InternVL2基于DevServer适配PyTorch NPU训练微调指导(6.3.908)
方案概览
本方案介绍了在ModelArts Lite DevServer上使用昇腾计算资源Ascend Snt9B开展InternVL2模型的训练过程,包括Finetune训练、LoRA训练。
约束限制
- 本方案目前仅适用于企业客户。
- 本文档适配昇腾云ModelArts 6.3.908版本,请参考获取配套版本的软件包和镜像,请严格遵照版本配套关系使用本文档。
- 确保容器可以访问公网。
资源规格要求
推荐使用“西南-贵阳一”Region上的DevServer资源和Ascend Snt9B。
获取软件和镜像
|
分类 |
名称 |
获取路径 |
|---|---|---|
|
插件代码包 |
AscendCloud-6.3.908软件包中的AscendCloud-AIGC-6.3.908-xxx.zip 文件名中的xxx表示具体的时间戳,以包名发布的实际时间为准。 |
获取路径:Support-E
说明:
如果上述软件获取路径打开后未显示相应的软件信息,说明您没有下载权限,请联系您所在企业的华为方技术支持下载获取。 |
|
基础镜像包 |
swr.cn-southwest-2.myhuaweicloud.com/atelier/pytorch_2_1_ascend:pytorch_2.1.0-cann_8.0.rc3-py_3.9-hce_2.0.2312-aarch64-snt9b-20240824153350-cebb080 |
SWR上拉取。 |
|
模型 |
版本 |
|---|---|
|
CANN |
cann_8.0.rc3 |
|
驱动 |
23.0.6 |
|
PyTorch |
2.1.0 |
Step1 检查环境
- 请参考DevServer资源开通,购买DevServer资源,并确保机器已开通,密码已获取,能通过SSH登录,不同机器之间网络互通。

购买DevServer资源时如果无可选资源规格,需要联系华为云技术支持申请开通。
当容器需要提供服务给多个用户,或者多个用户共享使用该容器时,应限制容器访问Openstack的管理地址(169.254.169.254),以防止容器获取宿主机的元数据。具体操作请参见禁止容器获取宿主机元数据。
- SSH登录机器后,检查NPU卡状态。运行如下命令,返回NPU设备信息。
npu-smi info # 在每个实例节点上运行此命令可以看到NPU卡状态 npu-smi info -l | grep Total # 在每个实例节点上运行此命令可以看到总卡数
如出现错误,可能是机器上的NPU设备没有正常安装,或者NPU镜像被其他容器挂载。请先正常安装固件和驱动,或释放被挂载的NPU。
- 检查是否安装docker。
docker -v #检查docker是否安装
如尚未安装,运行以下命令安装docker。
yum install -y docker-engine.aarch64 docker-engine-selinux.noarch docker-runc.aarch64
- 配置IP转发,用于容器内的网络访问。执行以下命令查看net.ipv4.ip_forward配置项的值,如果为1,可跳过此步骤。
sysctl -p | grep net.ipv4.ip_forward
如果net.ipv4.ip_forward配置项的值不为1,执行以下命令配置IP转发。sed -i 's/net\.ipv4\.ip_forward=0/net\.ipv4\.ip_forward=1/g' /etc/sysctl.conf sysctl -p | grep net.ipv4.ip_forward
Step2 获取基础镜像
建议使用官方提供的镜像部署推理服务。镜像地址{image_url}获取请参见表1。
docker pull {image_url}
Step3 启动容器镜像
启动容器镜像,启动前可以根据实际需要增加修改参数。
docker run -itd --net=host \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
--shm-size=1024g \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /var/log/npu/:/usr/slog \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v ${work_dir}:${container_work_dir} \
--name ${container_name} \${image_id} \
/bin/bash
- --device=/dev/davinciX 挂载NPU设备,示例中挂载了1张卡
- work_dir:工作目录,目录下存放着训练所需代码、数据等文件
- container_work_dir: 容器工作目录,一般同work_dir
- container_name:自定义容器名
- image_id:镜像ID,通过docker images来查看拉取的镜像ID。
Step4 进入容器
通过容器名称进入容器中。默认使用ma-user用户执行后续命令。
docker exec -it ${container_name} bash
修改权限
sudo chown -R ma-user:ma-group ${container_work_dir}
此步骤可能需要密码或root权限
Step5 下载代码安装环境
下载华为侧插件代码包AscendCloud-AIGC-6.3.908-xxx.zip文件,获取路径参见表1。
unzip AscendCloud-AIGC-6.3.908-xxx.zip
cd multimodal_algorithm/InternVL2/train/5d8f485ad09b3eb9b2a7d9a24cca727fa58bb775
bash InternVL2_install.sh
mv InternVL ${container_work_dir}
Step6 下载数据集
先创建文件夹用来存放数据集,再下载数据集。
cd ${container_work_dir}/InternVL/internvl_chat
mkdir -p data/coco && cd data/coco
# Download COCO images
wget http://images.cocodataset.org/zips/train2014.zip && unzip train2014.zip
wget http://images.cocodataset.org/zips/val2014.zip && unzip val2014.zip
wget http://images.cocodataset.org/zips/test2015.zip && unzip test2015.zip
mkdir -p annotations && cd annotations/ # Download converted annotation files
wget https://github.com/OpenGVLab/InternVL/releases/download/data/coco_karpathy_test.json
wget https://github.com/OpenGVLab/InternVL/releases/download/data/coco_karpathy_test_gt.json
wget https://github.com/OpenGVLab/InternVL/releases/download/data/coco_karpathy_train_567k.zip
unzip coco_karpathy_train_567k.zip
cd ../../
Step7 下载模型权重
模型权重(可选择)InternVL2-8B, InternVL2-26B, InternVL2-40B
手动下载放置在${container_name}/InternVL/internvl_chat/pretrained路径下, pretrained目录需手动创建。
https://huggingface.co/OpenGVLab/InternVL2-8B/tree/main
Step8 开始训练
LoRA微调训练或者全参微调训练命令如下。
cd ${container_work_dir}/InternVL/internvl_chat
# 8B全参微调
GPUS=8 PER_DEVICE_BATCH_SIZE=2 sh shell/internvl2.0/2nd_finetune/internvl2_8b_internlm2_7b_dynamic_res_2nd_finetune_full.sh
# 8Blora微调
GPUS=8 PER_DEVICE_BATCH_SIZE=2 sh shell/internvl2.0/2nd_finetune/internvl2_8b_internlm2_7b_dynamic_res_2nd_finetune_lora.sh
# 26Blora微调
GPUS=8 PER_DEVICE_BATCH_SIZE=2 sh shell/internvl2.0/2nd_finetune/internvl2_26b_internlm2_20b_dynamic_res_2nd_finetune_lora.sh #
40Blora微调
GPUS=8 PER_DEVICE_BATCH_SIZE=2 sh shell/internvl2.0/2nd_finetune/internvl2_40b_hermes2_yi_34b_dynamic_res_2nd_finetune_lora.sh
训练成功如下图所示。
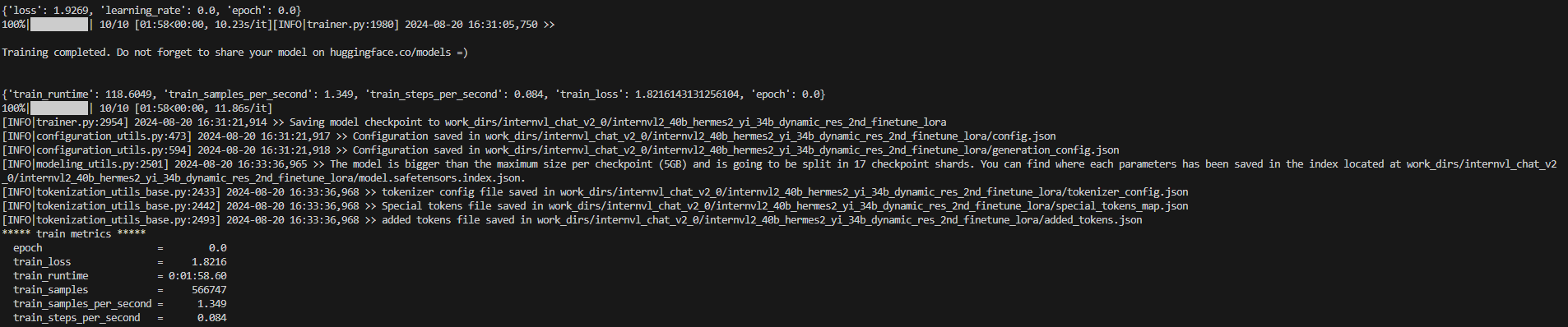
验证功能时,可以只训练10个steps,可在启动脚本中加入--max_step 10。训练启动脚本修改命令如下。
vim shell/internvl2.0/2nd_finetune/internvl2_40b_hermes2_yi_34b_dynamic_res_2nd_finetune_lora.sh