

迁移适配
本文以PyTorch框架在NPU上完成自动迁移为例,对适配过程需要修改的部分进行说明。并且针对单卡环境以及单机多卡deepspeed环境提供训练脚本。无特别说明,以ChatGLM-6B源代码根目录作为当前目录。
自动迁移适配
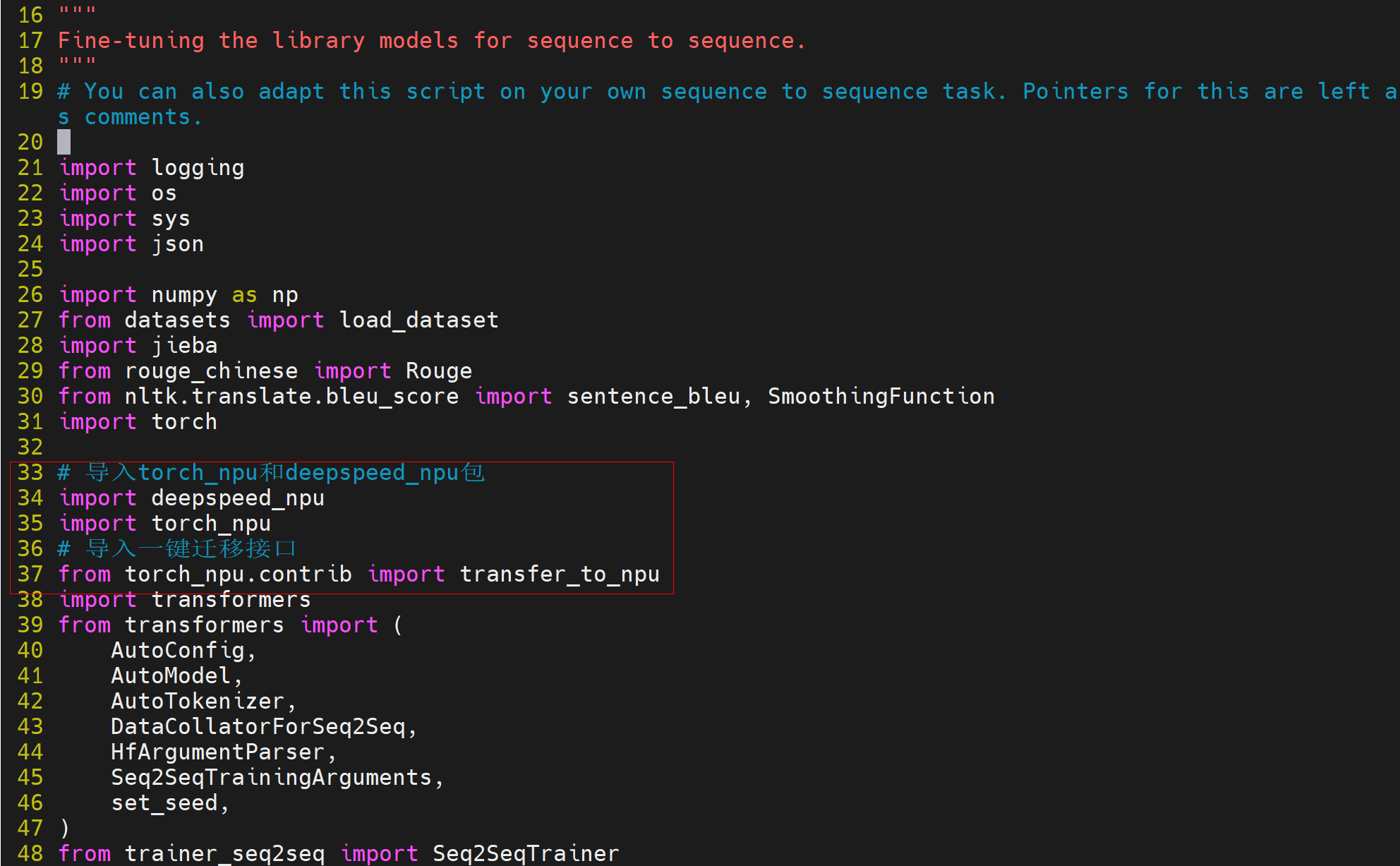
# 导入deepspeed_npu和torch_npu。 import deepspeed_npu import torch_npu # 导入一键迁移接口。 from torch_npu.contrib import transfer_to_npu
单卡方式训练
# ptuning/run_npu_1d.sh
export ASCEND_RT_VISIBLE_DEVICES=0 # 指定0号卡对当前进程可见。
PRE_SEQ_LEN=128
LR=2e-2
python3 ptuning/main.py \
--do_train \
--train_file ${HOME}/AdvertiseGen/train.json \
--validation_file ${HOME}/AdvertiseGen/dev.json \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path ${HOME}/chatglm \
--output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
--local_rank -1
通过设定ASCEND_RT_VISIBLE_DEVICES环境变量为0,控制0号卡对当前进程可见,PRE_SEQ_LEN和LR分别是soft prompt长度和训练的学习率,可以进行调节以取得最佳的效果。此外,这里去掉了int 4量化默认为FP16精度。${HOME} 目录需要根据读者实际数据集及模型路径匹配,适配的数据集是ADGEN数据集,如果您需要使用自定义的数据集训练,具体请参考使用自己数据集。另外通过指定local_rank为-1为单卡模式,多卡模式下无需指定,会默认启动DistributedDataParallel(DDP) 多卡并行模式,详情请参见常见问题1。GPU环境单卡执行同样需要指定local_rank为 -1。
多卡分布式执行
PyTorch框架下常见的多卡分布式执行主要包括DataParallel(DP) 和Distributed Data Parallel (DDP)。torch_npu环境下针对DDP场景的多卡训练有提供支持。此外,针对deepspeed环境,昇腾有专门的适配环境deepspeed-npu。在此提供一种基于deepspeed的多卡训练脚本,内容如下:
# ds_run_npu.sh
LR=1e-4
TRAIN_FILE=${HOME}/YeungNLPfirefly-train-1.1M/firefly-train-1.1M.jsonl
PER_DEVICE_TRAIN_BATCH_SIZE=4
GRADIENT_ACCUMULATION_STEPS=32
MODEL_DIR=${HOME}/chatglm
OUTPUT_DIR=${HOME}/ChatGLM-6B-main/ptuning/output
DS_CONFIG=${HOME}/ChatGLM-6B-main/ptuning/ds_config.json
APP_SCRIPT=${HOME}/ChatGLM-6B-main/ptuning/main.py
MASTER_PORT=$(shuf -n 1 -i 10000-65535)
deepspeed --num_gpus=8 --master_port $MASTER_PORT ${APP_SCRIPT} \
--deepspeed ${DS_CONFIG} \
--log_level debug \
--model_name_or_path ${MODEL_DIR} \
--train_file ${TRAIN_FILE} \
--prompt_column input \
--response_column target \
--max_source_length 512 \
--max_target_length 512 \
--output_dir ${OUTPUT_DIR}/chatglm-6b-${LR} \
--per_device_train_batch_size ${PER_DEVICE_TRAIN_BATCH_SIZE} \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps ${GRADIENT_ACCUMULATION_STEPS} \
--gradient_checkpointing False \
--num_train_epochs 1 \
--predict_with_generate \
--logging_steps 10 \
--save_strategy "steps" \
--save_total_limit 3 \
--learning_rate $LR \
--dataloader_num_workers 60 \
--preprocessing_num_workers 60 \
--do_train \
--overwrite_output_dir \
--max_steps 100 \
--fp16
LR、PER_DEVICE_TRAIN_BATCH_SIZE、GRADIENT_ACCUMULATION_STEPS分别代表学习率、单个设备训练批次大小、梯度累计步数,作为超参数可以调优获得较好模型。同样,${HOME} 需要根据数据集模型等路径做对应替换,这里脚本适配的数据集是Firefly,其中deepspeed使用了zero 1显存优化方式,配置方式如下:
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 1,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"contiguous_gradients": true,
"overlap_comm": true,
"allgather_partitions": true,
"reduce_scatter": true,
"allgather_bucket_size": 2e8,
"reduce_bucket_size": 4e8
},
"flops_profiler":{
"enabled": true,
"profile_step": 1,
"module_path": -1,
"top_modules": 1,
"detailed": false,
"output_file": null
},
"zero_allow_untested_optimizer": "true",
"gradient_clipping": "auto",
"gradient_accumulation_steps": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}





