格式。即上传的HuggingFace权重文件存放目录。如果使用的是训练后模型转换为HuggingFace格式的地址,还需要有Tokenizer原始文件。
- --max-num-seqs:最大同时处理的请求数,超过后在等待池等候处理。
- --max-model-len:推理时最大输入+最大输出tokens数量,输入超过该数量会直接返回。max-model-len的值必须小于config.json文件中的"seq_length"的值,否则推理预测会报错。config.json存在模型对应的路径下,例如:${container_work_dir}/chatglm3-6b/config.json。不同模型推理支持的max-model-len长度不同,具体差异请参见表1。
- --max-num-batched-tokens:prefill阶段,最多会使用多少token,必须大于或等于--max-model-len,推荐使用4096或8192。
- --dtype:模型推理的数据类型。支持FP16和BF16数据类型推理。float16表示FP16,bfloat16表示BF16。如果不指定,则根据输入数据自动匹配数据类型。使用不同的dtype会影响模型精度。如果使用开源权重,建议不指定dtype,使用开源权重默认的dtype。
- --tensor-parallel-size:模型并行数。模型并行与流水线并行的乘积取值需要和启动的NPU卡数保持一致,可以参考表1。此处举例为1,表示使用单卡启动服务。
- --block-size:kv-cache的block大小,推荐设置为128。
- --host=${docker_ip}:服务部署的IP,${docker_ip}替换为宿主机实际的IP地址,默认为None,举例:参数可以设置为0.0.0.0。
- --port:服务部署的端口。
- --gpu-memory-utilization:NPU使用的显存比例,复用原vLLM的入参名称,默认为0.9。
- --trust-remote-code:是否相信远程代码。
- --chat-template:对话构建模板,可选参数。如:llava chat-template:${vllm_path}/examples/template_llava.jinja
多模态推理请求
通过online_serving.py方式发送请求(单图单轮对话)
由于多模态推理涉及图片的编解码,所以采用脚本方式调用服务API。脚本中需要配置的参数如表1 脚本参数说明所示。
import base64
import requests
import argparse
import json
from typing import List
# Function to encode the image
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def get_stop_token_ids(model_path):
with open(f"{model_path}/config.json") as file:
data = json.load(file)
if data.get('architectures')[0] == "InternVLChatModel":
return [0, 92543, 92542]
return None
def post_img(args):
# Path to your image
image_path = args.image_path
# Getting the base64 string
image_base64 = encode_image(image_path)
stop_token_ids = args.stop_token_ids if args.stop_token_ids is not None else get_stop_token_ids(args.model_path)
headers = {
"Content-Type": "application/json"
}
payload = {
"model": args.model_path,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": args.text
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{image_base64}"
}
}
]
}
],
"max_tokens": args.max_tokens,
"temperature": args.temperature,
"ignore_eos": args.ignore_eos,
"stream": args.stream,
"top_k": args.top_k,
"top_p": args.top_p,
"stop_token_ids": stop_token_ids,
"repetition_penalty": args.repetition_penalty,
}
response = requests.post(f"http://{args.docker_ip}:{args.served_port}/v1/chat/completions", headers=headers, json=payload)
print(response.json())
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# 必填
parser.add_argument("--model-path", type=str, required=True)
parser.add_argument("--image-path", type=str, required=True)
parser.add_argument("--docker-ip", type=str, required=True)
parser.add_argument("--served-port", type=str, required=True)
parser.add_argument("--text", type=str, required=True)
# 选填
parser.add_argument("--temperature", type=float, default=0) # 输出结果的随机性。可选
parser.add_argument("--ignore-eos", type=bool, default=False) # 在生成过程中是否忽略结束符号,在生成EOS token后继续生成token。可选
parser.add_argument("--top-k", type=int, default=-1) # 参数控制着生成结果的多样性。其值越小,生成的文本就越独特,但可能缺乏连贯性。相反,其值越大,文本就越连贯,但多样性也会降低。可选
parser.add_argument("--top-p", type=int, default=1.0) # 参数的取值范围为0到1。值越小,生成的内容就越意外,但可能牺牲连贯性。值越大,内容就越连贯,但意外性也会减弱。可选
parser.add_argument("--stream", type=int, default=False) # 是否开启流式推理。默认为False,表示不开启流式推理。
parser.add_argument("--max-tokens", type=int, default=16) # 生成序列的最大长度。必选
parser.add_argument("--repetition-penalty", type=float, default=1.0) # 减少重复生成文本的概率。可选
parser.add_argument("--stop-token-ids", nargs='+', type=int, default=None) # 停止tokens列表。可选
args = parser.parse_args()
post_img(args)
python online_serving.py --model-path ${container_model_path} --image-path ${image_path} --docker-ip ${docker_ip} --served-port ${port} --text 图片内容是什么
相关请求参数说明参照多模态相关请求参数说明。

推理输出结果如下图所示。

多模态相关请求参数说明
|
参数 |
是否必须 |
参数类型 |
描述 |
|---|---|---|---|
|
container_model_path |
是 |
str |
模型权重路径 |
|
image_path |
是 |
str |
传给模型的图片路径 |
|
payload |
是 |
json |
单图单轮对话的post请求json, 可参考表3 请求服务json参数说明 |
|
docker_ip |
是 |
str |
启动多模态openAI服务的主机ip |
|
served_port |
是 |
str |
启动多模态openAI服务的端口号 |
|
参数 |
是否必须 |
默认值 |
参数类型 |
描述 |
|---|---|---|---|---|
|
model |
是 |
无 |
Str |
通过OpenAI服务API接口启动服务时,推理请求必须填写此参数。取值必须和启动推理服务时的model ${container_model_path}参数保持一致。 |
|
messages |
是 |
- |
Dict |
请求输入的问题和图片。 role表示消息的发送者,这里只能为用户。content表示消息的内容,类型为list。 单图单轮对话content必须包含两个元素,第一个元素type字段取值为text,表示文本类型, text字段取值为输入问题的字符串。 第二个元素type字段取值为image_url, 表示图片类型,image_url字段取值为是输入图片的base64编码。 |
|
max_tokens |
否 |
16 |
Int |
每个输出序列要生成的最大tokens数量。 |
|
top_k |
否 |
-1 |
Int |
控制要考虑的前几个tokens的数量的整数。设置为-1表示考虑所有tokens。适当降低该值可以减少采样时间。 |
|
top_p |
否 |
1.0 |
Float |
控制要考虑的前几个tokens的累积概率的浮点数。必须在 (0,1] 范围内。设置为1表示考虑所有tokens。 |
|
temperature |
否 |
1.0 |
Float |
控制采样的随机性的浮点数。较低的值使模型更加确定性,较高的值使模型更加随机。0表示贪婪采样。 |
|
stream |
否 |
False |
Bool |
是否开启流式推理。默认为False,表示不开启流式推理。 |
|
ignore_eos |
否 |
False |
Bool |
ignore_eos表示是否忽略EOS并且继续生成token。 |
|
repetition_penalty |
否 |
1.0 |
Float |
减少重复生成文本的概率。 |
|
stop_token_ids |
否 |
None |
Int |
停止tokens列表。internvl2和minicpmv需要传入,参考离线推理脚本examples/offline_inference_vision_language.py的stop_token_ids。 |




